EfficientNetV2: Smaller Models and Faster Training
原文地址:EfficientNetV2: Smaller Models and Faster Training
官方实现:google/automl
Pytorch实现:d-li14/efficientnetv2.pytorch
摘要
This paper introduces EfficientNetV2, a new family of convolutional networks that have faster training speed and better parameter efficiency than previous models. To develop this family of models, we use a combination of training-aware neural architecture search and scaling, to jointly optimize training speed and parameter efficiency. The models were searched from the search space enriched with new ops such as Fused-MBConv. Our experiments show that EfficientNetV2 models train much faster than state-of-the-art models while being up to 6.8x smaller.
Our training can be further speed up by progressively increasing the image size during training, but it often causes a drop in accuracy. To compensate for this accuracy drop, we propose to adaptively adjust regularization (e.g., dropout and data augmentation) as well, such that we can achieve both fast training and good accuracy.
With progressive learning, our EfficientNetV2 significantly outperforms previous models on ImageNet and CIFAR/Cars/Flowers datasets. By pretraining on the same ImageNet21k, our EfficientNetV2 achieves 87.3% top-1 accuracy on ImageNet ILSVRC2012, outperforming the recent ViT by 2.0% accuracy while training 5x-11x faster using the same computing resources. Code will be available at this https URL.
本文介绍了EfficientNetV2,一个新的卷积网络簇,它比以前的模型具有更快的训练速度和更高效的参数。为了开发这一系列模型,我们结合了训练感知神经架构搜索和放大策略,共同优化训练速度和模型参数。基准模型是从搜索空间中搜索得到的,这一次在搜索空间中增加了新的算子:Fused-MBconv。实验表明,EfficientNetV2模型比最先进的模型训练速度快得多,同时体积小6.8倍。
训练还可以通过在训练过程中逐渐扩大图像大小的方式来进一步加快,但这通常会导致准确率下降。为了补偿准确率下降,我们提出自适应调整正则化策略(比如,随机失活以及数据增强),这样我们可以实现快速训练和良好精度。
通过渐进式学习,EfficientNetV2在ImageNet和CIFAR/Cars/Flowers数据集上显著优于以前的模型。通过在ImageNet21k上进行预训练,EfficientNetV2在ImageNet ILSVRC2012上实现了87.3%的top-1准确率,比最近的ViT高出2.0%的准确率,在使用相同的计算资源下训练速度提高了5-11倍。代码已开源:https://github.com/google/automl/tree/master/efficientnetv2
引言
训练效率是目前的研究热点,之前已经出现了许多优化训练效率的论文,但是它们的模型往往出现极大的参数量,如图1(b)所示。
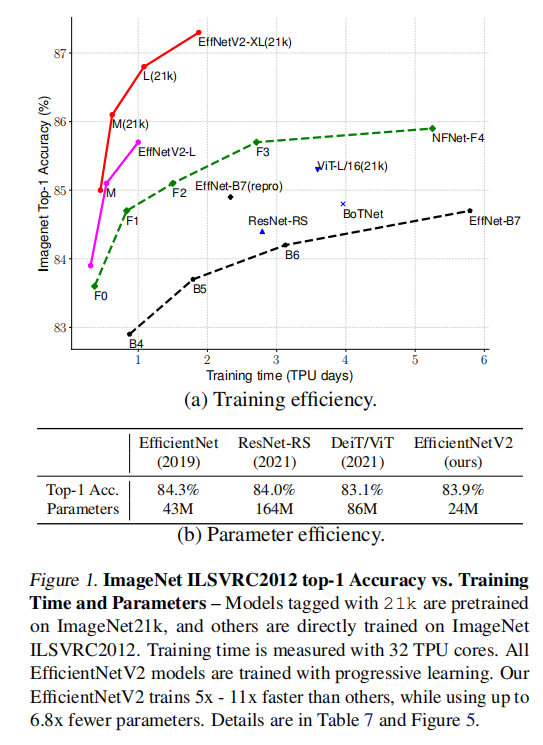
设计EfficientNetV2
本文联合训练感知神经架构搜索和复合放大策略来同步提升训练速度和参数量。
首先系统研究EfficientNets的训练瓶颈:
- 大图像输入会减慢训练速度;
- 深度卷积结构在模型早些层的训练速度很慢;
- 每个阶段放大相同系数不是最优策略。
优化方式:
- 重新设计搜索空间,增加额外算子,比如
Fused-MBConv; - 应用训练感知
NAS和放大策略共同优化模型精度、训练速度和参数量; - 应用渐进式学习算法,逐步增大图像进行训练,以此来进一步提高训练速度;
优化训练速度
之前已经有网络利用小输入图像进行训练,不过会导致精度衰减。论文分析原因在于对不同图像大小使用了相同的正则化强度:更小的输入图像会导致更小的网络容量,需要弱正则化;反之,更大的输入图像需要强正则化。
基于上述观察,论文提出渐进式学习算法:在训练早期阶段使用小图像和弱正则化强度(应用在随机失活方法或者数据增强策略上);后期逐步增加图像大小和正则化强度。
论文贡献
- 实现了
EfficientNetV2,一个更少参数量并且更快的模型簇。通过训练感知NAS和复合放大策略,EfficientNetV2同时在训练速度和参数数目上超越了之前的模型; - 提出渐进式学习方法,正则化强度基于图像大小变化进行自适应调整。这种训练方式可以加快训练速度,同时提高准确率;
- 在
ImageNet、CIFAR、Cars以及Flowers数据集上,相比于之前最好的模型,实现了11x更快的训练速度、6.8x更少的训练参数。
EfficientNetV2
EfficientNet
EfficientNet通过NAS搜索得到基准架构EfficientNet-B0,然后通过复合放大策略创建更大的模型。虽然最近提出的一些算法在训练或者推理速度上超越了EfficientNet系列,但是在参数数目和FLOPs上往往不如EfficientNet。本文提出的EfficientNetV2在保留参数效率的同时提升了训练速度。
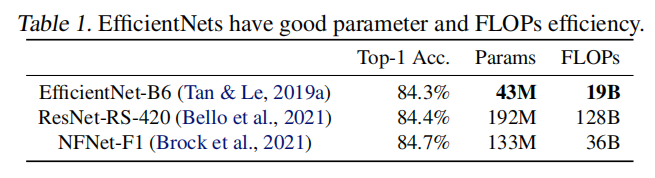
训练效率调研
论文对EfficientNet的训练瓶颈进行了调研,分析出以下几点原因。
- 如果输入图像非常大,那么训练速度会减慢
原因:大输入图像会导致显著的内存占用,而GPU/TPU的整体内存固定,所以不得不使用更小的批量大小,这样会动态减慢训练速度。
先前的解决方案:参考FixRes算法,在训练时使用比推理阶段更小的图像进行训练。
优点:更小的图像需要更少的计算量,并且允许更大的批量大小,这样可以提升训练速度至2.2倍大小, 同时能够获取得到些微更好的训练准确率(需要额外的微调训练)

论文提出了更高级的解决方案:渐进式学习。在训练过程中逐步调整图像大小和正则化强度,保证训练精度的同时提升了准确率。
- 深度卷积算子在早些层的计算是缓慢的
虽然深度卷积相比于标准卷积而言拥有更少的参数量和FLOPs,但是它无法完全利用现代加速器(论文说的)。论文使用最新提出的Fused-Conved进行替代,它可以更好的利用移动端和服务端的加速器。
Fused-Conved使用标准MBConv结构中的深度
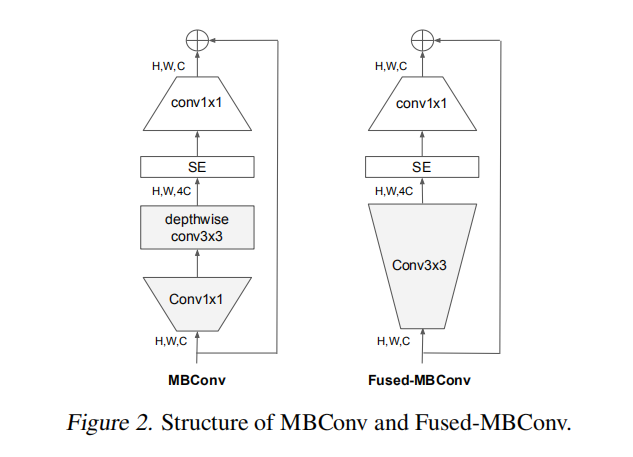
论文调研了在EfficientNet-B4中逐层替换原始MBConv模块后的性能,部分替代之后能够同时提升准确率和训练速度,但是会增加参数量和FLOPs;而完全替代会降低准确率,并且显著提升参数量和FLOPs。论文最终通过NAS搜索得到最佳Fused-Conv + MBConv组合。
- 对每个阶段进行统一缩放的性能不是最优的
在EfficientNet模型创建过程中,对每个阶段使用了同一个复合缩放规则进行放大。论文经过分析发现每个阶段的增长并不会同步作用于训练速度和参数效率。论文使用非均匀缩放策略来逐渐向后面阶段添加更多的层。
同时在EfficientNet训练中,不同大小模型会配置不同大小的输入图像。根据复合缩放规则,更大的模型需要更大的输入图像,这样会导致更大的内存占用和更慢的训练速度。论文调整了复合放大规则,同时设置了最大图像的上限。
Training-Aware NAS
本次论文进行的训练感知NAS目的在于同时优化准确率、参数效率和训练效(基于现代加速器)。首先定义搜索空间进行逐阶段搜索
- 搜索空间:卷积类型(
MBConv/Fused-MBConv)、阶段包含的层数、内核大小(3x3/5x5)、膨胀率(1/4/6) - 移除不必要的搜索选项,比如池化跳转算子(
pooling skip ops); - 复用
EfficientNet-B0搜索得到的通道大小;
这一次搜索得到的EfficientNetV2-S的参数量和FLOPs大于EfficientNet-B4,但拥有更快的推理和训练时间。其基本架构如下图所示:
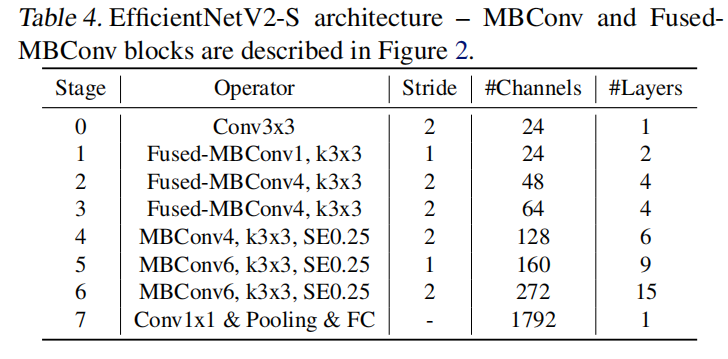
和EfficientNet-B0相比,存在以下差异:
- 在模型早些层使用了
Fused-MBConv替代MBConv; - 倾向于更小的膨胀率,这样可以减少内存访问开销;
- 更倾向于使用
卷积核。作为补偿,使用了更多层进行感受野衰减; - 完全移除了
EfficientNet中最后一个stride-1阶段。论文猜测是由于该阶段拥有大参数量和内存访问开销。
放大策略
参考EfficientNet的复合放大策略,进行如下调整:
- 限制最大图像大小为
480,因为非常大的图像会导致昂贵的内存和训练速度开销; - 逐步在后几个阶段增加层数(表
4中的第5/6阶段),这种方式可以增加网络性能但是不会增加太多的运行时开销。
共采集两个放大模型:EfficientNetV2-M/L。
训练速度比较
下图展示了相同训练配置下每批次训练速度,所有模型按固定输入大小进行训练,没有添加渐近式学习策略。
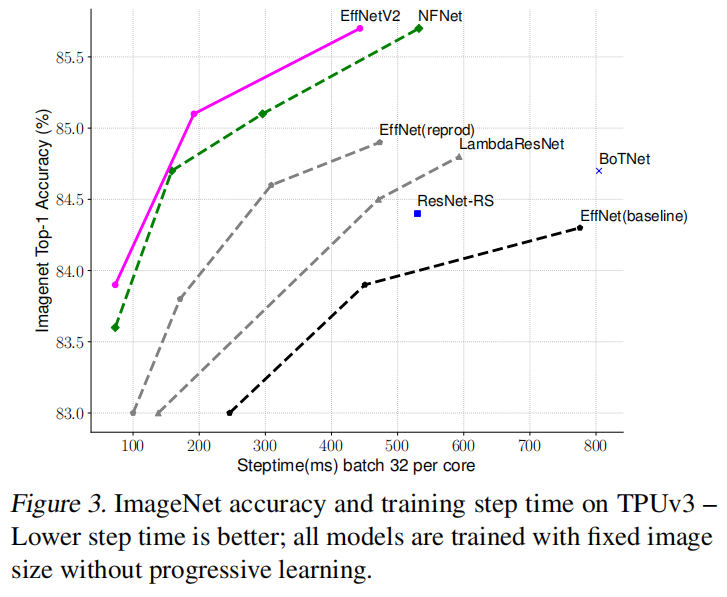
EfficientNet训练了两种不同配置图像输入:一是和推理阶段相同输入大小(baseline);二是比推理阶段小30%输入大小(其他模型也一样)。每个模型均训练350轮(除了NFNets的360轮,以保证拥有相近的训练步数)。
推理速度比较
论文比较了相近准确率下不同模型的推理延时。所有模型使用Pytorch Image Models库进行构建,在相同的机器和软/硬件上进行测试。结果如下表15所示:

渐进式学习
灵感
论文认为在训练过程中动态减少图像大小导致精度下降的原因在于不平衡的正则化(the unbalanced regularization):当训练不同图像大小的时候,应该相应的调整正则化强度。
为此论文进行了相关实验,使用不同图像大小和数据增强策略进行训练,如下图表5所示。当输入小尺寸图像,使用弱正则化策略即可实现最好准确率;当输入大尺寸图像,使用更强的正则化策略能够获取更好的准确率。

算法
渐近式学习示例如下图4所示,在训练早期阶段使用更小的输入图像和更弱的正则化强度,这样能够保证训练速度更快;然后逐步增加图像大小和正则化强度。

假定整个训练共有mixup等等。
将整个训练分为
首先会根据之前训练经验确定初始化输入大小

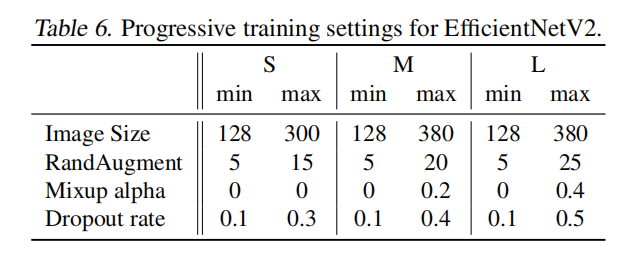
在实验过程中,论文调整了Dropout/RandAugment/Mixup这三种正则化方法,如下图所示:

设置
论文尝试了不同14所示:
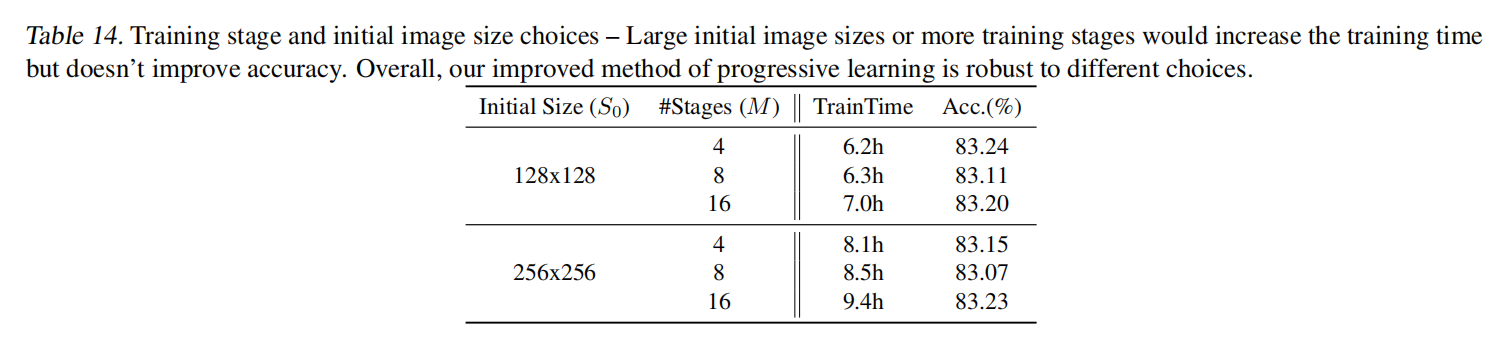
对于
- 更大的初始输入图像大小会增加训练时间(因为更大输入图像需要更多的计算资源);
- 更多的训练阶段也会些许增加训练时间。
实验
论文首先在ImageNet上进行架构搜索和参数调试,然后迁移预训练模型到CIFAR-10/CIFAR-100/Cars/Flowers。
ImageNet
ImageNet 2012
- 数据集:
ImageNet ILSVRC 2012。共1000类,包含约128万训练图像和5万验证图像; minival:在架构搜索和和参数调优阶段,从训练集中采集2.5万张图像作为小验证集;使用minival进行early stopping。- 训练设置:
- 优化器:
RMSProp,衰减0.9,动量0.9; - 批量归一化:动量
0.99; - 权重衰减:
1e-5; - 轮数:
350轮; - 批量大小:
4096(8卡); - 学习率调度:
warmup(从0到0.256)+ 随步长衰减(每2.4轮衰减0.97); - 指数移动衰减:
0.9999; - 数据增强:
RandAugment + Mixup + Dropout+ 随机深度(stochastic depth, 0.8存活率)
- 优化器:
关于渐进式学习,共分为四个阶段(每个阶段87轮),最小和最大正则化强度如下图所示。其中训练时最大输入图像仍旧有大约20%更小于推理阶段,而且完成训练后没有进行微调训练。
ImageNet 21k
- 数据集:
ImageNet 21k,共21841类,约13M训练图像。论文从中随机采样10万张作为验证集,剩余的作为训练集; - 训练设置:和
ImageNet 2012保持相同配置,调整以下步骤- 轮数:
60/30轮; - 学习率调度:余弦学习速率衰减,无需额外调整即可适应不同的阶段;
- 每张图片拥有多个标签,在计算
softmax loss之前,归一化所有标签到求和为1; - 在
ImageNet 21k预训练完成后,在ILSVRC 2012数据集上微调训练15轮,使用余弦学习率衰减。
- 轮数:
结果
训练结果,包括准确率、参数量、FLOPs、训练/推理时长如下表7和图5所示。反正就是一个字:强!!!
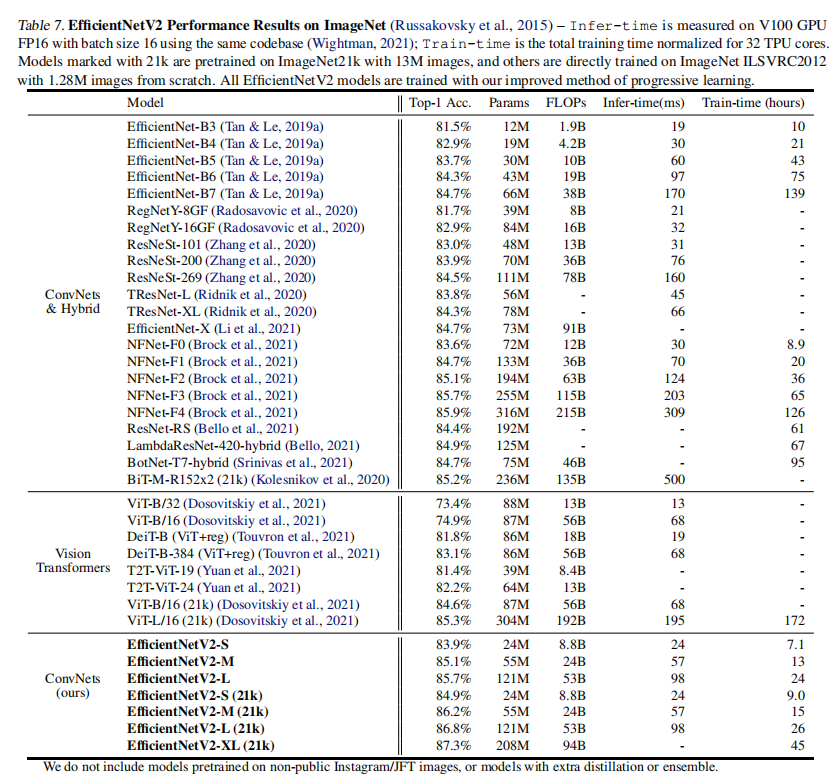
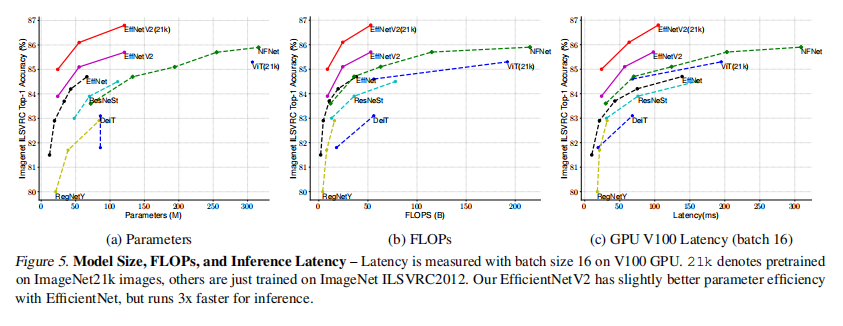
从整个训练中,论文总结出以下两条有效的训练技巧:
- 当模型准确率达到一定高度时,简单增加模型大小很难提升准确率,因为已经过拟合了。在这种情况下,放大输入图像大小比放大模型大小更有效;
- 大规模数据集预训练仍旧有助于提高模型性能。
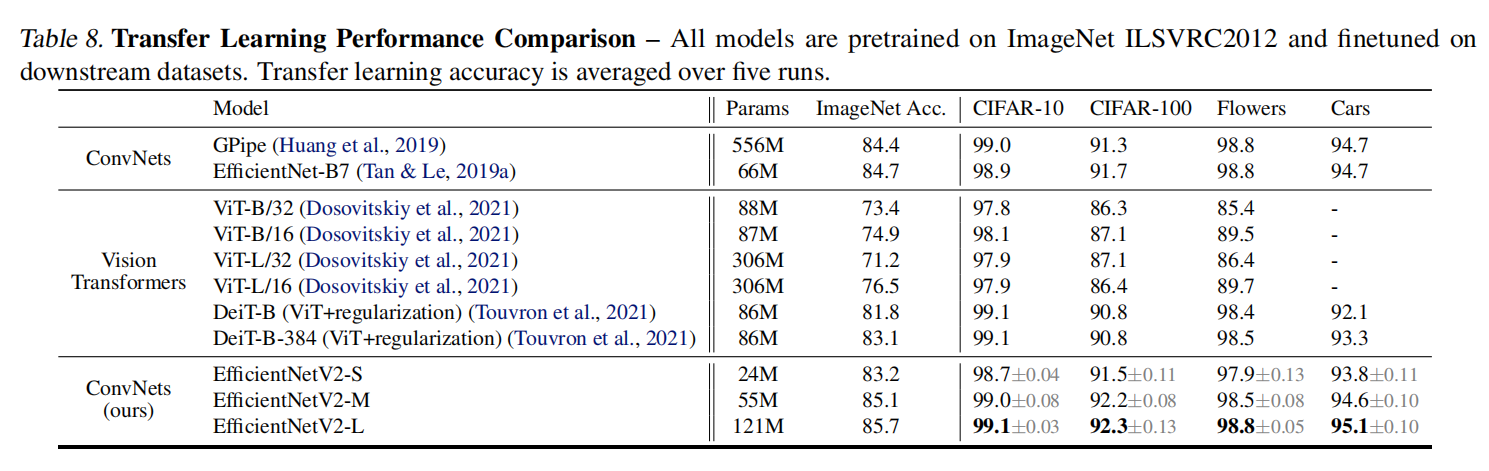
迁移学习
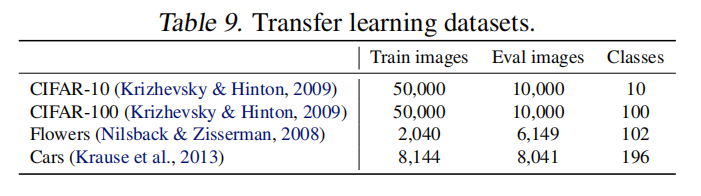
在4个小数据集上进行了迁移训练,数据集参数配置如下图所示:
微调设置如下:
- 批量大小:
512; - 初始学习率:
1e-3; - 学习率调度:余弦衰减;
- 训练步数:
10000步;
因为训练步数很少,论文禁止了权重衰减和仅使用cutout数据增强。
消融研究
和EfficientNet比较
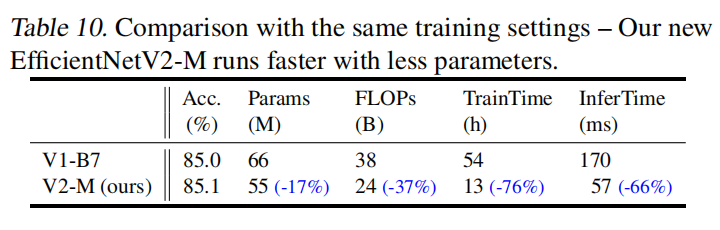
论文首先使用EfficientNetV2-M和EfficientNet-B7进行比较。进行相同配置训练情况下,两者能够得到相近准确率,但是V2-M能够大幅降低参数量、FLOPs、训练时间和推理时间。如下表所示:
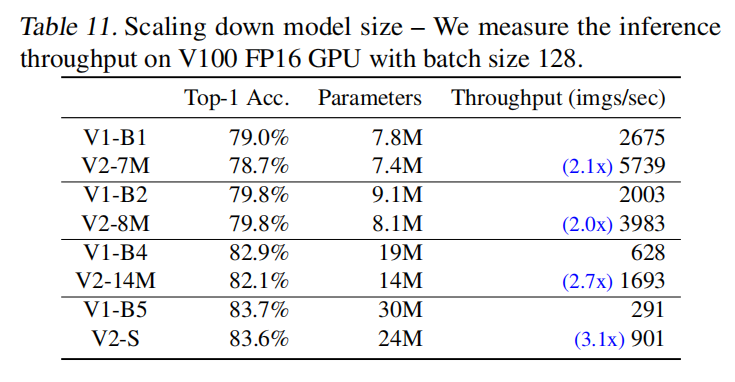
同时,论文基于复合放大策略进行反向缩小,与更小的EfficientNet模型进行比较。如下表所示,在相近的准确率下,V2模型拥有更小的参数量和更快的训练时间。
渐近式训练不同网络
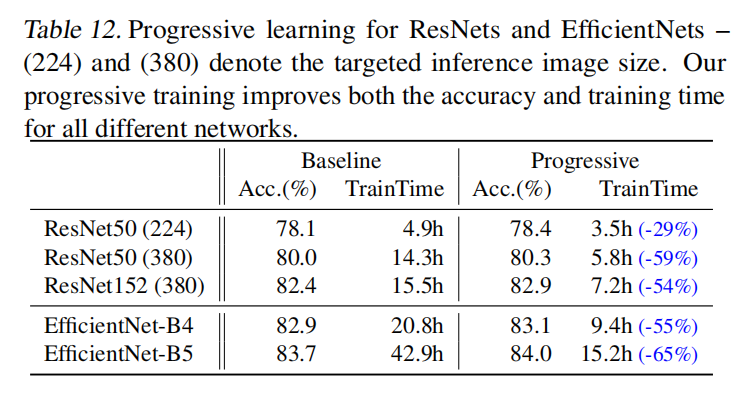
论文在不同网络(ResNet/EfficientNet)和不同目标图像大小的情况下应用了渐近式学习,证明了其有效性。如表12所示:
自适应正则化的重要性
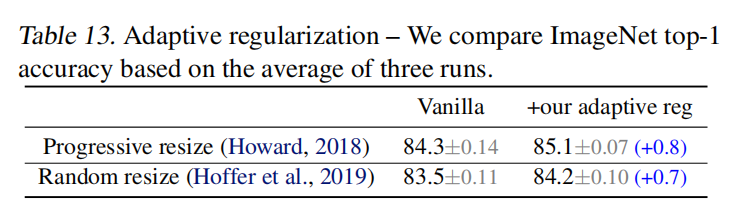
论文的核心观点之一是训练阶段的自适应正则化,即根据图像大小变化动态调整正则化强度。论文比较了另外两种训练设置:一是不改变正则化强度,只是逐步的从小到大的增加图像大小(Training imagenet in 3 hours for 25 minutes);二是在每个批次中随机采样设置不同的图像大小(Mix & match: training convnets with mixed image sizes for improved accuracy, speed and scale resiliency)。训练结果如下表13所示,通过增加自适应正则化强度配置,模型能够得到更好的训练精度。
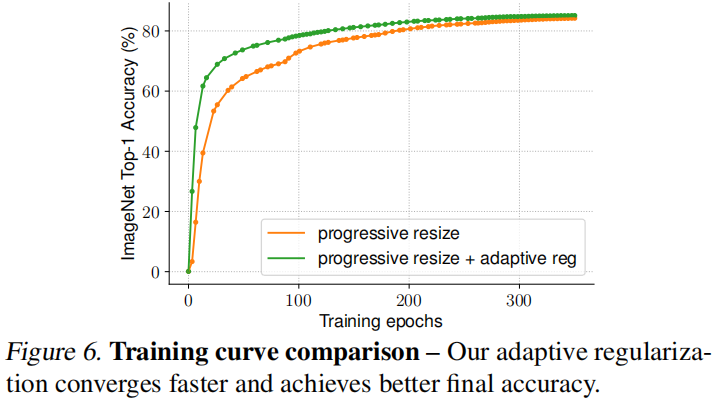
论文同时比较了训练曲线,可以发现自适应正则化允许更快的收敛。如下图6所示:
小结
之前的论文大多关注于如何提高准确率、减少模型大小或FLOPS,而随着训练数据集的不断增大,如何提高训练速度也成为了研究热点(在工作中也遇到了这个问题)。论文专注在显著提升训练速度和参数效率这两个研究方向(当然模型准确率也是杠杠的),提出了EfficientNetV2模型簇和渐进式学习算法。
论文重点:
- 通过训练感知
NAS(设计新算子Fused-MBConv以及优化其他搜索空间选项),搜索得到基准模型EfficientNetV2-S(参数量和FLOPs大于EfficientNet-B4,但拥有更高的准确率、训练和推理效率); - 通过优化复合放大策略(设定输入图像上限 + 逐步放大后几个阶段层数),获取放大模型
EfficientNetV2-M/L; - 加入渐进式学习,正则化强度随输入图像大小自适应调整,能够加速训练时间。
EffcientNetV2在精度上能够超过之前最好的模型(包括纯卷积模型和Transformer架构模型),并且相比于之前最好模型而言拥有更高效的训练效率和参数效率,但相对而言还是需要极大的参数量和计算资源,可以预见EfficientNetV2-lite不久将会出现。
论文也通过反向复合放大策略获取更小配置的EfficientNetV2模型,相比于EfficientNet,能够在更少参数量和FLOPs的情况下获取得到更高的推理效率。而参考论文TinyNet可知,逆向复合放大策略获取的模型配置并不是最优的,从这个方向进行研究,应该能得到不少的新东西吧???
小彩蛋:为了公平的比较推理延时,论文采用了Pytorch Image Models库进行所有模型的构建。看来Google内部也更觉得Pytorch更方便哈~~~