EfficientNet-lite
原文地址:Higher accuracy on vision models with EfficientNet-Lite
官方实现:EfficientNet-lite
简介
EfficientNet-lite是Google推出的基于EfficientNet优化的适用于移动/物联网的图像分类模型。为了更好的在边缘端设备上进行部署,对EfficientNet进行了部分调整,在保持精度的同时尽可能的减少推理耗时和存储空间。
优化
主要进行了3方面的优化:
- Removed squeeze-and-excitation networks since they are not well supported
- Replaced all swish activations with RELU6, which significantly improved the quality of post-training quantization (explained later)
- Fixed the stem and head while scaling models up in order to reduce the size and computations of scaled models
- 移除
ES注意力层,因为移动端设备硬件并没有很好的适配它; - 使用
ReLU6替代Swish激活函数,这样能够显著提高训练后量化阶段的性能; - 固定
stem层和head层的大小,这样能够避免额外的模型缩放产生的权重和计算量。
具体操作步骤应该和EfficientNet一样,首先在指定FLOPS约束下通过NAS搜索出基准模型架构 - EfficientNet-lite0;然后通过网格搜索获取FLOPS约束下的LITE架构。
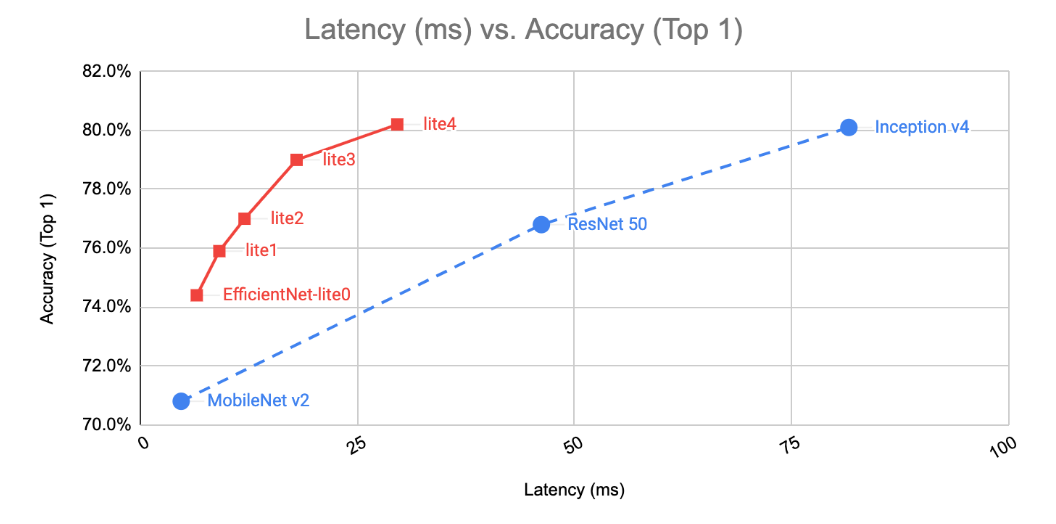
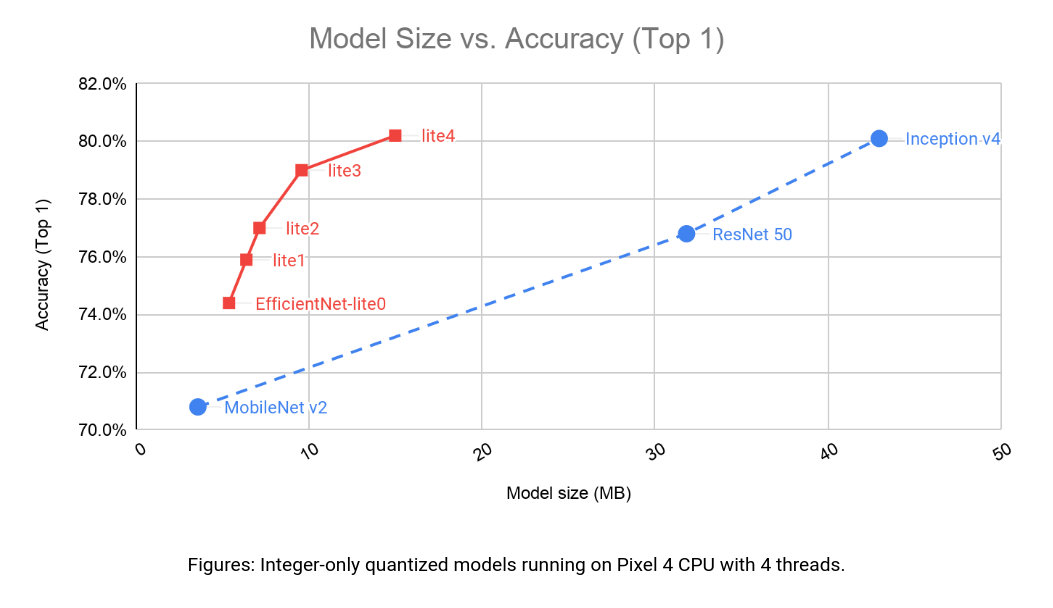
比较
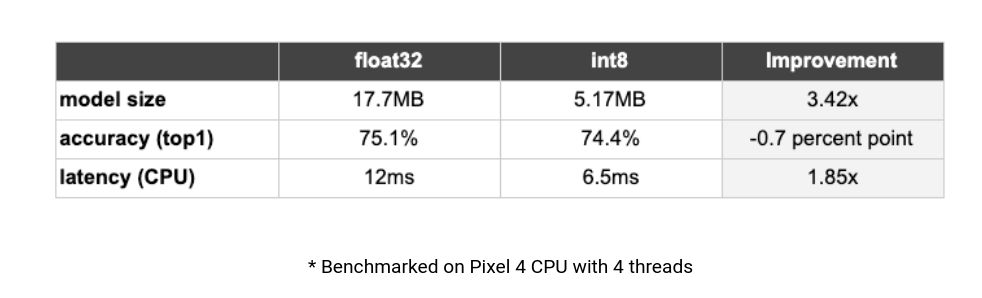
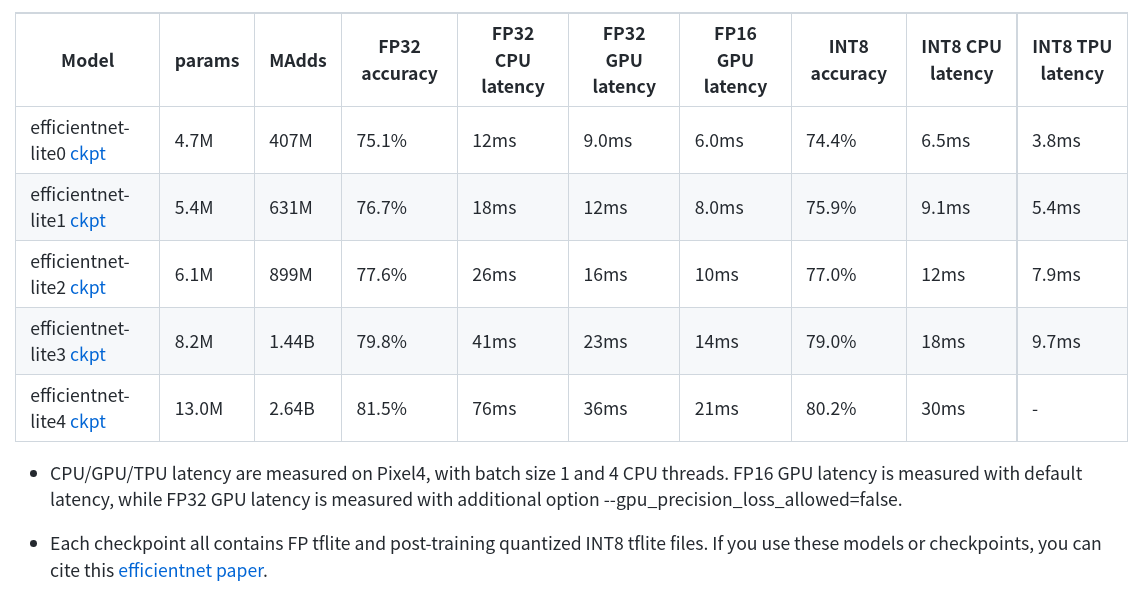
ReLU6
针对第二点替换激活函数,文章还特别进行了解释。为了更好的降低推理耗时,基于TensorFlow Lite训练后量化工作流对模型进行量化。在实验EfficientNet-lite0过程中发现模型ImageNet准确率直线从75%到46%,经过调研发现是因为量化前模型输出张量取值范围太大了,而量化的本质在于对浮点值进行仿射变换,以适应int8精度约束。
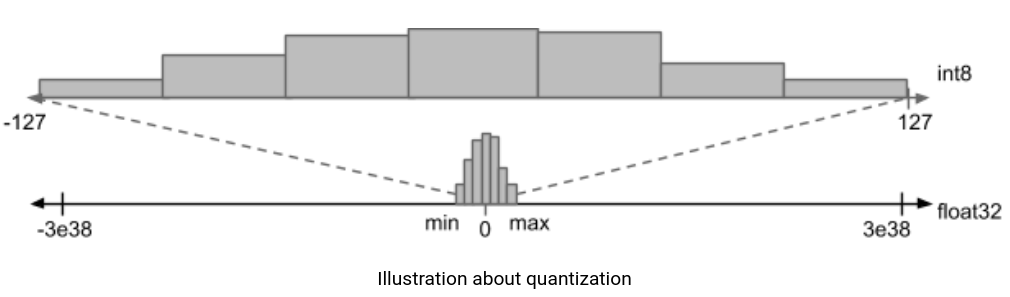
在文章实验示例中输出张量的取值范围在[-168, 204]之间,所以使用ReLU6替代Swish激活函数,这样经过ReLU6激活之后,输出严格限制在[0, 6]之间,能够大大减少浮点数取值,准确率也恢复到74.4%