论文汇总
整理网站发布过的论文调研,涉及多模态、模型训练、目标分类、目标检测、目标分割、图像检索、OCR、人脸检测/识别、模型蒸馏、模型剪枝、视频识别、细粒度分类、行人属性识别、视频压缩等领域。
整理网站发布过的论文调研,涉及多模态、模型训练、目标分类、目标检测、目标分割、图像检索、OCR、人脸检测/识别、模型蒸馏、模型剪枝、视频识别、细粒度分类、行人属性识别、视频压缩等领域。
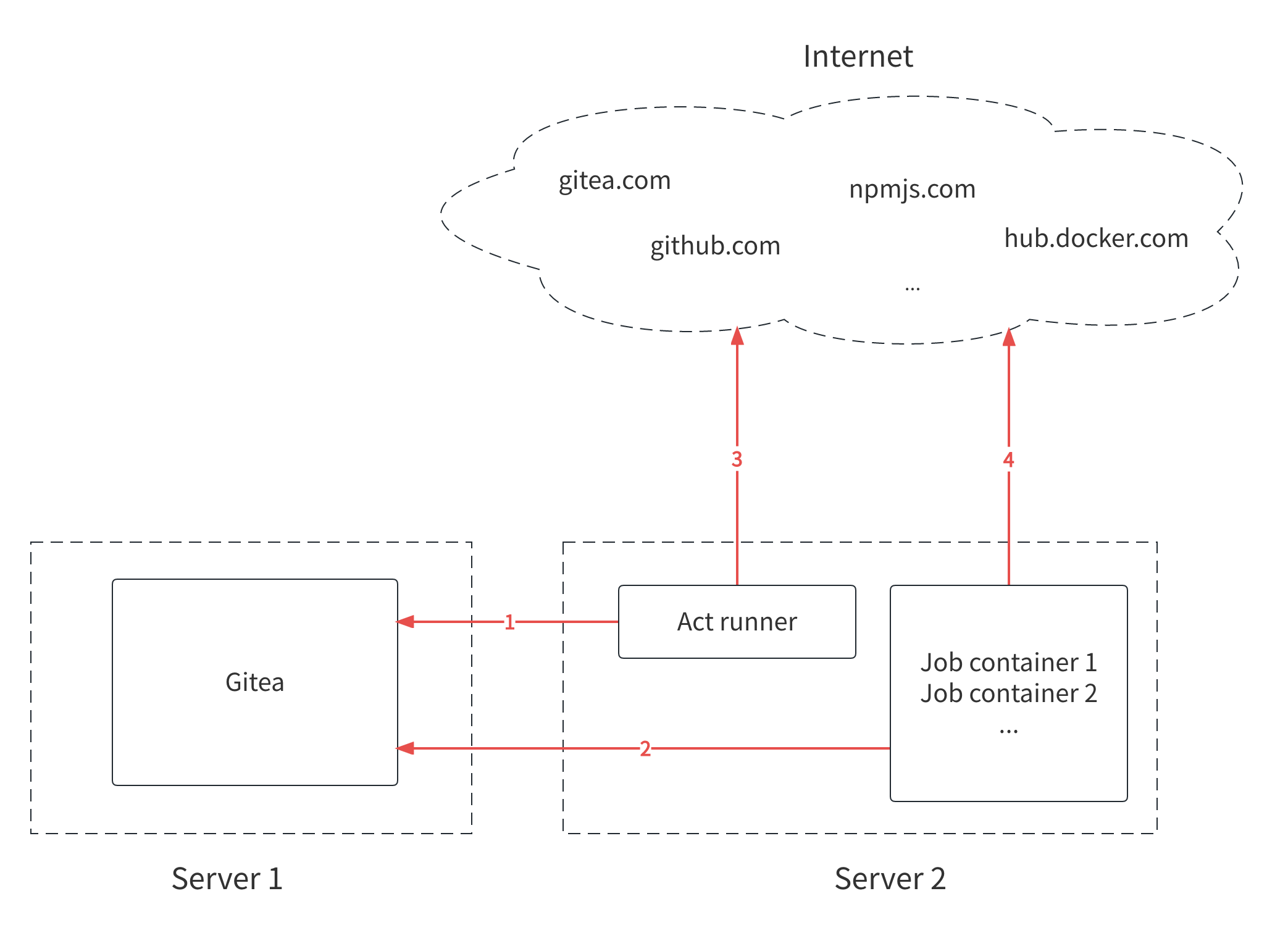
距离上一次搭建Hexo/NexT博客网站已过去四年。虽然整体交互体验并未发生颠覆性的变化,但在交互细节与部署实现方面,确实持续进行了打磨与优化。这一次我打算使用最新版本(hexo 8.1.1 / NexT 8.26.0)重新构建我的博客网站,同时会结合更多的工具(Docker、Github Action/Pages、Gitea Actions/Nginx)来优化整个部署PIPELINE。
Use DeepSeek in Claude Code。TIP:买台好点的电脑,配个好点的网络,不然真的跑得慢 ~~~
原文地址: Pytorch 2.x
汇总本站涵盖的主流数据集说明,覆盖图像分类、目标检测、实例分割、OCR 及大模型预训练等核心任务。
一直没理清章节顺序,索性按思绪所至落笔,记录下这一年的技术探索、身体警醒、生活减法,以及对未来的微小期待。
前几周我实现了第一版基于大语言模型(LLM)的博客文章分类与标签自动生成系统,初衷是借助 AI 的语义理解能力,解放双手、提升元数据的一致性与可维护性。然而,在实际运行一段时间并观察生成结果后,我发现这套方案虽然自动化了流程,但是没有真正实现智能化 — 最终得到的类别列表和标签体系既不能精准反映单篇文章的核心内容,也无法体现整个博客的技术定位与知识结构。
我试图用一个端到端的黑箱流程解决所有问题。而现实是,好的元数据体系需要清晰的顶层设计、细粒度的内容理解,以及人机协同的持续演进机制。我对整个流程进行了彻底重构,将原先的两个脚本拆解为四个职责明确、可独立验证的阶段,形成一套更稳健、更可控、也更贴合实际需求的四阶段自动化工作流。
最近在重构博客网站的时候,突然想到是不是可以借助大模型自动生成分类和标签。经过几轮尝试,对比不同的大模型使用方案,最终实现了结合人工审核与大模型能力的两阶段工程,这是最契合当前需求的方案。
距离上一次搭建Hexo/NexT博客网站已过去四年。虽然整体交互体验并未发生颠覆性的变化,但在交互细节与部署实现方面,确实持续进行了打磨与优化。这一次我打算使用最新版本(hexo 8.1.1 / NexT 8.26.0)重新构建我的博客网站,同时会结合更多的工具(Docker、Github Action/Pages、Gitea Actions/Nginx)来优化整个部署PIPELINE。
Gitea Actions是Gitea内置的CI&CD解决方案,它最大程度的兼容了Github Actions的设计语法和使用方式。