YOLO9000: Better, Faster, Stronger
原文地址:YOLO9000: Better, Faster, Stronger
摘要
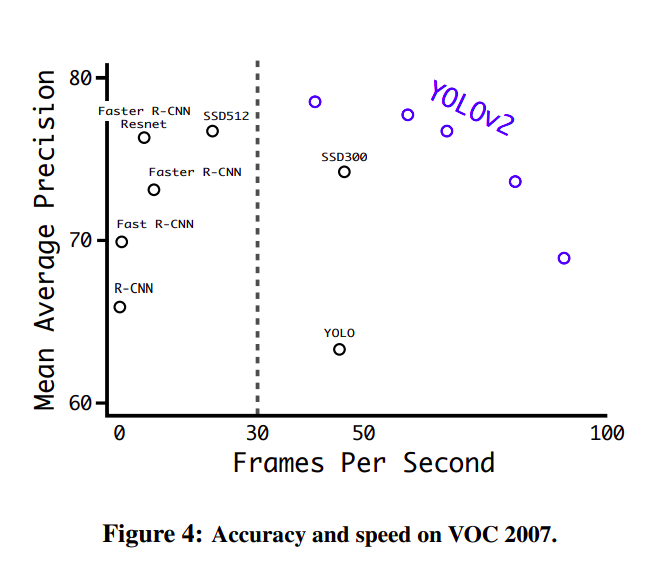
We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object categories. First we propose various improvements to the YOLO detection method, both novel and drawn from prior work. The improved model, YOLOv2, is state-of-the-art on standard detection tasks like PASCAL VOC and COCO. Using a novel, multi-scale training method the same YOLOv2 model can run at varying sizes, offering an easy tradeoff between speed and accuracy. At 67 FPS, YOLOv2 gets 76.8 mAP on VOC 2007. At 40 FPS, YOLOv2 gets 78.6 mAP, outperforming state-of-the-art methods like Faster R-CNN with ResNet and SSD while still running significantly faster. Finally we propose a method to jointly train on object detection and classification. Using this method we train YOLO9000 simultaneously on the COCO detection dataset and the ImageNet classification dataset. Our joint training allows YOLO9000 to predict detections for object classes that don’t have labelled detection data. We validate our approach on the ImageNet detection task. YOLO9000 gets 19.7 mAP on the ImageNet detection validation set despite only having detection data for 44 of the 200 classes. On the 156 classes not in COCO, YOLO9000 gets 16.0 mAP. But YOLO can detect more than just 200 classes; it predicts detections for more than 9000 different object categories. And it still runs in real-time.
我们介绍了YOLO9000,一个最先进的实时目标检测系统,能够检测超过9000个目标类别。首先,我们提出了对YOLO检测方法的多种改进,这些改进既有新颖的,也有从先前工作中借鉴的。改进后的模型YOLOv2在标准检测任务如PASCAL VOC和COCO上都是最先进的。通过使用一种新颖的多尺度训练方法,相同的YOLOv2模型可以在不同大小下运行,提供了速度和精度之间的简单权衡。在67 FPS(每秒帧数)下,YOLOv2在VOC 2007上获得了76.8的mAP(平均精度均值)。在40 FPS下,YOLOv2获得了78.6的mAP,超越了如使用ResNet的Faster R-CNN和SSD等先进方法,同时仍然显著更快。最后,我们提出了一种方法,用于联合训练目标检测和分类。使用这种方法,我们同时在COCO检测数据集和ImageNet分类数据集上训练YOLO9000。我们的联合训练允许YOLO9000预测那些没有标记检测数据的对象类别的检测。我们在ImageNet检测任务上验证了我们的方法。尽管YOLO9000只为200个类别中的44个类别拥有检测数据,但它在ImageNet检测验证集上仍然获得了19.7的mAP。在COCO中不存在的156个类别上,YOLO9000获得了16.0的mAP。但YOLO不仅能检测超过200个类别;它预测了超过9000个不同目标类别的检测,并且仍然保持实时运行。
概述
YOLOv2参考YOLOv1实现,输出特征划分为
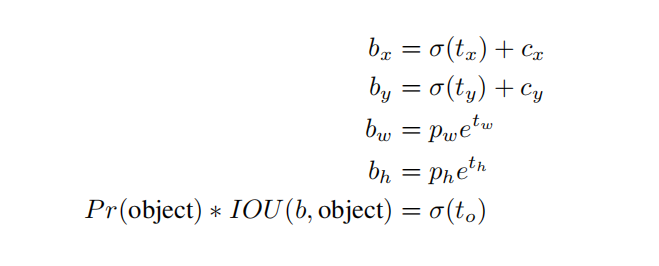
预测框计算公式如上。其中,
、 、 、 表示模型输出特征值; 表示 sigmoid函数,取值范围是(0, 1);表示底数为 e的指数函数,取值范围是(0,+∞);
、 表示网格下标; 、 表示锚点框宽高; 、 、 、 表示最终的预测框中心点坐标和宽高

YOLOv2网络
YOLOv2网络由两部分组成,Darknet-19 Backbone + YOLOv2 Head
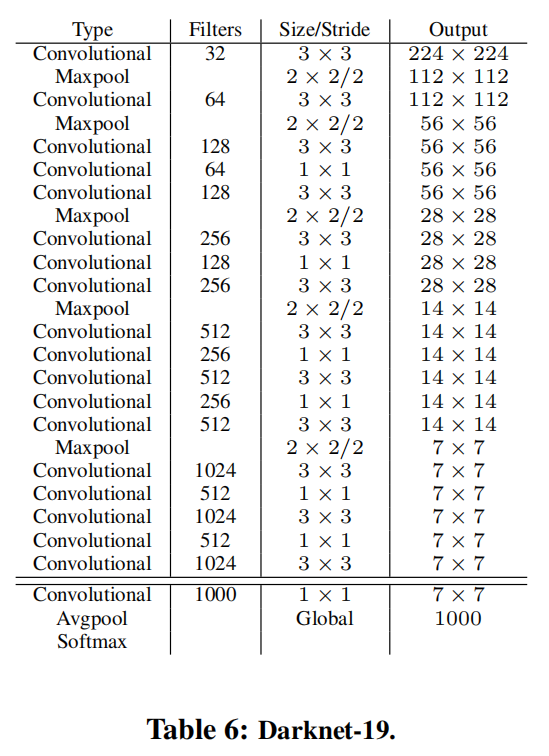
Darknet-19
Darknet-19是一个深度为19层的卷积神经网络,主要由卷积层、池化层和批量归一化层组成。
YOLOv2 Head

passthrough layer
YOLOv2在Head层引入了passthrough layer结构,在通道维度连接高分辨率特征和低分辨率特征,用来结合不同尺度的特征信息。具体实现如下:

AnchorBox
YOLOv2没有采用人工设计的锚点框,而是使用算法kmeans聚类训练数据集标注框的宽高得到锚点框列表。
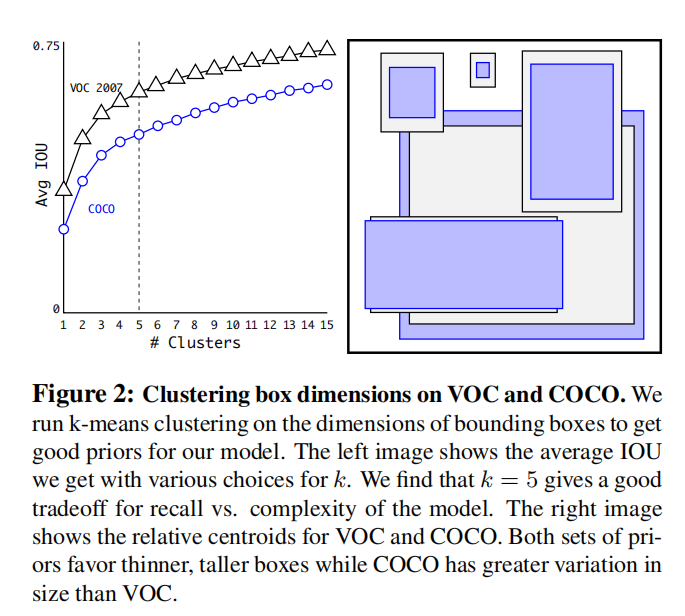
它的距离函数不是欧式距离,而是标注框和聚类中心之间的IoU。
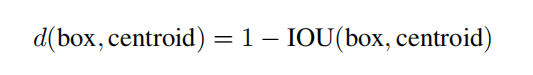
YOLOv2Loss
类似于YOLOv1Loss,YOlOv2Loss为每个标注框分配一个预测框,然后计算匹配预测框(称为正样本)的坐标损失(box_loss)、目标置信度损失(obj_loss)和分类损失(cls_loss),同时计算非匹配预测框(负样本)的目标置信度损失(noobj_loss)。
注意:标注框是和锚点框配对,计算它们之间的差值作为target,模型训练的目的是让模型输出结果拟合target。
YOLOv2的损失函数由三部分组成,分别是坐标损失(box_loss)、置信度损失和分类损失。这些损失函数在训练过程中共同作用,以确保模型能够准确地预测边界框的位置、置信度和类别。
- 坐标损失(box_loss)
- 对于正样本(即与真实标注框有重叠的预测框),我们使用均方误差损失(MSELoss)来计算坐标损失。具体来说,我们计算预测框的中心点坐标(x, y)以及宽高(w, h)与真实标注框之间的误差,并乘以系数1.0。
- 通过这种方式,模型能够学习到如何准确地预测边界框的位置。
- 置信度损失(confidence_loss)
- 正样本置信度损失
- 对于正样本,我们使用均方误差损失(MSELoss)来计算置信度损失。这里的目标(target)是预测框与真实标注框之间的交并比(IoU),它反映了预测框与真实标注框的重叠程度。
- 为了使模型更加关注于正样本的预测,我们给这部分损失乘以一个较大的系数5.0,以增强模型对正样本的识别能力。
- 负样本置信度损失
- 对于负样本(即与真实标注框没有重叠的预测框),我们也使用均方误差损失(MSELoss)来计算置信度损失。但此时的目标(target)是0,表示这些预测框不包含任何目标物体。
- 由于负样本在数量上可能远多于正样本,为了平衡正负样本之间的贡献,我们给这部分损失乘以系数1.0。
- 正样本置信度损失
- 分类损失(classification_loss)
- 对于正样本,我们使用交叉熵损失来计算分类损失。交叉熵损失是衡量预测概率分布与真实概率分布之间差异的指标,适用于多分类问题。
- 在这里,我们只对正样本应用分类损失,并乘以系数1.0。这样做可以确保模型只关注于那些真正包含目标物体的预测框的分类预测。
另外,为了平衡不同大小的预测框对损失函数的贡献,在计算预测框宽度(box_w)和高度(box_h)的均方误差损失(MSELoss)时,引入了一个名为box_scale的系数。这个系数通过2 - w_i * h_i来计算(其中w_i/h_i代表预测框在特征网格上的宽高比例,取值在0到1之间)。
在训练早期发现模型输出的预测框会出现极大值宽高,导致box_scale得到负值,最终box_loss出现了nan现象。实际复现过程中设置box_scale=torch.abs(2 - w_i * h_i)来缓解这个问题。
同时,设置了一个忽略阈值(ignore_thresh=0.6)。对于那些与真实标注框的交并比(IoU)大于该阈值的负样本(即预测框),在计算置信度损失时会将其忽略。这样做的目的是避免对那些与真实目标重叠较多但并非最佳匹配的预测框施加过于严格的惩罚,从而提高模型的鲁棒性和性能。
通过综合这三个部分的损失,YOLOv2能够在训练过程中逐步优化其预测能力,实现更准确的边界框预测和分类识别。
YOLOv2 in yolov5
原始论文尝试了不同的模型实现、损失函数设计以及许多训练技巧,找到了一种最佳组合。
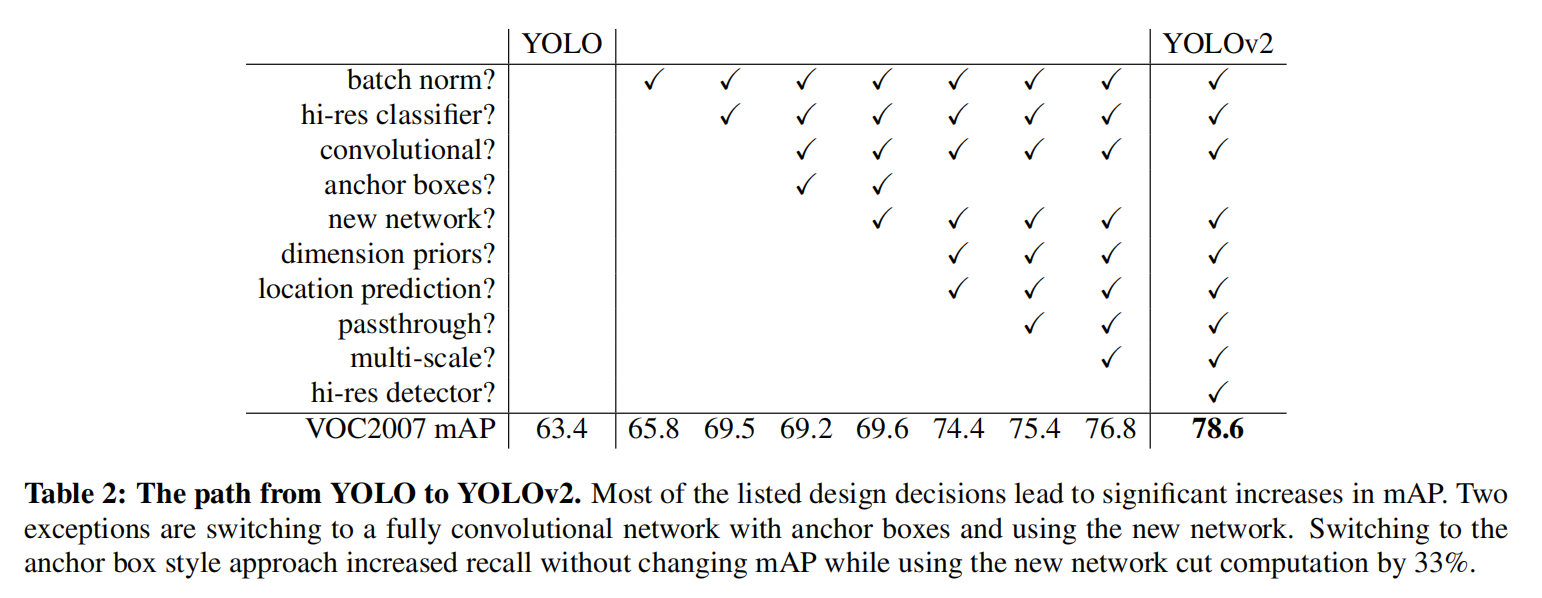
实际复现过程中,我尝试着在ultralytics/yolov5 v7.0工程中实现了Darknet-19和YOLOv2Loss,其他训练操作(包括anchor-box计算、输入大小、预处理增强、后处理实现等等)参考yolov5s官方训练,也实现了非常不错的效果。
| Original (darknet) | tztztztztz/yolov2.pytorch | zjykzj/YOLOv2(This) | zjykzj/YOLOv2(This) | |
|---|---|---|---|---|
| ARCH | YOLOv2 | YOLOv2 | YOLOv2 | YOLOv2-Fast |
| GFLOPs | / | / | 69.5 | 48.5 |
| DATASET(TRAIN) | VOC TRAINVAL 2007+2012 | VOC TRAINVAL 2007+2012 | VOC TRAINVAL 2007+2012 | VOC TRAINVAL 2007+2012 |
| DATASET(VAL) | VOC TEST 2007 | VOC TEST 2007 | VOC TEST 2007 | VOC TEST 2007 |
| INPUT_SIZE | 416x416 | 416x416 | 640x640 | 640x640 |
| PRETRAINED | TRUE | TRUE | FALSE | FALSE |
| VOC AP[IoU=0.50:0.95] | / | / | 44.3 | 29.8 |
| VOC AP[IoU=0.50] | 76.8 | 72.7 | 75.1 | 62.6 |
| Original (darknet) | zjykzj/YOLOv2(This) | zjykzj/YOLOv2(This) | |
|---|---|---|---|
| ARCH | YOLOv2 | YOLOv2 | YOLOv2-Fast |
| GFLOPs | / | 69.7 | 48.8 |
| DATASET(TRAIN) | / | COCO TRAIN2017 | COCO TRAIN2017 |
| DATASET(VAL) | / | COCO VAL2017 | COCO VAL2017 |
| INPUT_SIZE | 416x416 | 640x640 | 640x640 |
| PRETRAINED | TRUE | FALSE | FALSE |
| COCO AP[IoU=0.50:0.95] | 21.6 | 28.6 | 20.1 |
| COCO AP[IoU=0.50] | 44.0 | 50.7 | 41.2 |
小结
YOLOv2是YOLO系列第一个Anchor-based算法,通过引入先验框(AnchorBox)和学习细粒度特征来提升目标检测算法的性能。

这是一篇拖了很久很久的文章,在2020年5月开始提笔,一直到2024年才发布出来,拖这么久的原因一方面没有看懂算法框架,另一方面缺乏源码理解。经过这些年的工作和实践,逐渐给自己设置算法学习的边界,不再执着于底层卷积模型和损失函数的数学推理,而是专注于算法网络的实现、训练框架的应用和推理引擎的部署,反而减轻了算法学习的难度。