YOLOv3: An Incremental Improvement
原文地址:YOLOv3: An Incremental Improvement
摘要
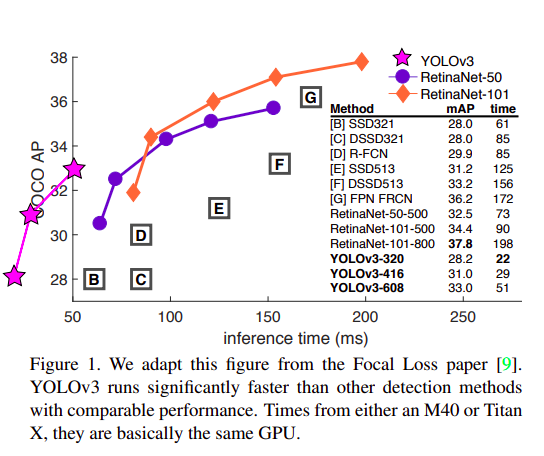
We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained this new network that’s pretty swell. It’s a little bigger than last time but more accurate. It’s still fast though, don’t worry. At 320x320 YOLOv3 runs in 22 ms at 28.2 mAP, as accurate as SSD but three times faster. When we look at the old .5 IOU mAP detection metric YOLOv3 is quite good. It achieves 57.9 mAP@50 in 51 ms on a Titan X, compared to 57.5 mAP@50 in 198 ms by RetinaNet, similar performance but 3.8x faster. As always, all the code is online at https://pjreddie.com/yolo/.
我们为YOLO带来了一些更新!我们进行了一系列小的设计更改以使其变得更好。我们还训练了这个新的网络,它相当出色。尽管它比上一次稍微大了一些,但更加准确。不过请放心,它仍然很快。在320x320的分辨率下,YOLOv3在22毫秒内运行,达到了28.2的mAP(平均精度均值),这与SSD一样准确,但速度快三倍。当我们查看旧的.5 IOU mAP检测指标时,YOLOv3表现得相当好。在Titan X上,它在51毫秒内达到了57.9 mAP@50,而RetinaNet则需要198毫秒才能达到类似的57.5 mAP@50性能,但YOLOv3比它快了3.8倍。一如既往,所有代码都在网上公开,地址为:https://pjreddie.com/yolo/。
YOLOv3网络

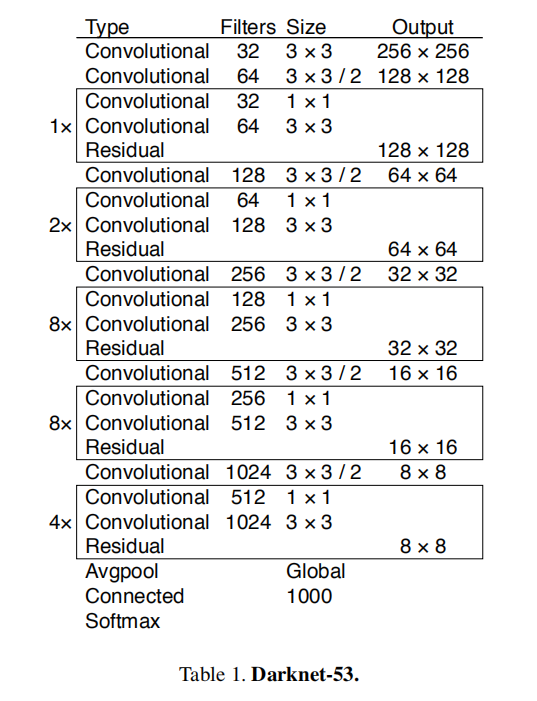
Darknet-53
Darknet-53是Darknet-19的升级版本,通过堆叠更多的
Neck
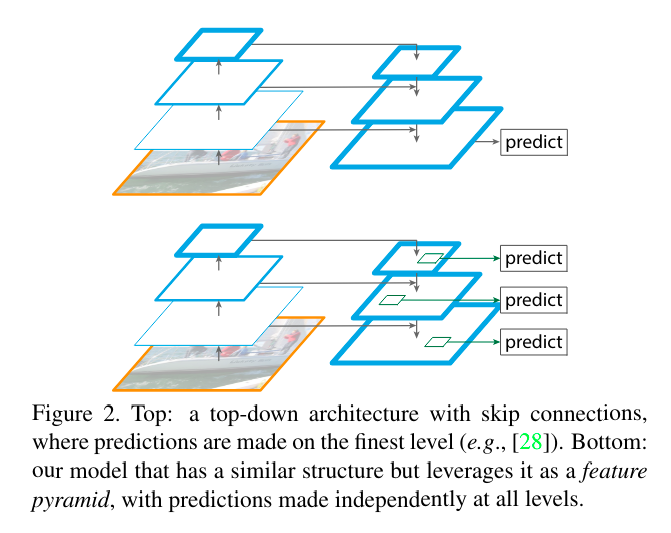
之前YOLOv2采用的passthrough层,简单的叠加不同分辨率特征向量的信息。YOLOv3参考特征图金字塔网络FPN(Feature Pyramid Networks)的实现,采用自顶向下的路径增强和横向连接的方式,将高层语义信息丰富的特征图与低层分辨率高、语义信息少的特征图进行融合。
具体来说,FPN从高层(低分辨率)特征开始,通过上采样(upsampling)操作将这些特征映射到更高的分辨率,然后与相同分辨率的较低层(高分辨率)特征进行融合。这种融合是通过横向连接(lateral connections)来实现的,即将高层特征上采样后与较低层特征进行相加或拼接(concatenate)。通过这种方式,FPN能够在多个尺度上生成丰富的特征表示,从而提高目标检测的准确性。因此,FPN的自顶向下结构使得高层语义信息能够向下传播到低层,并与低层的细节信息相结合,形成多尺度的特征表示。
Head
YOLOv3 Head的设计精妙地融合了多尺度特征预测,其运作流程如下:
- 特征提取与多尺度预测:YOLOv3首先提取输入特征,在特征计算过程中采集了多个尺度的特征向量,这些特征向量具有不同的空间分辨率,如13x13、26x26和52x52。这些多尺度的特征向量用于后续的预测框计算,使得模型能够同时检测不同大小的目标。
- Anchor Box的应用:
- 锚点框的生成:YOLOv3利用k-means++聚类算法来生成锚点框列表,以更好地匹配训练数据集中目标的实际尺寸分布。虽然常见的配置可能使用9个锚点框,但具体数量取决于聚类结果及模型设计者的选择,并非固定为9个。
- 锚点框的分配:YOLOv3在不同的特征图层上应用不同尺度的锚点框:
- 多尺度特征图与锚点框匹配:YOLOv3在三个不同空间分辨率的特征图(例如,13x13, 26x26, 52x52)上分别预测物体。较大尺度的特征图(如52x52)实际上对应于图像中的较小区域,因此倾向于使用较小的锚点框来捕捉小目标;而较小尺度的特征图(如13x13)覆盖较大的图像区域,会使用较大的锚点框以适应大目标的检测。这是因为较高分辨率的特征图能提供更多的空间细节,适合定位小物体,而低分辨率特征图更适合捕捉全局上下文和较大的目标。
- 锚点框尺寸分配原则:高分辨率特征图(如52x52)配以较小的锚点框来预测小目标,而低分辨率特征图(如13x13)则配备较大的锚点框以预测大目标。这样的设计有利于在不同的尺度上有效检测目标,充分利用了多尺度特征图的优势。
- 预测框分类概率的计算:在训练过程中,为了优化分类损失,YOLOv3采用了二元交叉熵(BCE)作为损失函数。因此,在Head层中,使用sigmoid函数来计算每个预测框的分类概率。sigmoid函数将模型输出的预测值映射到0到1之间,表示该预测框属于某个类别的概率。
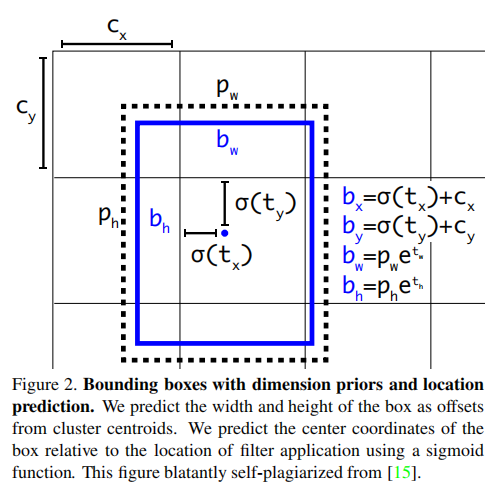
另外,YOLOv3对于预测框的坐标计算和YOLOv2保持一致,计算公式如下:

YOLOv3Loss
YOLOv3Loss的设计继承了YOLOv2Loss的核心思想,即为每个标注框分配一个最匹配的预测框,并据此计算损失。但与YOLOv2不同的是,YOLOv3Loss在多尺度特征向量上进行计算,这显著提升了其检测性能。
具体来说,YOLOv3Loss主要包含四个组成部分:
- 坐标损失(box_loss):对于正样本(即与真实标注框有重叠的预测框),我们使用均方误差损失(MSELoss)来计算坐标损失。具体来说,我们计算预测框的中心点坐标(x, y)以及宽高(w, h)与真实标注框之间的误差,并乘以系数1.0。
- 置信度损失(confidence_loss)
- 目标置信度损失(obj_loss)
- 我们使用二元交叉熵损失(Binary Cross Entropy Loss,简称BCELoss)来计算置信度损失。这里的目标(target)是预测框与真实标注框之间的交并比(IoU),它反映了预测框与真实标注框的重叠程度。
- 为了使模型更加关注于正样本的预测,我们给这部分损失乘以一个较大的系数5.0,以增强模型对正样本的识别能力。
- 非目标置信度损失(noobj_loss)
- 对于负样本(即与真实标注框没有重叠的预测框),我们也使用BCELoss来计算置信度损失。但此时的目标(target)是0,表示这些预测框不包含任何目标物体。
- 由于负样本在数量上可能远多于正样本,为了平衡正负样本之间的贡献,我们给这部分损失乘以系数1.0。
- 目标置信度损失(obj_loss)
- 分类损失(cls_loss)
- 对于正样本,我们使用二元交叉熵损失(Binary Cross Entropy Loss,简称BCELoss)来计算分类损失。
- 在这里,我们只对正样本应用分类损失,并乘以系数1.0。这样做可以确保模型只关注于那些真正包含目标物体的预测框的分类预测。
训练trick
在训练YOLOv3模型的过程中进行了一系列优化和实验。首先,我引入了一种新的box_scale计算方法,该方法首先基于预测框的宽高(w_i和h_i)计算一个初始的scale值,即scale = 2 - w_i * h_i。接着,根据scale的数值范围进行调整:
- 如果scale小于1或大于2,表明预测框的宽高存在异常,设置box_scale=0,以排除该预测框对坐标损失(box_loss)的贡献。
- 如果scale在[1, 2]之间,说明预测框的尺寸在合理范围内,保留原始的scale值,使其继续参与坐标损失的计算。
通过这种方法,我观察到损失函数能够更平滑地下降,并且模型的训练效果也符合预期。
此外,我还参考了其他仓库的实现,设置ignore_thresh=0.7,以排除与真实标注框重叠度过低的预测框。
在置信度损失方面,尝试了多种不同的组合策略。具体来说:
- 对于正样本(obj_loss),使用二元交叉熵损失(BCELoss),并将目标(target)设置为1,表示预测框包含目标物体。
- 对于负样本(noobj_loss),尝试了用均方误差损失(MSELoss)和二元交叉熵损失(BCELoss)两种策略,并将目标(target)分别设置为0,表示预测框不包含目标物体。
- 同时还探索了使用预测框与真实标注框的交并比(IoU)作为正样本的置信度目标,并与二元交叉熵损失(BCELoss)相结合的策略。
几点观察:
- 正负样本的置信度损失需要采用相同的损失计算(都是MSELoss或者都是BCELoss);
- 设置正样本target=1的时候,设置BCELoss,它的效果会被MSELoss好很多;
- 设置正样本target=iou(pred_box, truth_box),配合BCELoss能够得到最好的效果。
Loss小结
YOLOv3Loss的两大特色:
- 多尺度特征向量:YOLOv3采集了不同空间分辨率的特征向量,如13x13、26x26和52x52,这不仅增加了预测框的数目,提升了模型的检测能力,同时也考虑到了小目标在特征提取过程中的困难。通过在较低分辨率的特征图上进行计算,YOLOv3能够更好地捕捉小目标的特征。
- 标注框与预测框的匹配机制:尽管每个标注框仍旧匹配一个预测框,但在YOLOv3中,这种匹配需要在不同层特征向量上考虑。
注意:标注框与锚点框之间的配对是YOLOv3Loss的关键步骤。通过计算标注框与锚点框之间的差值,我们得到目标值(target),模型训练的目标就是使模型的输出结果尽可能接近这些目标值。
YOLOv3 in yolov5
除了Darknet-53、FPN Neck、YOLOv3Loss的应用外,在训练过程中YOLOv3也采用了很多的新的方式。不过我尝试着在ultralytics/yolov5 v7.0工程中进行复现,所以仅关注在YOLOv3网络和YOLOv3Loss的实现,也能得到很好的训练结果。
| Original (darknet) | DeNA/PyTorch_YOLOv3 | zjykzj/YOLOv3(This) | |
|---|---|---|---|
| ARCH | YOLOv3 | YOLOv3 | YOLOv3 |
| COCO AP[IoU=0.50:0.95] | 0.310 | 0.311 | 0.400 |
| COCO AP[IoU=0.50] | 0.553 | 0.558 | 0.620 |
小结
YOLOv3应该算是YOLO系列最关键的算法之一,它奠定了后续YOLO算法的基本架构,包括Backbone/Neck/Head网络架构、多尺度特征输出、坐标/置信度/分类解偶训练以及多层锚点框使用。这些特性能够同时兼顾到大小目标的预测,同时带来了更高的实时目标检测网络的性能。