OpenDVC: An Open Source Implementation of the DVC Video Compression Method
原文地址:OpenDVC: An Open Source Implementation of the DVC Video Compression Method
实现地址:RenYang-home/OpenDVC
介绍
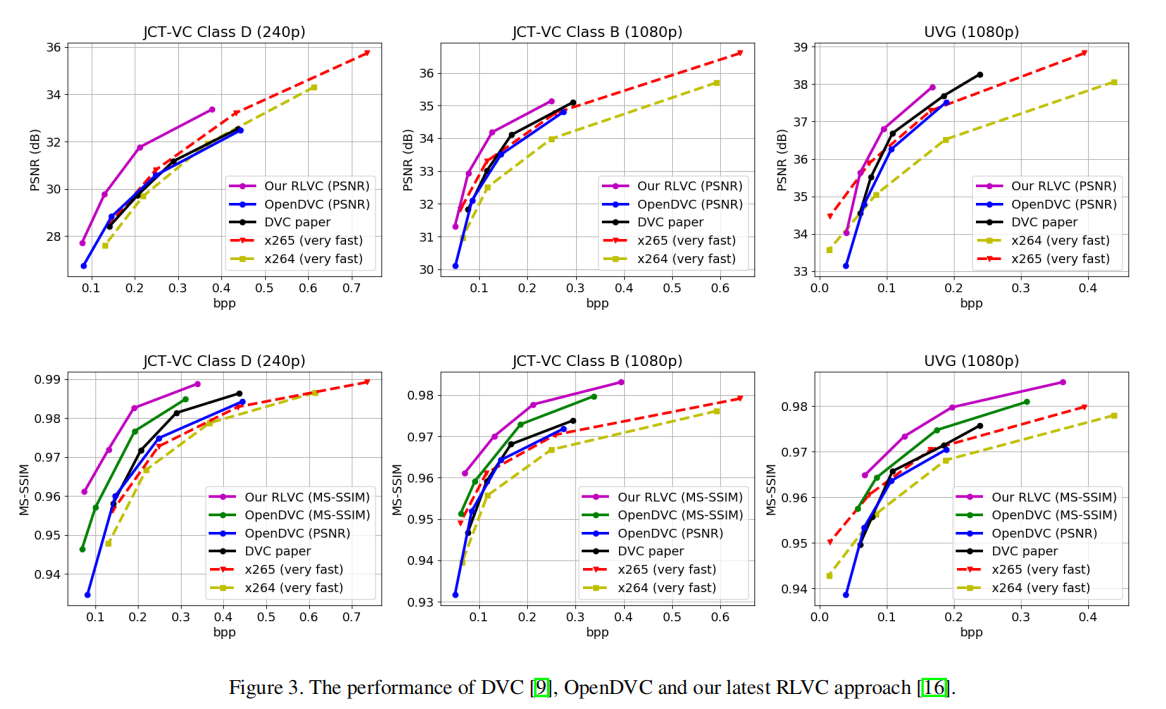
We introduce an open source Tensorflow implementation of the Deep Video Compression (DVC) method in this technical report. DVC is the first end-to-end optimized learned video compression method, achieving better MS-SSIM performance than the Low-Delay P (LDP) very fast setting of x265 and comparable PSNR performance with x265 (LDP very fast). At the time of writing this report, several learned video compression methods are superior to DVC, but currently none of them provides open source codes. We hope that our OpenDVC codes are able to provide a useful model for further development, and facilitate future researches on learned video compression. Different from the original DVC, which is only optimized for PSNR, we release not only the PSNR-optimized re-implementation, denoted by OpenDVC (PSNR), but also the MS-SSIM-optimized model OpenDVC (MS-SSIM). Our OpenDVC (MS-SSIM) model provides a more convincing baseline for MS-SSIM optimized methods, which can only compare with the PSNR optimized DVC in the past. The OpenDVC source codes and pre-trained models are publicly released at this https URL.
在这个技术报告中,我们介绍了一个基于Tensorflow的深度视频压缩(DVC)方法的开源实现。DVC是第一个端到端优化学习的视频压缩方法,实现了比x265的 Low-Delay P(LDP)极快设置更好的MS-SSIM性能和与x265(LDP very fast)相当的PSNR性能。在撰写本报告时,有几种可学习的视频压缩方法优于DVC,但目前没有一种提供开源代码。我们希望我们的OpenDVC代码能够为进一步的开发提供一个有用的模型,并为今后学习视频压缩的研究提供便利。与原来的仅针对PSNR进行优化的DVC不同,我们不仅发布了以OpenDVC(PSNR)表示的PSNR优化重实现,还发布了MS-SSIM优化模型OpenDVC(MS-SSIM)。我们的OpenDVC(MS-SSIM)模型为MS-SSIM优化方法提供了一个更具说服力的基线,过去它只能与PSNR优化DVC进行比较。OpenDVC源代码和预训练的模型发布在https://github.com/RenYang-home/OpenDVC。
DVC
DVC是第一个实现端到端优化的深度模型视频压缩框架,其整体架构参考了H264/H265设置,如下图所示:
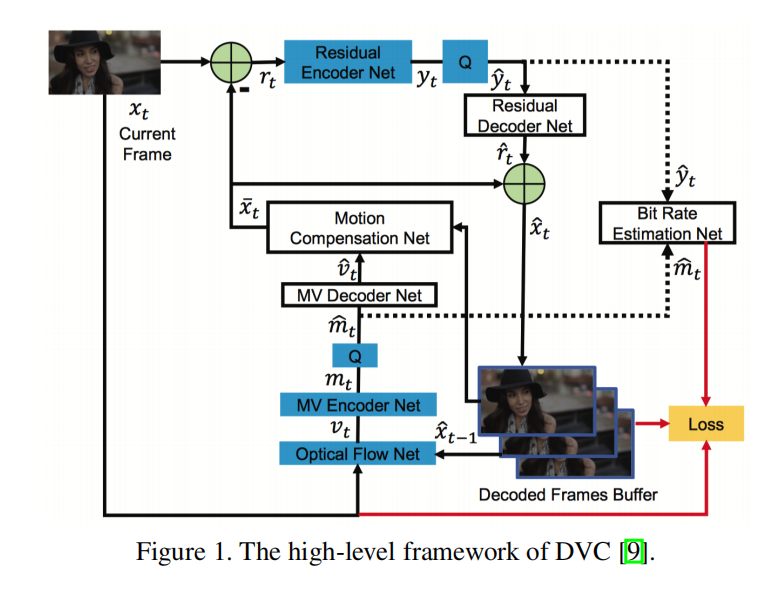
可分为以下实现模块:
- 图像压缩:用于关键帧的压缩;
- 运动估计:计算当前帧和上一个重构帧之间的动作向量;
- 运动压缩:压缩运动向量,减少存储大小;
- 运动补偿:结合当前帧的运动向量和上一个重构帧计算计算当前帧的预测帧;
- 残差估计:计算当前帧和预测帧之间的残差向量;
- 残差压缩:压缩残差响亮,减少存储大小;
- 量化:减少动作向量和残差向量的存储大小;
- 熵编码:编码动作向量和残差向量,保存为比特流。
OpenDVC
OpenDVC复现了DVC论文描述的端到端的视频压缩框架,同时在实现过程中进行了些许调整
优化标准
OpenDVC分别提供了针对PSNR和针对MS-SSIM的训练实现
OpenDVC_train_PSNR.pyOpenDVC_train_MS-SSIM.py
对于不同的评价标准,其实现会有些差异
图像压缩
- 针对
PSNR,OpenDVC使用BPG进行图像压缩 - 针对
MS-SSIM,OpenDVC使用论文Context-adaptive Entropy Model for End-to-end Optimized Image Compression提出的深度图像压缩模型
动作估计
OpenDVC遵循了DVC设置,使用论文Optical flow estimation using a spatial pyramid network提出的光流网络,通过计算光流来作为动作向量。其实现参考了sniklaus/pytorch-spynet
动作压缩
OpenDVC没有遵循DVC设置,使用论文Variational image compressio with a scale hyperprior提出的压缩实现,而是使用了论文End-to-end optimized image compression提出的压缩实现(Tensorflow提供了实现:tensorflow/compression)
这种调整并没有导致明显的性能下降,同时能够允许输入宽高仅为16的倍数即可(DVC要求32的倍数)
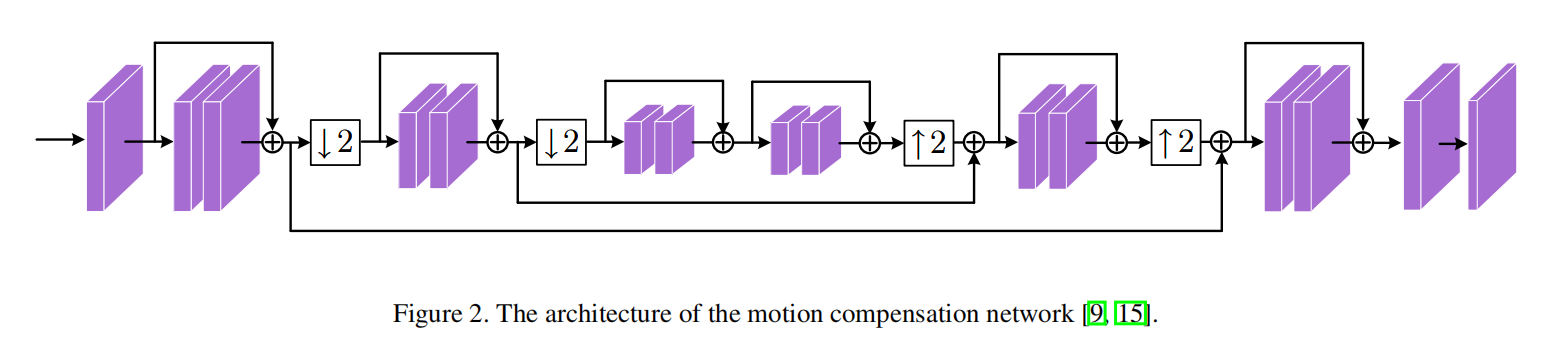
动作补偿
OpenDVC遵循了DVC设置的补偿网络架构,其详细的网络结构设计如下:
残差压缩
OpenDVC使用了和运动压缩一样的自编码器进行残差压缩,其差别在于滤波器大小设置为
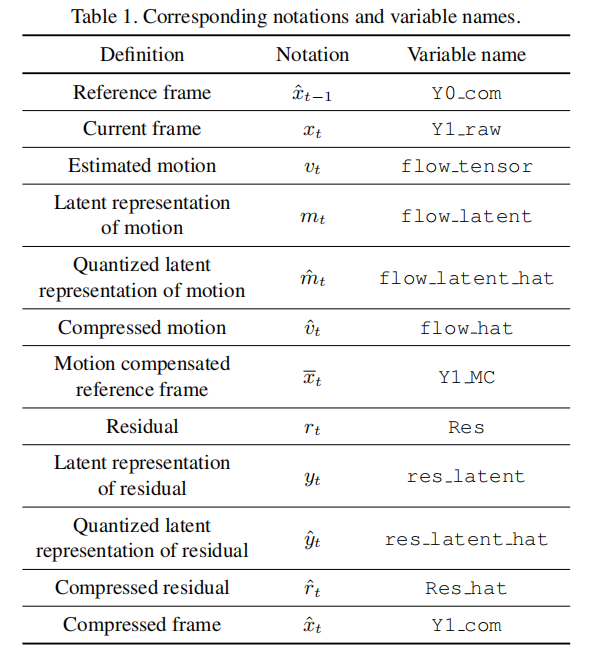
对照表
训练
OpenDVC使用了一个逐级训练方式,首先训练动作估计网络,其损失函数如下:
$$
L_{ME}=D(x_{t}, W(\hat{x}{t-1}, v{t}))
$$
表示可求导的扭曲操作,使用上一个重构帧和运行估计向量生成当前帧的重构帧。 OpenDVC使用tf.contrib.image.dense image warp实现;表示计算当前帧和重构帧之间的失真率;
完成动作估计网络的训练后,再将动作压缩网络纳入进行训练,其损失函数如下:
$$
L_{M}=\lambda \cdot D(x_{t}, W(\hat{x}{t-1}, \hat{v}{t})) + R(\hat{m}_{t})
$$
表示比特率估计函数; 是一个超参数,用于平衡失真率和比特率之间的训练;
完成动作压缩网络训练后,接着训练动作补偿网络,其损失函数如下:
$$
L_{MC}=\lambda \cdot D(x_{t}, \bar{x}{t}) + R(\hat{m}{t})
$$
最后训练整个压缩框架,其损失函数如下:
$$
L=\lambda \cdot D(x_{t}, \hat{x}{t}) + R(\hat{m}{t}) + R(\hat{y}_{t})
$$
- 对于所有损失函数,初始学习率设置为
;对于最终的训练,当损失拟合后下降学习率 10倍,直到; - 对于
PSNR优化模型使用均值平方差( Mean Square Error, MSE)进行实现;分别设置为 ; - 分别使用
的 BPG作用于的PSNR模型;
- 对于
MS-SSIM优化模型- 最后一个损失函数的
调整为 1 - MS-SSIM; 分别设置为 ; - 分别使用
的图像压缩模型作用于 的MS-SSIM模型。
- 最后一个损失函数的
性能