1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
| # -*- coding: utf-8 -*-
# @Time : 19-7-15 上午11:33
# @Author : zj
from builtins import range
from classifier.knn_classifier import KNN
import pandas as pd
import numpy as np
from sklearn import utils
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
def load_iris(iris_path, shuffle=True, tsize=0.8):
"""
加载iris数据
"""
data = pd.read_csv(iris_path, header=0, delimiter=',')
if shuffle:
data = utils.shuffle(data)
species_dict = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}
data['Species'] = data['Species'].map(species_dict)
data_x = np.array(
[data['SepalLengthCm'], data['SepalWidthCm'], data['PetalLengthCm'], data['PetalWidthCm']]).T
data_y = data['Species']
x_train, x_test, y_train, y_test = train_test_split(data_x, data_y, train_size=tsize, test_size=(1 - tsize),
shuffle=False)
return x_train, x_test, y_train, y_test
def load_german_data(data_path, shuffle=True, tsize=0.8):
data_list = pd.read_csv(data_path, header=None, sep='\s+')
data_array = data_list.values
height, width = data_array.shape[:2]
data_x = data_array[:, :(width - 1)]
data_y = data_array[:, (width - 1)]
x_train, x_test, y_train, y_test = train_test_split(data_x, data_y, train_size=tsize, test_size=(1 - tsize),
shuffle=shuffle)
y_train = np.array(list(map(lambda x: 1 if x == 2 else 0, y_train)))
y_test = np.array(list(map(lambda x: 1 if x == 2 else 0, y_test)))
return x_train, x_test, y_train, y_test
def compute_accuracy(y, y_pred):
num = y.shape[0]
num_correct = np.sum(y_pred == y)
acc = float(num_correct) / num
return acc
def cross_validation(x_train, y_train, k_choices, num_folds=5, Classifier=KNN):
X_train_folds = np.array_split(x_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
# 计算预测标签和验证集标签的精度
k_to_accuracies = {}
for k in k_choices:
k_accuracies = []
# 随机选取其中一份为验证集,其余为测试集
for i in range(num_folds):
x_folds = X_train_folds.copy()
y_folds = y_train_folds.copy()
x_vals = x_folds.pop(i)
x_trains = np.vstack(x_folds)
y_vals = y_folds.pop(i)
y_trains = np.hstack(y_folds)
classifier = Classifier()
classifier.train(x_trains, y_trains)
y_val_pred = classifier.predict(x_vals, k=k)
k_accuracies.append(compute_accuracy(y_vals, y_val_pred))
k_to_accuracies[k] = k_accuracies
return k_to_accuracies
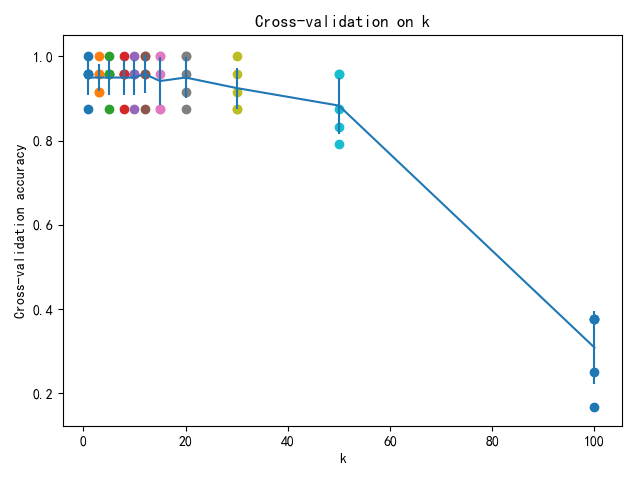
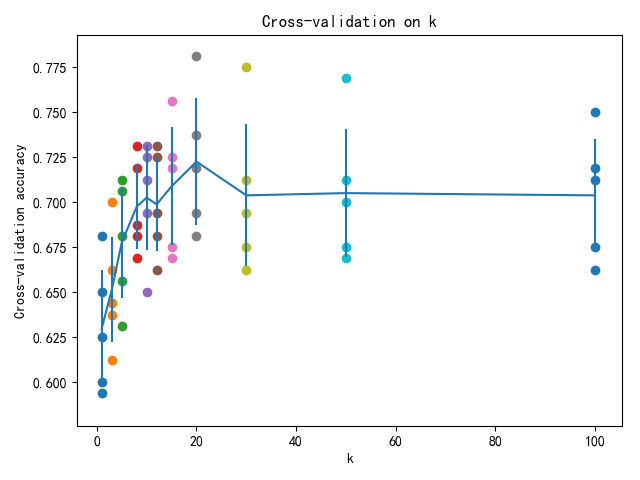
def plot(k_choices, k_to_accuracies):
# plot the raw observations
for k in k_choices:
accuracies = k_to_accuracies[k]
plt.scatter([k] * len(accuracies), accuracies)
# plot the trend line with error bars that correspond to standard deviation
accuracies_mean = np.array([np.mean(v) for k, v in sorted(k_to_accuracies.items())])
accuracies_std = np.array([np.std(v) for k, v in sorted(k_to_accuracies.items())])
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
plt.title('Cross-validation on k')
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.show()
if __name__ == '__main__':
# iris_path = '/home/zj/data/iris-species/Iris.csv'
# x_train, x_test, y_train, y_test = load_iris(iris_path, shuffle=True, tsize=0.8)
data_path = '/home/zj/data/german/german.data-numeric'
x_train, x_test, y_train, y_test = load_german_data(data_path, shuffle=True, tsize=0.8)
x_train = x_train.astype(np.double)
x_test = x_test.astype(np.double)
mu = np.mean(x_train, axis=0)
var = np.var(x_train, axis=0)
eps = 1e-8
x_train = (x_train - mu) / np.sqrt(var + eps)
x_test = (x_test - mu) / np.sqrt(var + eps)
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 30, 50, 100]
k_to_accuracies = cross_validation(x_train, y_train, k_choices)
# print(k_to_accuracies)
# Print out the computed accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))
plot(k_choices, k_to_accuracies)
accuracies_mean = np.array([np.mean(v) for k, v in sorted(k_to_accuracies.items())])
k = k_choices[np.argmax(accuracies_mean)]
print('最好的k值是:%d' % k)
# 测试集测试
classifier = KNN()
classifier.train(x_train, y_train)
y_test_pred = classifier.predict(x_test, k=k)
y_test_acc = compute_accuracy(y_test, y_test_pred)
print('测试集精度为:%f' % y_test_acc)
|