卷积神经网络推导-单张图片矩阵计算
以LeNet-5为例,进行卷积神经网络的矩阵推导
计算符号
参考lecun-98,卷积层标记为
LeNet-5简介
LeNet-5共有7层(不包含输入层)
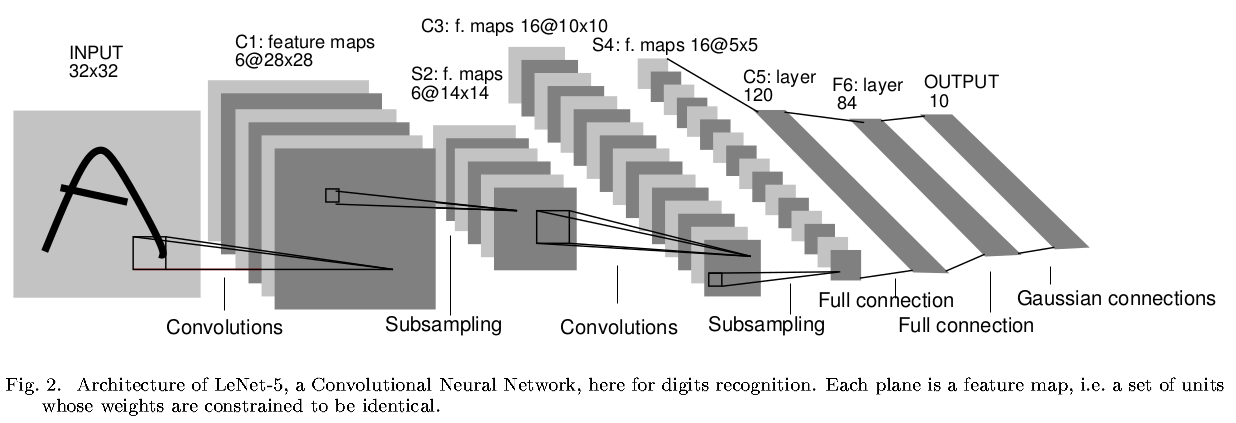
有 6个滤波器,感受野尺寸为,步长为 ,零填充为 ,所以 共有 个训练参数,输出激活图尺寸为 感受野大小为 ,步长为 ,将输入数据体4个神经元相加后乘以一个可训练参数,再加上一个偏置值,最后进行 操作,所以 共有 个训练参数,输出激活图尺寸为 有 16个滤波器,感受野尺寸为,步长为 , 零填充为 ,所以输出激活图尺寸为 的滤波器没有和 完全连接:前6个滤波器和 连续的3个激活图交互,接下来6个滤波器和 连续的4个激活图交互,接下来3个滤波器和 不连续的4个激活图交互,最后一个滤波器和 全连接 的参数个数是
和 一样,所以共有 个可学习参数,输出激活图尺寸为 有 120个滤波器,感受野大小为,步长为 ,零填充为 ,所以 共有 个参数,输出激活图尺寸为 ,输出大小为 有 84个神经元,激活函数是,参数个数是 个训练参数 有 10个神经元,得到84个输入后,不再执行点积运算,而是执行欧氏径向基函数(euclidean radial basis function):
损失函数是均方误差(
Mean Squared Error, MSE)
最早的LeNet-5在1998年提出,经过多年发展,一些实现细节发生了变化,其中一个版本如下
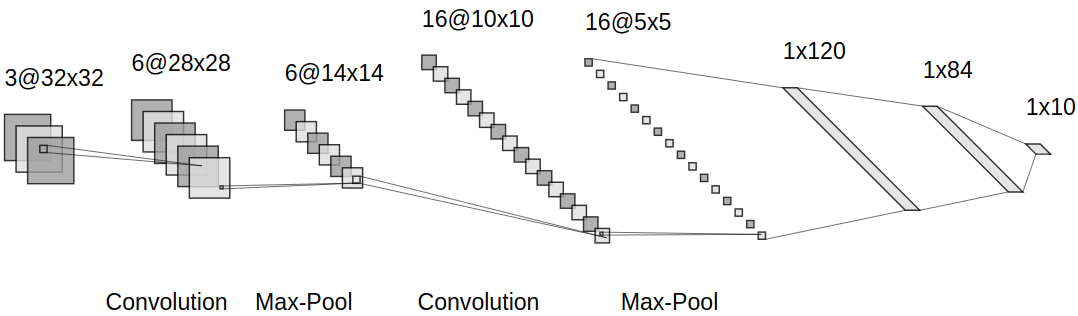
有 6个滤波器,感受野尺寸为,步长为 ,零填充为 ,激活函数是 ,所以 共有 个训练参数,输出激活图尺寸为 感受野大小为 ,步长为 ,使用 运算,所以输出激活图尺寸为 有 16个滤波器,感受野尺寸为,步长为 , 零填充为 ,激活函数是 ,所以 参数个数是 ,输出激活图尺寸为 和 一样,步长为 ,使用 运算,所以输出激活图尺寸为 有 120个滤波器,感受野大小为,步长为 ,零填充为 ,激活函数为 ,所以 共有 ,输出激活图尺寸为 ,输出大小为 有 84个神经元,激活函数是,参数个数是 个训练参数,输出大小为 有 10个神经元,参数个数是个,输出大小为 评分函数使用
损失函数是交叉熵损失(
Cross Entropy Loss)
| 输入 | 卷积核 | 步长 | 零填充 | 输出 | |
|---|---|---|---|---|---|
| C1 | 32x32x3 | 5x5 | 1 | 0 | 28x28x6 |
| S2 | 28x28x6 | 2x2 | 2 | \ | 14x14x6 |
| C3 | 14x14x6 | 5x5 | 1 | 0 | 10x10x16 |
| S4 | 10x10x16 | 2x2 | 2 | \ | 5x5x16 |
| C5 | 5x5x16 | 120 | 0 | 0 | 1x120 |
| F6 | 1x120 | 84 | \ | \ | 1x84 |
| F7 | 1x84 | 10 | \ | \ | 1x10 |
卷积层转全连接层
参考:Implementation as Matrix Multiplication
卷积层滤波器在输入数据体的局部区域执行点积操作,将每次局部连接数据体拉伸为行向量,那么卷积操作就等同于矩阵乘法,变成全连接层运算
比如输入图像大小为
那么等同于全连接层的输入维度为
得到输出数据
池化层转全连接层
池化层滤波器在输入数据体的激活图上执行
比如输入数据体大小为
那么每次连接的向量大小是
得到输出数据
矩阵计算
进行MNIST数据集的分类
前向传播
输入层
卷积层
共6个滤波器,每个滤波器空间尺寸为
输出空间尺寸为
所以单次卷积操作的向量大小为
输出数据体
池化层
执行
输出空间尺寸为
所以单次
输出数据体
卷积层
共16个滤波器,每个滤波器空间尺寸为
输出空间尺寸为
所以单次卷积操作的向量大小为
输出数据体
池化层
执行
输出空间尺寸为
所以单次
输出数据体
卷积层
共120个滤波器,每个滤波器空间尺寸为
输出空间尺寸为
所以单次卷积操作的向量大小为
输出数据体
全连接层
神经元个数为
输出数据体
输出层
神经元个数为
输出数据体
分类概率
损失值
1, 其余为0
反向传播
输出层
求输入向量
其他梯度
求权重矩阵
求偏置向量
求上一层输出向量
全连接层
求输入向量
其他梯度
求权重矩阵
求偏置向量
求上一层输出向量
卷积层
求输入向量
其他梯度
求权重矩阵
求偏置向量
求上一层输出向量
池化层
将
因为卷积层
求输入向量
上一层输出向量
配合
卷积层
将
求输入向量
$$
d(dataloss)
=tr(D_{y^{(3)}}f(y^{(3)})\cdot dy^{(3)})\
=tr(D_{y^{(3)}}f(y^{(3)})\cdot (1(z^{(3)} \geq 0)dz^{(3)}))\
=tr(D_{y^{(3)}}f(y^{(3)}) 1(z^{(3)} \geq 0)^{T}\cdot dz^{(3)})
$$
其他梯度
求权重矩阵
求偏置向量
求上一层输出向量
池化层
上一层输出向量
配合
卷积层
将
求输入向量
$$
d(dataloss)
=tr(D_{y^{(1)}}f(y^{(1)})\cdot dy^{(1)})\
=tr(D_{y^{(1)}}f(y^{(1)})\cdot (1(z^{(1)} \geq 0)dz^{(1)}))\
=tr(D_{y^{(1)}}f(y^{(1)}) 1(z^{(1)} \geq 0)^{T}\cdot dz^{(1)})
$$
其他梯度
求权重矩阵
求偏置向量