可视化理解卷积神经网络
文章Visualizing and Understanding Convolutional Networks提出一种可视化方法来观察中间层特征,以此发现不同模型层的性能分布,调整AlexNet参数的得到的ZFNet模型在ImageNet上得到了更好的分类性能;通过预训练ImageNet模型测试发现预训练大数据库能够提高模型的泛化能力
可视化技术
卷积神经网络能够很好的执行分类、识别、检测等功能,但是对于其中原理和变化过程一直没有很好的解释
文章设计一种可视化技术研究中间特征层和分类器的操作,总结不同模型层的特征贡献
主要探究以下两个问题:
- 为什么大型卷积网络模型执行结果如此好?
- 它们怎么样可以提高?
多层反卷积网络
可视化技术是通过多层反卷积网络(Multi-Layered Deconvolutional Network, deconvnet)实现的,其目的是反向映射中间特征层激活到原始像素空间(map these activities back to the input pixel space)
反卷积网络可以看成是一个卷积网络模型,同样拥有卷积、池化、激活等操作,区别在于其执行反向操作,将特征映射回像素,对应关系如下:
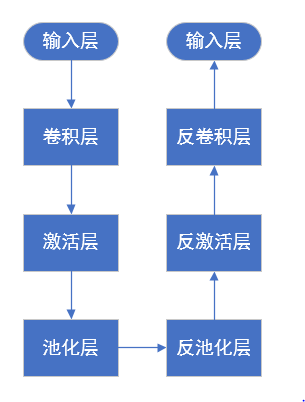
卷积网络模型和对应反卷积网络模型的前3层如上所示,卷积网络的每一层在反卷积网络中都有对应反向操作
反卷积过程:卷积网络和反卷积网络每层一一对应
第一步:将数据输入到卷积网络,逐层计算特征
第二步:为探究中间特征层激活,选择其中一个激活图,选取其中响应最大的激活值,设置该层其他激活为0,输入特征到绑定的反卷积层
第三步:执行反池化、反激活、反卷积,重构上一层的激活区域
第四步:重复步骤3,直到回到输入像素空间
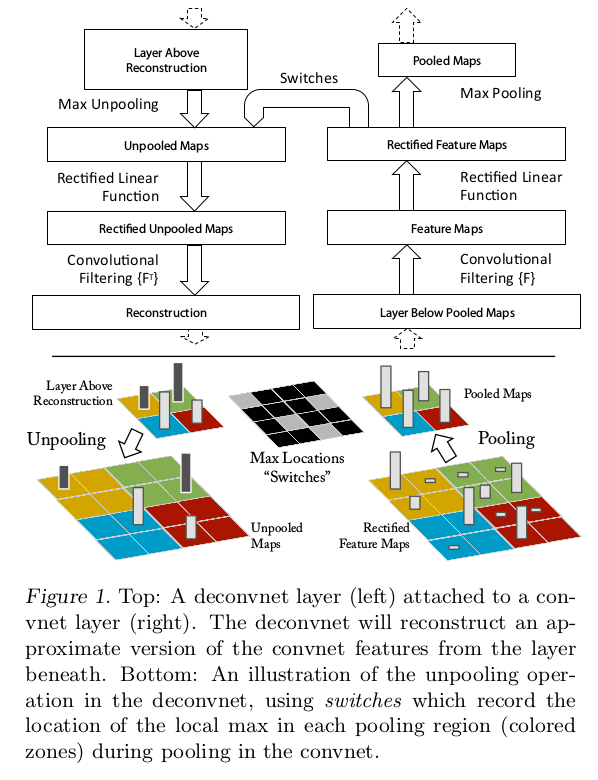
完整的反卷积过程相当于反向传播梯度,区别在于:
- 独立执行激活函数
- 不使用任何反向正则化操作
反池化
反池化(unpool)操作将激活区域反向映射到池化层输入向量的最大值坐标上
在前向最大池化层操作过程中,设置一个变量switch来记录最大值坐标,在反池化(unpool)操作时,将特征重新映射到最大值对应位置
反激活
反激活操作和激活操作一样,使用对应激活层的激活函数即可,比如relu激活
反卷积
使用对应卷积层滤波器的转置版本(transposed version),即水平和垂直翻转滤波器
特征分析
特征可视化
使用AlexNet在ImageNet上训练完成后,选取特征图中前9个响应最大的激活点,反向卷积到输入像素空间


从图中可看出卷积网络特征演化过程
- 第
2层响应角(corner)和其他边缘/颜色连接(edge/color conjunction) - 第
3层有更复杂的不变性(complex invariance),能够捕捉相似的纹理 - 第
4层更多显示的是基于类(class-specific)的不变性 - 第
5层显示具有显著姿势变化(pose variation)的整个对象
特征演化
下图演示了各层最强激活点所表示的对应特征在训练过程中的变化

上图中每一行表示指定激活图中最强特征点在不同迭代次数下(1/2/5/10/20/30/40/64)的变化
从图中可以看出,底层特征在最开始几轮就已经拟合,高层特征需要更多的迭代过程(上图是40-50轮)才开始拟合
特征不变性
下图采样了5张图像,分别进行不同程度的平移(translated)、旋转(rotated)和缩放(scaled),观察其特征向量的变化
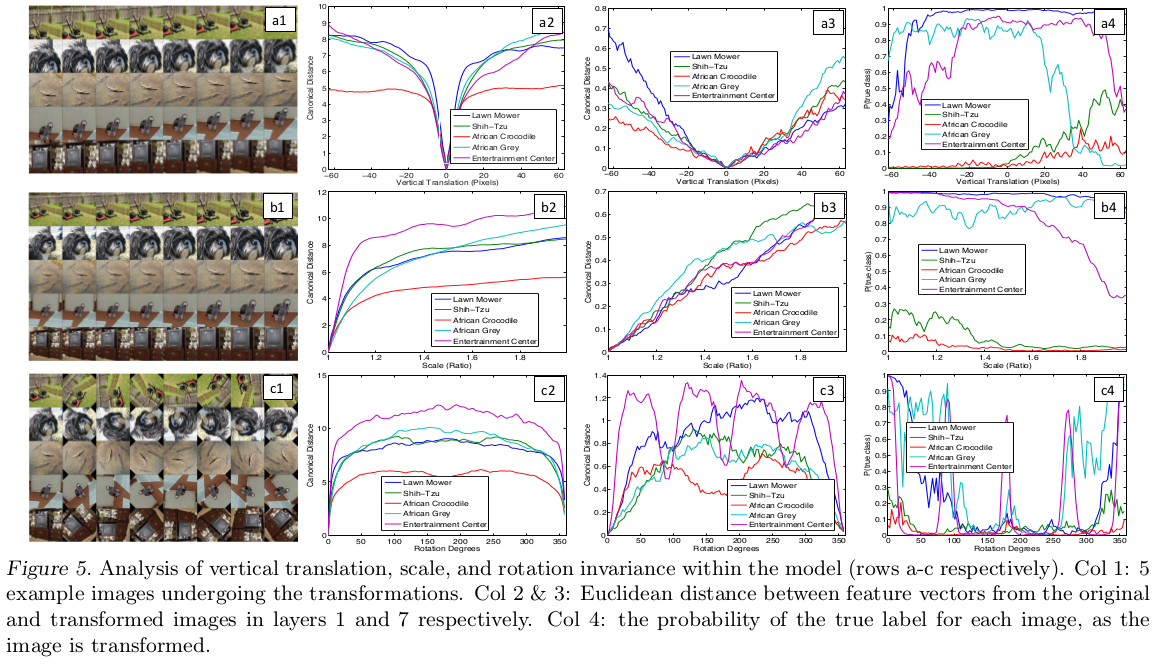
模型对平移和缩放的不变性最好,也能够很好的支持旋转,除非是旋转对称的对象
敏感度分析
执行一个遮蔽敏感性(Occlusion Sensitivity)分析,通过遮掩输入图像的部分区域,揭示哪部分场景对于分类而言是重要的
文章图7给出了示例,不过我没看懂,它的示例图像比较乱,总结起来有以下两点:
- 分类结果依赖于图像中的对象而不是图像对象的上下文环境
- 当原始图像中对应于激活部分被遮掩时,可以看到特征图中明显的活动下降
一致性分析
深度模型(deep model)没有显式建立特定对象部分之间的对应关系(比如脸部中的眼睛、鼻子),文章通过实验测试深度模型是否会隐式建立不同图像特定目标之间的对应关系

随机选择5张不同的狗脸图像,遮掩住脸部同一区域进行比对(比如都遮掩住右眼)
首先计算原始图像和遮掩后的图像误差
然后计算不同误差之间的一致性
文章共比较了第5层和第7层的特征,遮掩了左眼、右眼、鼻子和随机部分,结果如下
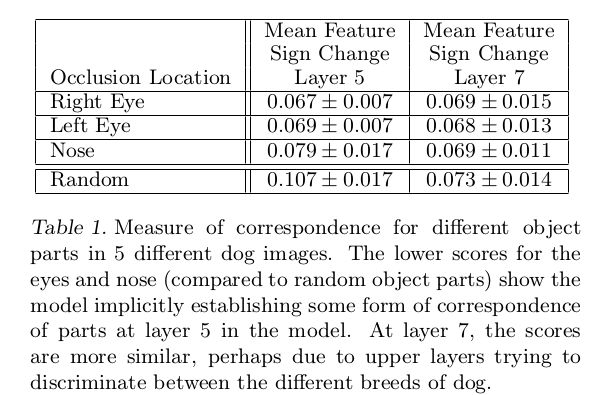
相对于随机遮掩的结果,遮掩指定脸部区域能够得到更小的值,表明模型确实建立了一定程度的对应关系
ZFNet
AlexNet模型分析
可视化AlexNet第一和第二卷积层如下

第一层特征可视化显示滤波器采集的是极度高频和低频(extremely high and low frequency)的图像信息,很少涉及中频(the mid frequencies)信息(图b)
第二层可视化显示了第一层卷积中使用的大步长导致的混淆现象(aliasing artifacts)(图d)
调整第一个卷积层参数
- 滤波器大小:
11 -> 7 - 滤波器步长:
4 -> 2
结果如图c/e所示,第一、二层能够得到更多的信息,能够进一步提高检测能力
高频、中频和低频信息
灰度变化慢的是低频信息,是图像颜色渐变区域;灰度变化快的是高频信息,比如图像边缘轮廓和噪声;夹在中间的是中频信息
中频信息确定了图像基本轮廓结构,高频信息强化对轮廓的细节,低频信息补充了轮廓的内容
ZFNet模型
通过分析AlexNet模型,修改第一二卷积层的模型参数,得到ZFNet模型
- 第一层的滤波器大小修改为7x7
- 第一和第二个卷积层的步长修改为2
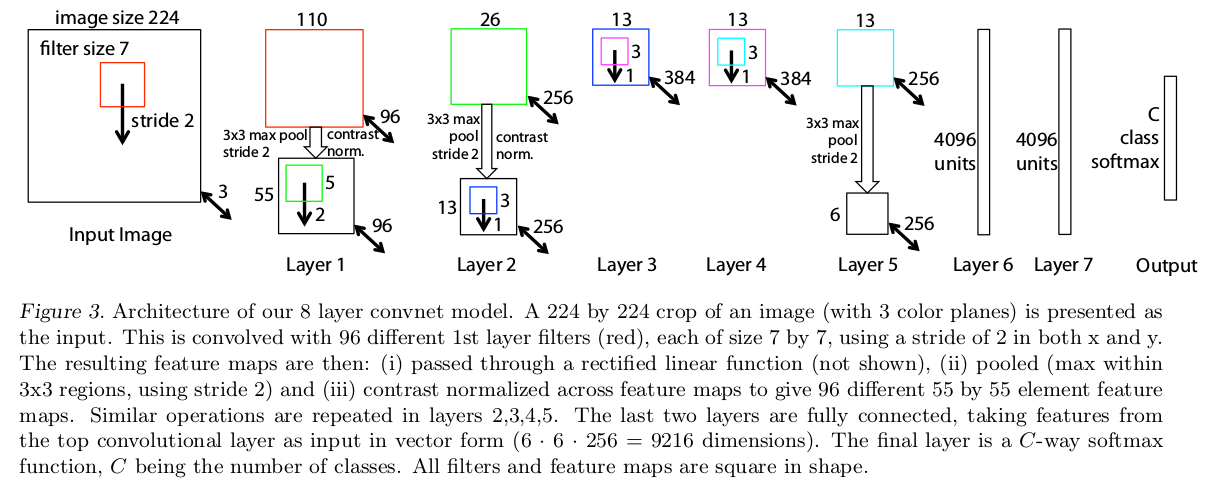
ZFNet性能分析
文章使用ImageNet 2011和2012训练集,使用AlexNet和ZFNet模型,比较单个网络和集成多个网络平均结果的性能
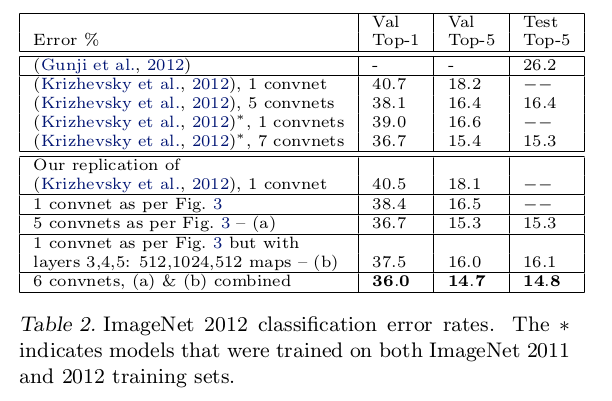
- ZFNet模型比AlexNet模型实现更好的结果(
(Krizhevsky et al., 2012), 1 convnetvs1 convnet as per Fig. 3) - 集成多个
ZFNet模型能够实现更好的结果(6 convnets, (a) & (b) combined)
网络大小分析
文章对AlexNet和ZFNet进行中间层移除和修改实验,表明模型的整体深度对于获得良好的性能很重要
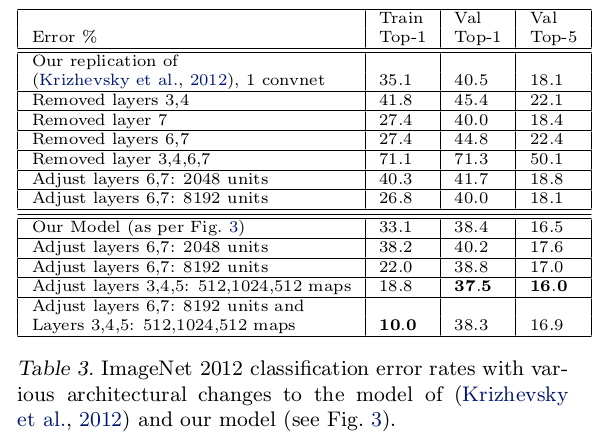
- 删除
AlexNet卷积层或全连接层会提高误差率 - 增大
ZFNet卷积层或全连接层能够减少误差率
模型泛化
文章利用ImageNet训练ZFNet模型,然后保持1-7层模型参数,使用其他数据库重新训练softmax分类器,表明在卷积层中学习到的特性有很好的迁移能力
数据库
- ImageNet:超过1百万张图像和超过1000个类
- Caltech 101:共有101类,每类40-800张
- Caltech 256:共256类,每类80-827张
- Pascal VOC:多目标图像
比较方式
比较两个方面
- 保证
1-7层参数不变,仅重训练softmax分类器和初始化所有层参数,重新训练分类器的比较 ZFNet模型和之前最好检测结果比较
比较结果
在Caltech-101和Caltech-256数据库上,使用预训练模型能够达到最好的检测结果,重训练模型实现精度远远不及之前最好检测结果
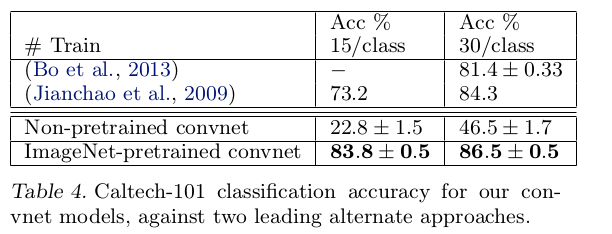
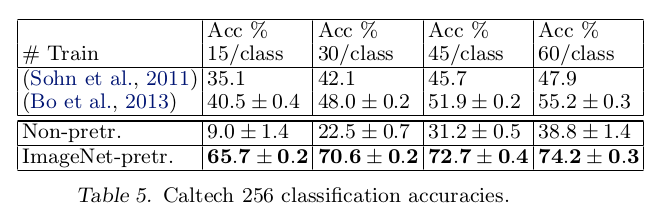
- 利用
ImageNet训练的特征提取器的强大性能 - 小数据集无法提高深度模型检测能力
在PASCAL-2012数据集上进行训练和测试发现,使用预训练模型无法实现理想的效果
理由:PASCAL数据库(多目标)和ImageNet数据库(单目标)的使用场景不一致。在包含多对象的图像中进行检测,基于ImageNet预训练的分类器不适用
小结
本文提出的可视化技术有以下优点:
- 能够帮助我们观察到特征在训练过程中的演化以及诊断模型潜在的问题,说明特征是可理解的
- 通过平移、旋转和缩放实验表明模型在对象变化过程中对平移和旋转有很好的鲁棒性,对缩放也有一定的不变性
- 通过一系列的遮挡实验证明模型在经过分类训练后,对图像中的局部结构高度敏感,而不是依赖于场景上下文
可视化技术缺点在于仅可视化单个激活,不涉及多层激活图之间的连接
通过可视化技术的应用有以下发现:
- 大滤波器缺少对中频信息(图像基本结构)的采集
- 大步长会导致特征混淆现象
- 底层特征在训练过程中易于收敛,高层特征需要更多轮迭代才能完成
- 特征的演化经历从细节到整体的过程
对AlexNet模型的第一二层卷积层减小滤波器大小和步长,得到的ZFNet模型在ImageNet数据集上有更好的性能
通过调整模型大小和层数发现:
- 模型架构深度有助于性能提升
- 改变全连接层大小对性能影响不大
- 增加中间隐藏层的大小有助于性能提升
- 同时扩大隐藏层和全连接层会导致过拟合
- 多模型集成有助于提高性能
通过多数据库训练和测试发现:
- 大数据集有助于提高深度模型检测能力和泛化能力
- 不同场景数据集复用效果不强
通过对以上内容的分析,下面的方向是未来模型性能提高的方向
- 更大的数据库
- 更深更大的网络模型
2.1 更好的模型归一化策略
2.2 小的滤波器大小和步长