Aggregating Deep Convolutional Features for Image Retrieval
原文地址:Aggregating Deep Convolutional Features for Image Retrieval
摘要
Several recent works have shown that image descriptors produced by deep convolutional neural networks provide state-of-the-art performance for image classification and retrieval problems. It has also been shown that the activations from the convolutional layers can be interpreted as local features describing particular image regions. These local features can be aggregated using aggregation approaches developed for local features (e.g. Fisher vectors), thus providing new powerful global descriptors.
In this paper we investigate possible ways to aggregate local deep features to produce compact global descriptors for image retrieval. First, we show that deep features and traditional hand-engineered features have quite different distributions of pairwise similarities, hence existing aggregation methods have to be carefully re-evaluated. Such re-evaluation reveals that in contrast to shallow features, the simple aggregation method based on sum pooling provides arguably the best performance for deep convolutional features. This method is efficient, has few parameters, and bears little risk of overfitting when e.g. learning the PCA matrix. Overall, the new compact global descriptor improves the state-of-the-art on four common benchmarks considerably.
最近的一些研究表明深度卷积神经网络产生的图像描述符为图像分类和检索问题提供了最先进的性能。同时研究还表明来自卷积层的激活可以解释为描述特定图像区域的局部特征。这些局部特征可以使用为局部特征(例如Fisher向量)开发的聚合方法进行聚合,从而提供新的强大的全局描述符。
在本文中,我们研究了聚集局部深度特征以生成用于图像检索的紧凑全局描述符的可能方法。首先,我们证明了深度卷积特征和传统人工设计的特征具有完全不同的成对相似性分布,因此必须仔细重新评估现有的聚合方法。重新评估表明,与浅层特征相比,基于求和池化的简单聚合方法就可以为深层卷积特征提供最好的性能。这种方法效率高,参数少,在后处理过程(比如学习PCA矩阵)中过拟合的风险很小。总的来说,新的紧凑型全局描述符大大提高了四个通用基准数据集的最高检索精度。
引言
一些工作使用深度神经网络最后全连接层的输出作为特征描述符,在描述符维度受限的情况下能够实现最好的性能。接下来的研究注意力迁移到了CNN模型的卷积层特征(论文称之为深度卷积特征(deep convolutional features))。深度卷积特征拥有如下特性:
- 可以将任意大小和长宽比的图像作为输入;
- 可以自然地解释为与特定特征的感受野相对应的局部图像区域的描述符。
之前的论文将深度特征类比为人工设计局部特征的集合,这样就可以复用传统的嵌入和聚合框架(embedding-and-aggregation frameworks),使用诸如VLAD/Fisher向量/三角嵌入(VLAD, Fisher vectors or triangular embedding)等聚合方法将深度卷积特征构造成全局图像描述符。
论文首先将传统的聚合算法与求和池化(sum pooling)以及最大池化(max pooling)方法进行比较,通过实验表明使用求和池化得到的特征描述符(SPoC descriptors)能够获取到最好的性能。将求和池化方法应用于SIFT算法提取的特征并不能获取很好的性能,论文进一步验证了深度卷积特征和传统人工特征之间存在极大的差异性,并且证明了不需要再执行嵌入步骤。
相关
从图像SIFT特征),然后将这组局部特征聚合成为一个全局描述符PCA降维操作。
全局描述符的构造通常分为两步进行:嵌入(embedding)和聚合(aggregation)(PCA这些属于后处理了)。嵌入阶段将不同的局部特征
常用构造算法(VLAD/Fisher Vector/ Triangular Embedding)的主要差别在于嵌入阶段如何将局部特征
但是抑制高维向量计算的假阳性会出现其他缺陷。首先,这种嵌入方法同样会抑制真阳性结果;其次,嵌入方法需要学习很多参数,如果训练集数据分布和测试集数据分布不同时,会造成过拟合现象;另外,需要非常多的高维特征向量去学习可靠的PCA和白化矩阵;最后,与后续更简单的聚合操作相比,高维向量的嵌入操作计算上更加耗时。
虽然存在上述缺陷,但是对于人工设计特征而言,高维嵌入操作仍旧是必须执行的。如果没有这个操作,全局描述符的性能将非常低。论文通过实验证明原始的深度卷积特征已经拥有足够强大的判别能力,不再需要高维嵌入步骤,消除嵌入步骤可以简化计算流程,能够更快速的完成计算,不存在过拟合问题,并且实现了最好的图像检索性能。
深度特征聚合
论文首先比较了深度卷积特征和SIFTs之间的差异性,然后提出一种新的全局特征描述符,消除了嵌入步骤。假定将图像
深度特征 vs. 人工特征
已经有论文分析了直接使用原始SIFT特征计算相似度是不准确的,不相关的图像之间也可能出现非常高的相似度,所以需要高计算量的嵌入步骤。论文通过两个实验证明深度特征相比于人工设计特征具有更强的判别能力,可以跳过嵌入步骤。
实验一:
- 在
Oxford5k数据集中,分别提取深度特征以及密集SIFT特征; - 使用
Fisher Vector将SIFT特征嵌入到64个components(不了解FV的实现)得到嵌入SIFT特征; - 使用不同的特征类型(深度特征,原始
SIFT以及嵌入SIFT),使用余弦相似度计算查询图像和参考图像; - 随机选择几个查询图像,可视化基于相似度排序的前
10个匹配图像。如下图1所示。

从图1中可知,深度特征能够获取得到最少的假阳性检索结果,基于SIFT特征进行匹配的效果最差,而基于FV的SIFT嵌入特征提高了匹配性能,不过依旧差于深度特征匹配。
实验二:
首先通过实验证明深度特征中拥有最高范数的特征向量具有更强的判别能力。随机选择两组特征(其实有点没弄明白,说的是单个特征点还是一个特征图,应该是特征图,不过1%这个也太少了吧???)
- 随机抽取
1%特征向量; - 随机抽取
1%具有最高范数的特征向量。
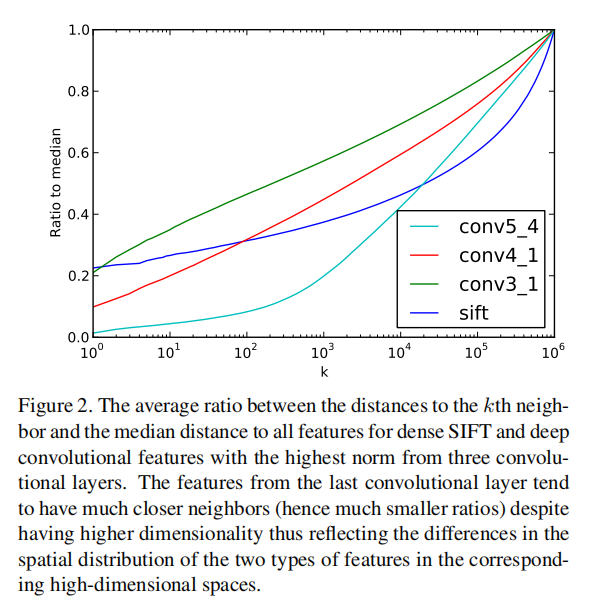
使用求和池化操作得到全局描述符后对Oxford5k数据集进行检索。对于条件1能够得到0.09 mAP,对于条件2能够得到0.34 mAP。这个实验证明了具有更大范数的特征比随机特征拥有更强的判别能力。接下来的实验有点绕口,就不介绍了,反正就是通过统计特性证明了深度特征和相似特征之间的距离和深度特征与随机特征之间的距离相比更小(也就是更相似);而SIFT特征的相似度更弱,说明SIFT特征缺少判别能力。如下图2所示,论文也比较了不同阶段的深度特征,表明更深层的深度特征具有更强的判别能力。
SPoC
论文设计了SPoC描述符,基于原始深度特征的聚合,不需要额外的嵌入操作。仅需求和池化操作即可聚合原始深度特征得到SPoC描述符:
求和池化
计算两个SPoC描述符的标量积即可表示为相似度:
居中优先
论文还提出了一个小trick:大部分情况下目标总是位于图像中心,SPoC描述符可以集成一个加权掩码,赋值图像中心的特征更大的权重。实现如下:
加权系数
论文设置超参数three sigma经验法则的启发。居中优先模式在某些数据集上能够进一步提升性能。
后处理
完成SPoC描述符计算后,还需要部分后处理操作,包括L2归一化、PCA降维以及白化操作。实现如下:
表示 个 PCA矩阵;表示降维后的向量大小; 表示降维前的向量大小,等同于卷积层输出特征图的数目; 表示相应的奇异值。
完成上述操作后,再进行L2归一化操作。
卷积层输出特征图的数目仅有几百维,而人工设计特征通常拥有更大维度,进行降维的过拟合风险更大。
实验
数据集
Holidays(INRIA Holidays dataset):拥有1491张图片,分为500个类别。测试时从每个类别中提取一张图片作为查询图像,计算500个查询的mAP。在测试之前,对于错误方向的建筑物手动进行了旋转修复(); Oxford5K(Oxford Buildings dataset):包含5062张图片,有55张查询图片(基于11个类别)。测试时计算这55次查询的mAP;Oxford105K(Oxford Buildings dataset+100K):包含了Oxford5K以及额外从Flickr添加的100K图片;UKB(University of Kentucky Benchmark dataset):包含10,200张室内图片,共有2550目标(每个目标4张图片)。测试时将所有图片依次作为查询图片,检索剩余图片,计算排序前四个检索结果中相同目标图像的平均数量。
实验细节
论文使用VGGNet作为卷积网络,所以最后输出特征图数目是SPoC描述符的特征维度固定为
聚合方法
论文为深度特征设计了SPoC描述符:求和池化、最大池化、Fisher Vector以及Triangulation embedding。使用不同聚合算法得到SPoC描述符后均通过PCA白化方式缩放到256维向量大小。最后执行L2归一化以及计算标量积相似度(等同于欧式距离)。
实验结果
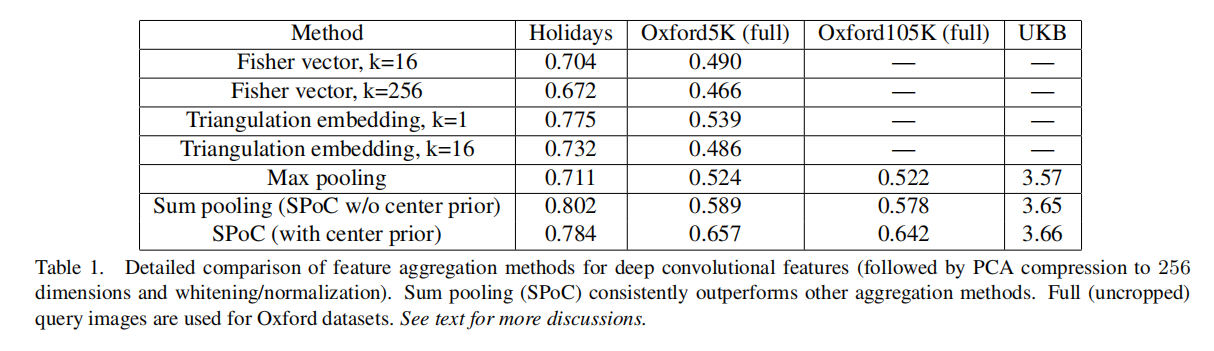
实验结果如上图所示:
- 基于求和池化构造的深度特征
SPoC描述符具有最好的性能。 - 居中优先策略在某些数据集上确实能够得到更好的效果(使用时应该根据实际场景进行判断是否加入)。
另外论文还实验了在测试集学习PCA转换矩阵后进行测试,如下表2所示:
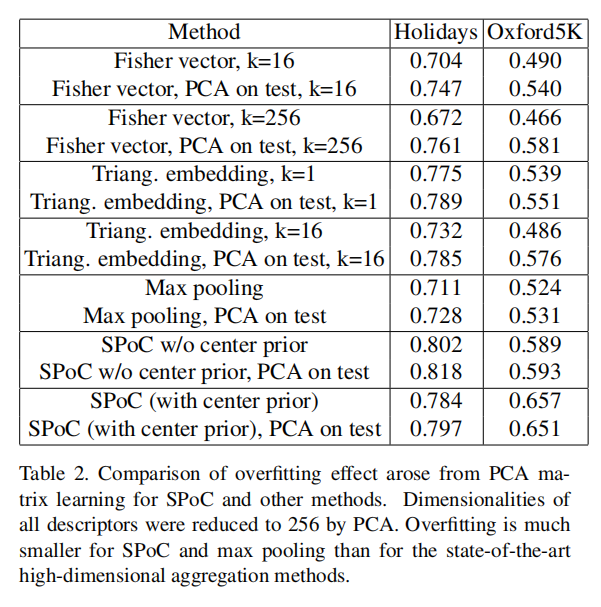
从试验结果来看,在测试集进行PCA学习后的人工特征构造的描述符的性能增益最大,说明其过拟合影响相比于深度特征而言更严重(注意:这个测试结果只是验证人工特征对于PCA降维的稳定性,不是用于证明泛化能力的哈,)。
论文还给出了以下两条结论,虽然没有发现相关的实验数据:
- 相比于最大池化,白化对于求和池化更有效:在
Oxford5K数据集上最大池化+白化能够得到0.48 mAP而不加白化能够得到0.52 mAP; PCA压缩能够提高深度特征性能:未压缩(仍旧有白化操作)的SPoC描述符能够得到0.55 mAP(Oxford5K)和0.796 mAP(Holidays),而压缩后能够得到0.59 mAP(Oxford5K)和0.802(Holidays)。


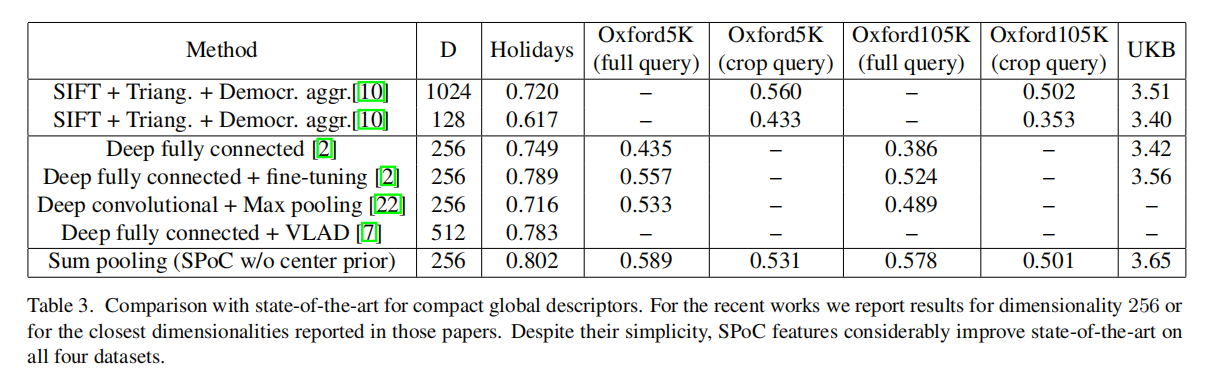
性能比较
小结
内容非常丰富的一篇论文,尤其是对于刚入门图像检索领域的童鞋,能够很好的了解如何从传统的人工特征描述符中构造得到全局特征描述符,以及为什么深度卷积特征描述符不需要遵循之前的嵌入和聚合框架。
论文通过实验分析了深度特征不同于之前的人工设计特征:原始的深度特征即具有强大的判别能力,不再需要额外计算的嵌入步骤;另外仅需求和池化进行聚合即可得到更好的性能。论文还研究了求和池化SPoC描述符对于PCA降维操作的过拟合风险很小,以及介绍了一些trick操作,包括居中优先加权掩码、白化操作、L2归一化以及标量积相似度计算。