End-to-end Learning of Deep Visual Representations for Image Retrieval
原文地址:End-to-end Learning of Deep Visual Representations for Image Retrieval
官方实现:naver/deep-image-retrieval
摘要
While deep learning has become a key ingredient in the top performing methods for many computer vision tasks, it has failed so far to bring similar improvements to instance-level image retrieval. In this article, we argue that reasons for the underwhelming results of deep methods on image retrieval are threefold: i) noisy training data, ii) inappropriate deep architecture, and iii) suboptimal training procedure. We address all three issues.
First, we leverage a large-scale but noisy landmark dataset and develop an automatic cleaning method that produces a suitable training set for deep retrieval. Second, we build on the recent R-MAC descriptor, show that it can be interpreted as a deep and differentiable architecture, and present improvements to enhance it. Last, we train this network with a siamese architecture that combines three streams with a triplet loss. At the end of the training process, the proposed architecture produces a global image representation in a single forward pass that is well suited for image retrieval. Extensive experiments show that our approach significantly outperforms previous retrieval approaches, including state-of-the-art methods based on costly local descriptor indexing and spatial verification. On Oxford 5k, Paris 6k and Holidays, we respectively report 94.7, 96.6, and 94.8 mean average precision. Our representations can also be heavily compressed using product quantization with little loss in accuracy. For additional material, please see www.xrce.xerox.com/Deep-Image-Retrieval.
虽然深度学习已经成为许多计算机视觉任务中最好方法的关键因素,但它迄今为止仍未能给实例级别图像检索任务带来类似的提升。在本文我们讨论了目前图像检索任务中深度方法效果不佳的原因,主要有三个:i) 噪声训练数据,ii) 不合适的深度架构,以及iii)次优的训练策略。我们解决了这三个问题。
首先,我们利用了一个大规模但存在噪声的地标数据集,开发出一种自动清洗方法能够提供适合于深度检索训练的数据集。其次,将最近提出的R-MAC描述符解释为一个深度可差分架构,并提出改进来增强它。最后,使用三元损失来训练卷积网络。完成训练后,所提出的网络架构仅需单次前向计算就可以得到适用于图像检索任务的全局图像表示。通过完备实验表明这种方式明显优于之前的检索算法,包括基于耗时的局部描述符索引和空间验证的最先进算法。在Oxford5k,Paris6k以及Holidays数据集中分别实现了94.7,96.6以及94.8的mAP。我们的特征向量也可以使用乘积量化进行大幅压缩,产生的精度损失很小。想要了解更多信息参考www.xrce.xerox.com/Deep-Image-Retrieval.
引言
图像检索的发展进程:首先是基于局部特征的传统图像算法;后面开始研究基于数据驱动的深度学习算法,
- 最开始使用基于
ImageNet分类任务预训练的卷积网络,提取全连接层特征进行图像检索; - 后续发展到使用卷积层特征(允许任意大小和长宽比的输入图像,同时能够进一步聚合卷积特征)进行图像检索;
- 最近热衷于针对特定图像检索任务进行微调训练的方式来提升检索性能。
分类任务和检索任务的差异性:
- 分类任务:区分不同语义类别,学习的特征对类内可变性具有鲁棒性;
- 检索任务:区分特定目标,学习的特征对同一语义类别的不同目标同样具有判别力。
论文的创新:结合卷积网络以及全局特征描述符一起加入训练,同时针对特定检索任务进行微调训练。
- 重构
R-MAC(regional maximum activations of convolutions)描述符,设计可微分操作并集成到卷积网络,- 通过训练学习得到最优参数;
- 单次前向计算即可得到全局特征向量;
- 在训练过程中使用三元损失(
triplet loss)显式优化网络权重; - 重构
R-MAC池化机制,替换多尺度均匀采样固定大小区域进行特征池化的方式,使用RPN(region proposal network)基于图像内容选择候选区域; - 利用大规模噪声数据集
Landmarks进行检索任务训练,同时设计一套清洗流程,自动舍弃错误标记图像以及自动标注真值区域。 - 评估全局特征描述符结合后处理运算(查询扩展以及数据端特征增强)的性能;
- 评估基于
PCA或者基于向量量化进行特征压缩的性能。
数据集创建
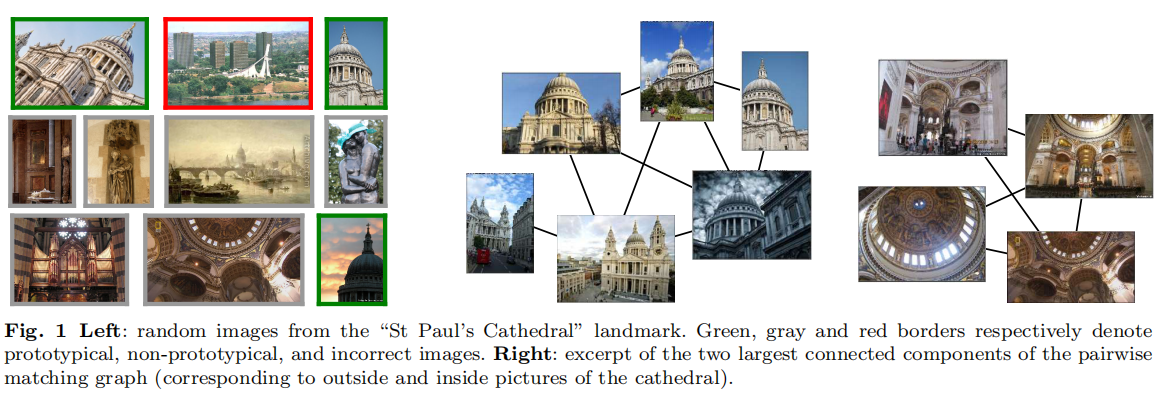
论文使用Landmarks进行检索任务训练。由于该数据集(称为Landmarks-full)是通过图像搜索引擎进行文字查询获取得到的,所以存在大量的错误标记结果。论文对此设计了一套自动清洗流程,能够舍弃错误标记图像同时自动标注感兴趣区域,获取得到的清洗版本称为Landmarks-clean。
端到端训练
原始R-MAC
- 基于
ImageNet预训练模型,提取卷积层特征; - 执行多尺度固定网格大小均匀采样,区域之间部分重叠,针对区域内卷积特征执行最大池化操作;
- 区域特征向量各自执行
L2归一化、PCA白化以及L2归一化; - 求和池化所有区域特征向量,最后执行
L2归一化。
对两幅图像的R-MAC特征向量执行点积运算,相当于加权的多对多区域匹配操作,其中权重等同于全局特征描述符的范数大小。
重构R-MAC
论文将R-MAC运算重构为可微分操作,集成到卷积网络中,
- 在不同候选区域上执行空间池化操作类似于
ROI(Region of Interest)池化; PCA投影可以看成是一次偏移操作(均值中心化/mean centering)加上全连接层运算(投影到指定维度的特征向量);- 区域特征向量之间的求和池化操作以及
L2归一化操作都是可微分的。
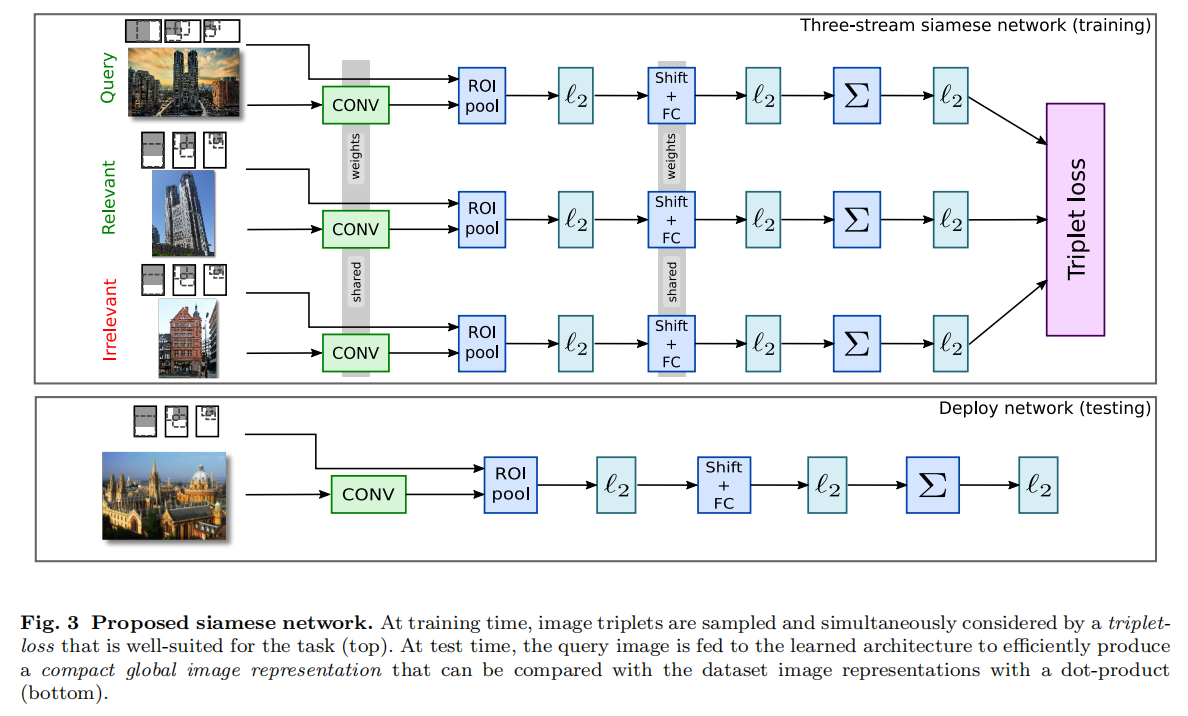
排序损失
假定查询图像R-MAC描述符为R-MAC描述符为R-MAC描述符为
其中
实验
论文首先针对上述改进进行了测试,使用4个基准数据集:
Oxford5k:查询集使用标注区域,同时查询集包含在特征数据集中,计算mAP;Paris6k:查询集使用标注区域,同时查询集包含在特征数据集中,计算mAP;INRIA Holidays(校正图像方向版本):查询集使用完整区域,同时查询集从特征数据集中移除,计算mAP;UKB(the University of Kentucky Benchmark):查询集使用完整区域,同时查询集包含在特征数据集中,计算recall@4。
训练配置如下:
- 模型:
VGG16以及ResNet101,基于ImageNet预训练; - 数据集:
Google Landmarks; - 预处理:一些常规的数据增强操作;
- 超参数
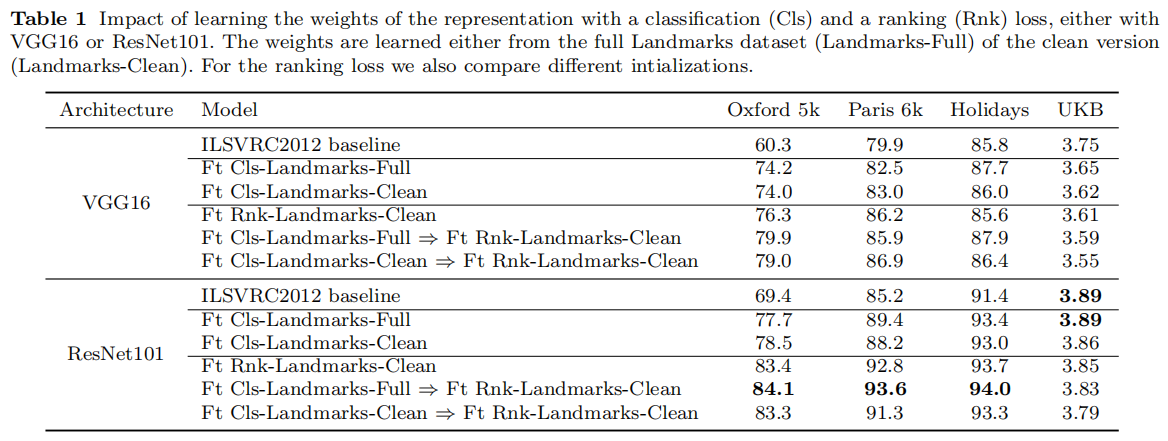
上表一描述了不同训练配置的测试结果:
- 进行微调分类训练能够切实提升性能,这种情况下使用
Landmarks-full和Landmarks-clean并没有差异性; - 使用集成
R-MAC的卷积网络进行微调检索训练(使用排序损失)能够获取最好性能; - 对于
VGG16而言,先使用Landmarks-full进行微调分类训练,然后使用Landmarks-clean进行微调检索训练可以获取最好性能; - 对于
ResNet101而言,从上表数据来看,同样是这个配置,不过论文也提出先进行分类训练的作用很小,具体训练趋势看图4所示。
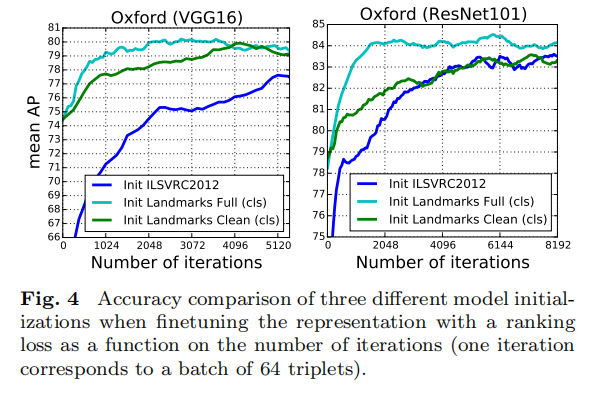
- 对于
UKB数据集而言,直接使用原始R-MAC描述符可以获取最好性能。论文分析跟数据集相关性有关; ResNet101相比于VGG16性能更强大,同时经过训练后能够带来更大的性能增益。
R-MAC优化
在上一节中论文将R-MAC描述符集成到卷积网络中,结合图像检索数据集以及排序损失进行联合训练。在本节中,论文进一步对R-MAC描述符进行优化:
- 利用
RPN(region proposal network)提升R-MAC描述符的区域池化机制; - 构建多分辨率
R-MAC描述符。
RPN
在原始R-MAC描述符的构造过程中,使用多尺度固定大小网格均匀采样候选区域,然后分别从卷积激活中提取区域特征进行嵌入和聚合操作。这种多尺度均匀采样的方式会造成两个问题:
- 候选区域并没有精确对齐感兴趣目标;
- 大部分候选区域有可能仅包含背景。
多尺度均匀采样的目的是为了确保感兴趣目标包含在候选区域中,R-MAC描述符比较可以看成是多对多区域匹配,而背景区域的采样会影响检索性能。与此同时,增大采样个数有可能获取到对齐感兴趣目标的区域,但同时增加了不相关区域的数目。
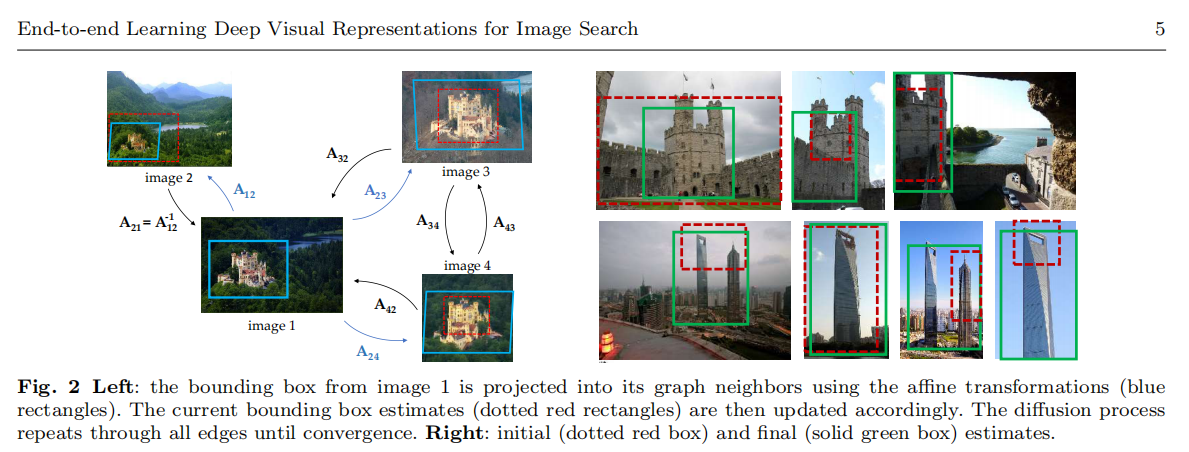
论文提出使用RPN进行目标区域的提取,这样可以实现候选区域和感兴趣目标的精确对齐。RPN是一个全卷积网络,首先是一个NMS(Non-maximum suppression)再次进行过滤,最后采样
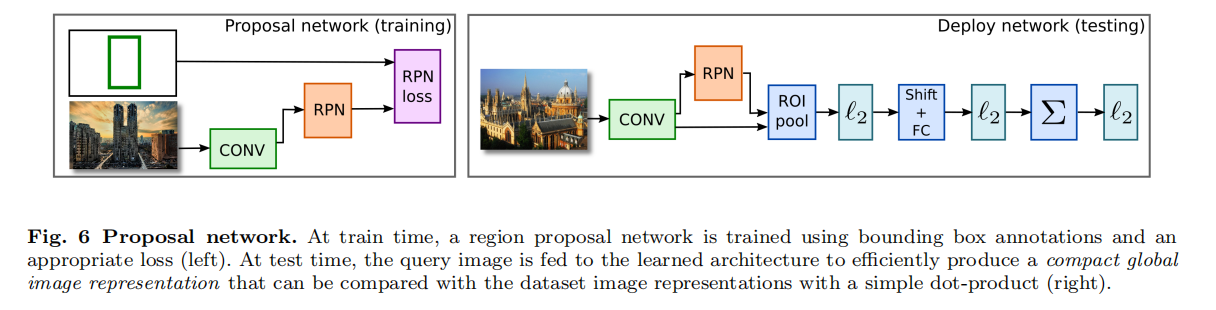
在训练过程中,论文首先采用均匀采样网格的方式训练特征网络和R-MAC描述符,然后固定卷积层权重,训练RPN网络,其实现如下图6所示。目标函数是一个多任务损失,包含了一个分类损失(log loss,判别目标和背景类别)和一个回归损失(smooth L1,预测区域坐标)。
多分辨率
论文还尝试了缩放图像到不同尺度,分别计算R-MAC描述符后进行聚合操作,试图通过构造多分辨率描述符来提高不同尺度目标图像的匹配。论文最终使用了3个尺度进行测试:550/800/1050,分别计算R-MAC描述符后进行求和操作,最后执行L2归一化操作。
实验
论文评估了RPN和多分辨率描述符的作用。首先是RPN,试验结果如表2所示:
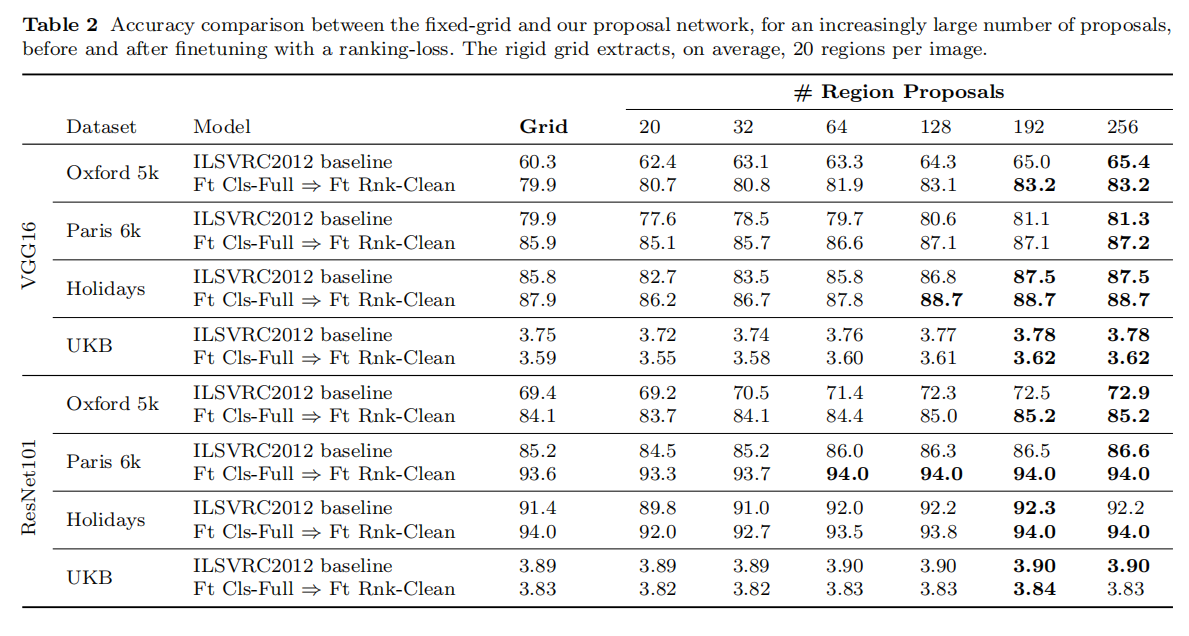
从实验结果来看,RPN对于VGG16的性能提升更高,而ResNet101能够实现最好的检索性能,使用均匀采样和使用RPN的差异性并不明显。论文给出的解释是ResNet101的特征提取能力更强,能够学习到更多区域的不变表示并且能够舍弃背景内容的影响。在后续论文使用中,不再针对ResNet101使用RPN。
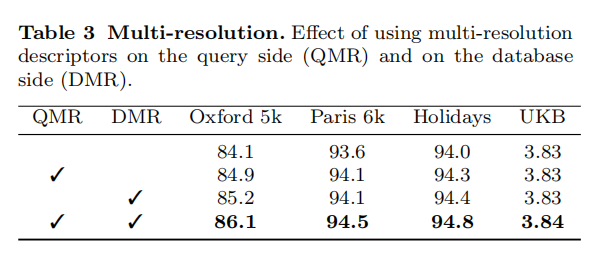
论文还评估了多分辨率设置的影响,分别将多分辨率设置应用到查询图像(QMR)、数据集图像(DMR)以及同时使用,如下表3所示。所有情况都提升了检索性能,表明多分辨率设置能够有效的提取图像特征,论文在后续实验中均应用了QMR和DMR设置。
后处理
论文评估了常用的后处理操作,包括查询扩展(query expansion(QE))和数据库端特征增强(database-side feature augmentation(DBA))。
查询扩展
基本操作如下:
- 初始排序:输入查询图像到卷积网络计算特征向量,分别与特征库数据两两计算后进行相似度排序,获取Top-K检索结果;
- 重排序:
- 首先对Top-k个检索特征进行空间校验(需要额外的局部关键点描述符),舍弃不匹配的特征;
- 然后将求和剩余检索特征以及查询特征,并重新进行归一化操作,生成新的查询特征;
- 使用新创建的查询特征再次对数据库特征(或者就是Top-k个特征)进行相似度排序,获取最后最终的Top-K检索结果。
数据库端特征增强
论文描述不太清晰,反正就类似于查询扩展操作,针对数据库的特征进行增强,具体操作如下:
- 数据库中每个特征与最相近的
个邻域执行求和方式聚合操作; - 可以基于邻域排序损失进行加权聚合,论文使用权重函数
,其中 表示邻域特征的排名, 表示整体邻域特征的数目。 - 对于新加入数据集的特征,可以在查询阶段就完成聚合操作。
实验
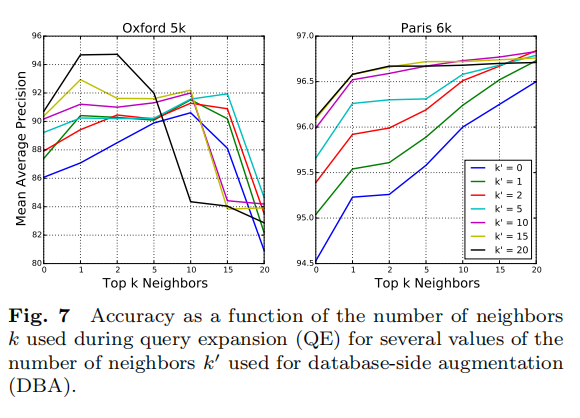
论文评估了基于QE和基于7所示。
- 对于
Oxford5k而言,每个查询拥有很少的正样本(少于10个甚至少于5个),所以增大值会降低性能; - 对于
Paris6k而言,每个查询拥有多个正样本,所以增大值一致性提高了性能; - 加权
DBA能够提高检索性能,并且和QE相互补充,前提是选择合适的值。
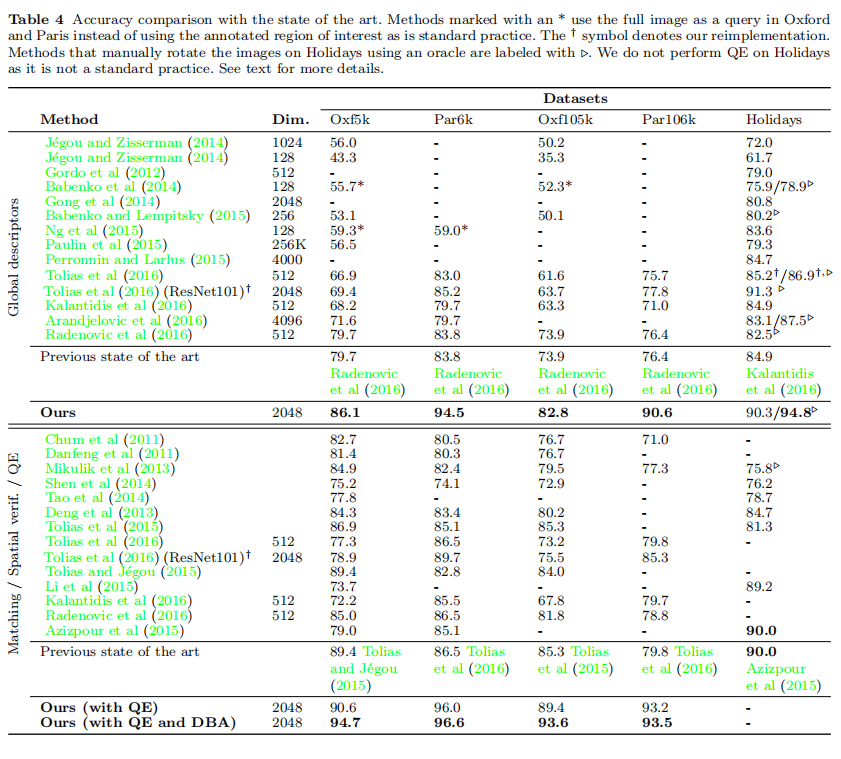
在论文最终的实验中,同时使用QE和DBA的情况下,固定QE时,设置4比较了所有最先进的检索算法,表格上部分比较了仅使用全局特征描述符进行图像检索的性能;表格下部分比较了完整算法的检索性能。
维度衰减
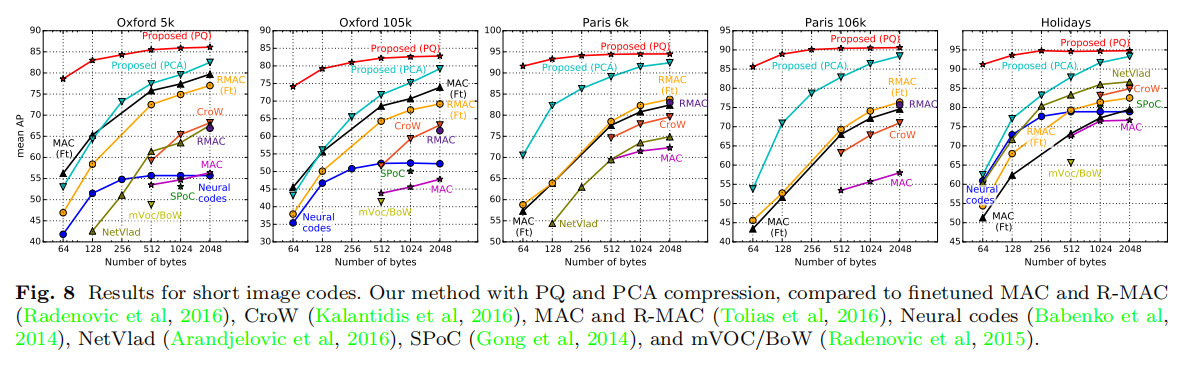
论文额外实验了两种压缩方式:主成分分析(principal component analysis (PCA))和向量量化(product quantization (PQ)),其参数均通过Landmarks-clean数据集学习得到。训练结果如下图8所示:
小结
论文大体上执行了三个方面的优化:
- 端到端学习:重构
R-MAC网络,集成到卷积网络中;清洗大规模噪声数据集;同时设计了三元损失进行检索任务训练; R-MAC描述符优化:使用RPN替代最开始的多尺度固定网格大小均匀采样方式;设计了多分辨率描述符加强特征向量的检索性能;- 后处理集成:执行
QE和DBA后处理运算;使用向量量化算法进行维度衰减。
这篇论文还是更多的侧重于工程化,集成了许多当时最先进的算法,包括RPN、QE/DBA和向量量化操作。相对而言比较有创新的R-MAC重构、大规模噪声数据集的清洗以及排序损失的设计,都已经在之前的论文Deep Image Retrieval: Learning global representations for image search中有所体现。
研读图像检索相关的论文已经有一段时间了,也认真的研究了好多检索算法的实现,可以发现图像检索任务与目标分类任务以及目标检测任务的发展息息相关:更强的分类模型以及更精确的定位算法都有助于检索算法的提高。与此同时,后处理算法的应用也提高了检索算法的性能。