[ROC][AUC]二分类任务评判标准
对于分类问题,最开始想到的评判标准就是检测准确率(accuracy),即样本检测类别和实际一致的数量占整个样本集的比率。进一步研究发现,还可以用更精细的标准来比较检测性能,学习步骤如下:
- 正样本和负样本
TP/FP/TN/FNTPR/FPR/FDR/PPV/ACCROC/AUC
正样本和负样本
在二分类问题中,将待识别的物体称为正样本(positive case),另外一个称为负样本(negative case)
TP/FP/TN/FN
对数据进行检测,能够得到以下4种检测结果
- 预测结果是正样本
- 实际是正样本,称为真阳性(
true positive,简称TP) - 实际是负样本,称为假阳性(
false positive, 简称FP)
- 实际是正样本,称为真阳性(
- 预测结果是负样本
- 实际是正样本,称为假阴性(
false negative,简称FN) - 实际是负样本,成为真阴性(
true negative, 简称TN)
- 实际是正样本,称为假阴性(
也就是说,根据预测情况决定预测结果是阳性还是阴性;根据预测结果和实际情况的比对决定预测结果是真还是假
| 实际 | ||||
|---|---|---|---|---|
| true | false | |||
| 预测 | positive | true positive(TP) | false positive(FP) | 正样本个数=TP+FP |
| negative | false negative(FN) | true negative(TN) | 负样本个数=FN+TN | |
| 实际正样本个数=TP+FN | 实际负样本个数=FP+TN | |||
所以实际为真的样本数
TPR/FPR/FDR/PPV/ACC
TPR/FPR
- 真阳性率(
TPR, true positive rate),也称为敏感度(sensitivity)、召回率(recall rate)、检测率(probability of detection),其计算的是检测为真的正样本在整个实际为真的样本集中的比率
- 假阳性率(
FPR, false positive rate),也称为误报率(probability of false alarm),其计算的是检测为假的正样本在整个实际为假的样本集中的比率
FDR和PPV
- 漏检率(
FDR, false discovery rate)计算的是假阳性样本占检测正样本集的比率
PPV(positive predictive value),也称为精度(precision),其计算的是检测为真的正样本占整个检测正样本集的比率
ACC
ACC(accuracy)就是指正确率,指的是真阳性和真阴性占整个样本集的比率
ROC/AUC
ROC
ROC全称是接受者操作特征曲线(receiver operating characteristic curve),它是一个二维曲线图,用于表明分类器的检测性能
其y轴表示TPR,x轴表示FPR。通过在不同阈值条件下计算(FPR, TPR)数据对,绘制得到ROC曲线
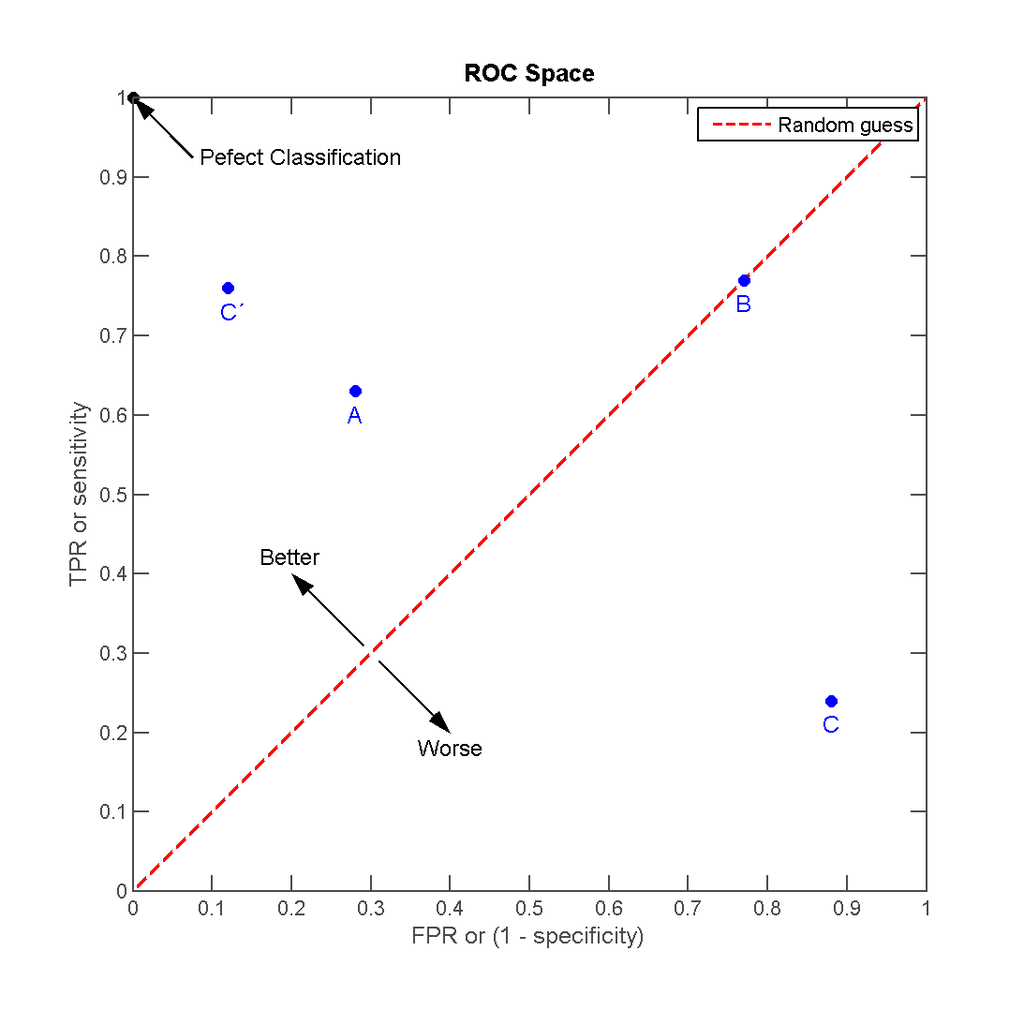
ROC描述了收益(true positive)和成本(false positive)之间的权衡。由上图可知
- 最好的预测结果发生在左上角
(0,1),此时所有预测为真的样本均为实际正样本,没有正样本被预测为假 - 对角线表示的是随机猜测(
random guess)的结果,对角线上方的坐标点表示分类器的检测结果比随机猜测好
所以离左上角越近,表示预测效果越好,此时分类器的性能更佳
AUC
AUC(area under the curve)指的是ROC曲线图中曲线下方的面积。其表示概率值,表示当随机给定一个正样本和一个负样本,分类器输出该正样本为正的那个概率值比分类器输出该负样本为正的那个概率值要大的可能性
通过计算AUC值,也可以判断出最佳阈值
ROC优势
无论怎样修改不同样本的数目,ROC均没有影响
如何计算最佳阈值
通过ROC图可知,TPR越大越好,FPR越小越好,所以只要能够得到不同阈值条件下的TPR和FPR,计算之间的差值,结果值最大的就是最佳阈值
1 | thresh = thresholds[np.argmax(tpr - fpr)] |
python实现
sklean库提供了多个函数用于ROC/AUC的计算,参考3.3.2.14. Receiver operating characteristic (ROC)
roc_curve
1 | def roc_curve(y_true, y_score, pos_label=None, sample_weight=None, |
y_true:一维数组形式,表示样本标签。如果不是{-1,1}或者{0,1}的格式,那么参数pos_label需要显式设定y_score:一维数组形式,表示目标成绩。可以是对正样本的概率估计/置信度pos_label:指明正样本所属标签。如果y_true是{-1,1}或{0,1}格式,那么pos_label默认为1
1 | import numpy as np |
返回的是FPR、TPR和阈值数组,FPR和TPR中每个坐标的值表示利用thresholds数组同样下标的阈值所得到的真阳性率和假阳性率
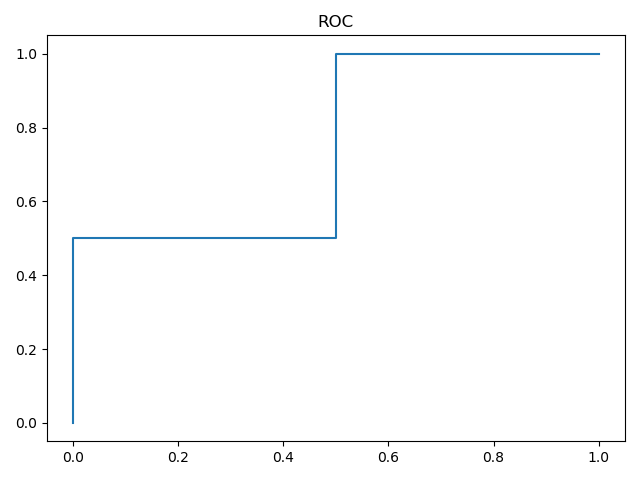
roc_auc_score/auc
1 | def roc_auc_score(y_true, y_score, average="macro", sample_weight=None, |
y_true:格式为[n_samples]或者[n_samples, n_classes]y_score:格式为[n_samples]或者[n_samples, n_classes]
返回的是AUC的值
1 | def auc(x, y, reorder='deprecated'): |
x:FPRy:TPR
利用roc_curve计算得到FPR和TPR后,就可以输入到auc计算AUC大小
1 | from sklearn.metrics import roc_auc_score |
示例
利用fashion-mnist数据集进行实验,分两种情况:
- 仅使用类别
0和类别1的样本:选择类别0作为正样本,选择类别1作为副样本 - 使用所有类别:选择类别
0作为正样本,其他类别作为负样本