DVC: An End-to-end Deep Video Compression Framework
原文地址:DVC: An End-to-end Deep Video Compression Framework
实现地址: GuoLusjtu/DVC
摘要
1 | Conventional video compression approaches use the predictive coding architecture and encode the corresponding motion |
传统的视频压缩方法使用预测式编码架构,对相应的运动信息和残差信息进行编码。本文利用传统视频压缩方法中的经典结构和神经网络强大的非线性表示能力,提出了第一个端到端的视频压缩深度模型,该模型联合优化了视频压缩的所有组件。具体地,基于学习的光流估计被用来获得运动信息和重建当前帧。然后,我们使用两个自编码器类型的神经网络来压缩相应的运动和残差信息。所有模块通过一个损失函数就可以学习完成,在该函数中,它们通过考虑减少压缩位数和提高解码视频质量之间的权衡来相互协作。实验结果表明,该方法在PSNR方面优于广泛使用的视频编码标准H.264,在MS-SSIM方面甚至与最新的标准H.265不相上下。代码发布在https://github.com/GuoLusjtu/DVC。
问题和贡献
设计端到端的视频压缩深度框架存在两个问题:
- 如何生成和压缩动作信息。其中一个解决方案就是使用光流估计来表示动作信息,只是不知道如何使用光流算法针对特定网络进行优化;而如果结合传统的动作压缩算法对光流估计进行压缩,其比特数会超过传统动作估计算法;
- 不知道怎么设计架构。如何才能针对残差和动作信息进行率失真优化(
rate-distortion optimization, RDO)。RDO的目的是保持一定比特率的同时尽可能的降低失真率。
DVC(Deep Video Compression)的贡献:
- 所有的关键组件可以同时训练,包括动作估计、动作补偿、动作压缩、残差压缩、量化和比特率估计,实现端到端的训练框架;
- 使用单个损失函数即可训练所有关键组件,基于
RDO原则实现更好的性能; DVC架构与视频压缩传统框架一一对应,通过插件化设置,可以通过最新发展的深度模型插件实现更好的性能
视频压缩传统框架
视频压缩传统框架如下图(a)所示,更详细内容可以参考H264/AVC和H265/HEVC
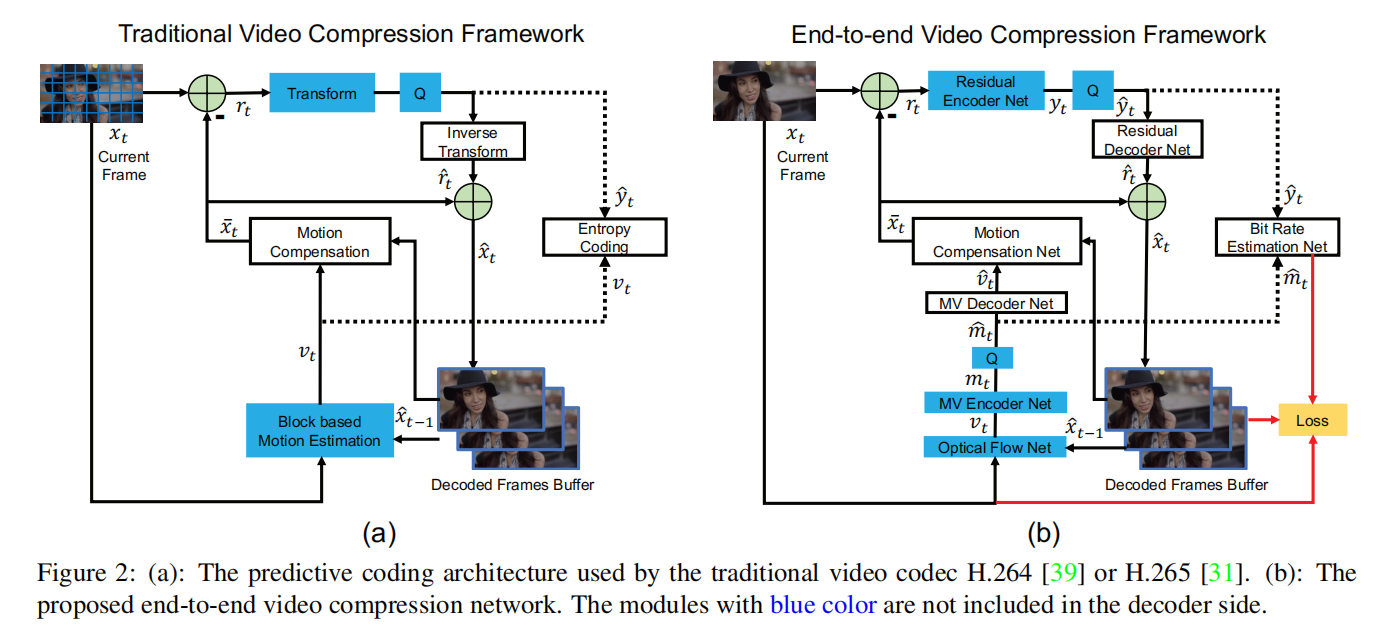
首先将输入帧
- 动作估计(
Motion estimation):结合当前帧和上一个重构帧$\hat{x}{t-1} v{t}$; - 动作补偿(
Motion compensation):结合当前帧的动作向量和上一个重构帧$\hat{x}{t-1} \bar{x}{t} r_{t} r_{t}=x_{t}-\bar{x}_{t}$ - 转换和量化(
Transform and quantization):先对残差向量利用线性变换(比如DCT)进行残差压缩;再进行量化计算得到 ; - 反向变换(
Inverse transform):对量化残差向量$\hat{y}{t}\hat{r}{t}$; - 熵编码(
Entropy coding):针对运动向量和量化残差向量 进行熵编码得到比特流。可以保存下来用于后续的解码器操作 - 帧重构(
Frame reconstruction):重构的当前帧$\hat{x}{t}\bar{x}{t} \hat{r}{t} \hat{x}{t}=\bar{x}{t}+\hat{r}{t} t+1$帧的上一个重构帧进行计算。
通过编码操作,每一帧都能保存下来运动向量
视频压缩深度框架
概述
DVC参考传统的视频编码框架设计了一个相应的深度编码架构,如上图(b)所示。对于DVC而言,其输入图像不再需要进行分块操作,而是直接输入整个图像:
- 动作估计和压缩(
Motion estimation and compression):使用论文Optical flow estimation using a spatial pyramid network提出的卷积神经网络计算光流,以此来作为运动信息,并且在后续添加了一个自编码器进行运动信息的压缩(关于自编码器的定义和使用在后续章节中介绍) - 动作补偿(
Motion compensation):DVC设计了一个动作补偿网络来替代传统的动作补偿模块(关于动作补偿网络的定义和使用在后续章节中介绍) - 转换、量化和反转换(
Transform, quantization and inverse transform):在传统的视频编码框架中,使用线性变换(比如DCT)对残差信息进行转换操作。在DVC中,设计了一个非线性的残差自编码器,将残差信息编码为 ,然后进行量化操作得到$\hat{y}{t} \hat{r}{t}$(有关自编码器以及量化操作的定义和使用在后续章节中介绍) - 熵编码(
Entropy coding):实际运行过程中,压缩并量化后的运动信息$\hat{m}{t}\hat{y}{t}$会被编码为比特流保存下来。在训练阶段, DVC设计了一个比特率估计网络,用于计算$\hat{m}{t}\hat{y}{t}$中每个符号的概率分布,以此来估计实际保存时每位像素所占比特数(更多细节在后续章节中介绍) - 帧重构(
Frame reconstruction):类似于传统的视频编解码框架,将$\hat{m}{t}\hat{v}{t} \hat{x}{t-1} \bar{x}{t} \hat{y}{t} \hat{r}{t} \hat{x}{t}=\bar{x}{t}+\hat{r}_{t}$
运动向量自编码器
论文参考了End-to-end optimized image compression实现了一个自编码器用于运动信息的压缩
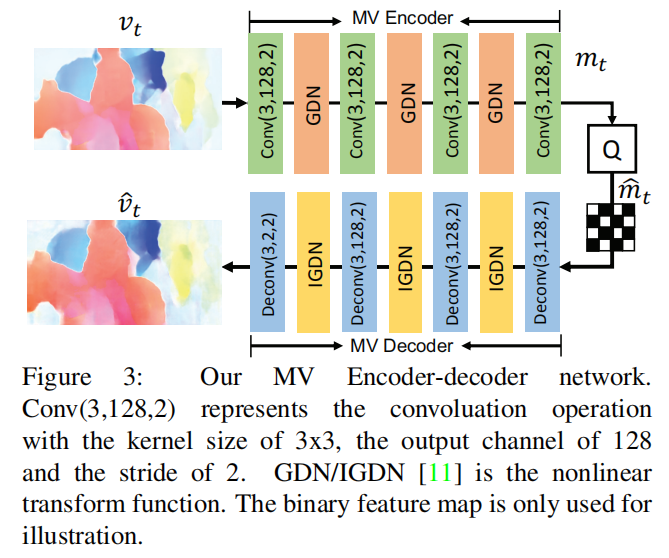
整个网络的中间层通道数均为
运动向量补偿网络
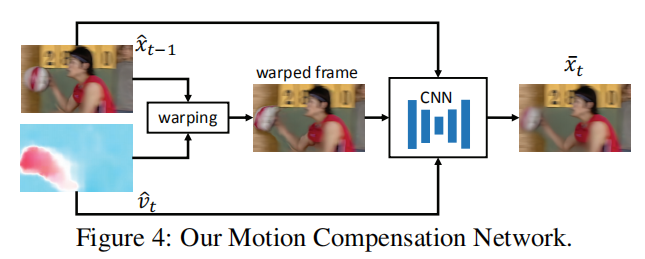
完整的运动向量补偿网络操作如上图所示。给定上一个重构帧$\hat{x}{t-1}
- 结合上一个重构帧$\hat{x}{t-1}
\hat{v}{t}$得到扭曲帧; - 将扭曲帧$w(\hat{x}{t-1}, \hat{v}{t})
\hat{x}{t-1} \hat{v}{t} \bar{x}_{t}$
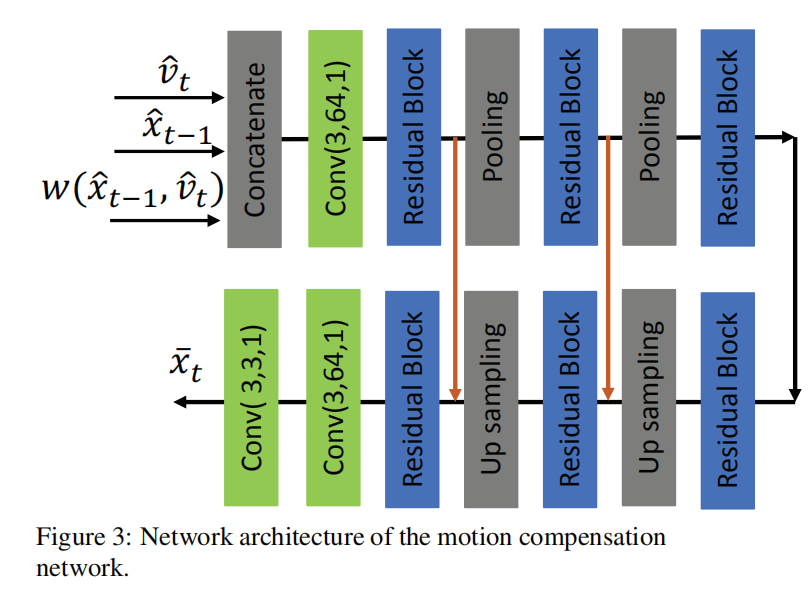
运动补偿网络的设计如下图所示:
残差向量自编码器
论文使用Variational image compression with a scale hyperprior设计的网络进行残差信息的编解码操作
量化
对于压缩后的残差向量
比特率估计
论文使用Variational image compression with a scale hyperprior设计的比特率估计网络计算压缩后的运行信息$\hat{y}{t}
损失函数
损失函数的设计符合率-失真优化准则,其实现如下:
$$
\lambda D+R = \lambda d(x_{t}, \hat{x}{t}) + (H(\hat{m}{t}) + H(\hat{y}_{t}))
$$
- $d(x_{t}, \hat{x}{t})
x{t} \hat{x}_{t}$的失真率,使用均值平方差( MSE)进行计算; 表示编码运动信息或者残差信息的比特数 用于平衡失真率和比特数之间的训练
实现结果
数据集
使用Vimeo90K数据集进行训练;使用UVG数据集和HEVC(Class B/C/D/E)标准测试序列进行测试
评价标准
使用PSNR和MS-SSIM作为评价标准。在评判过程中,使用Bpp(bits per pixel,每个像素所需比特数)表示像素所需比特数
实验结果
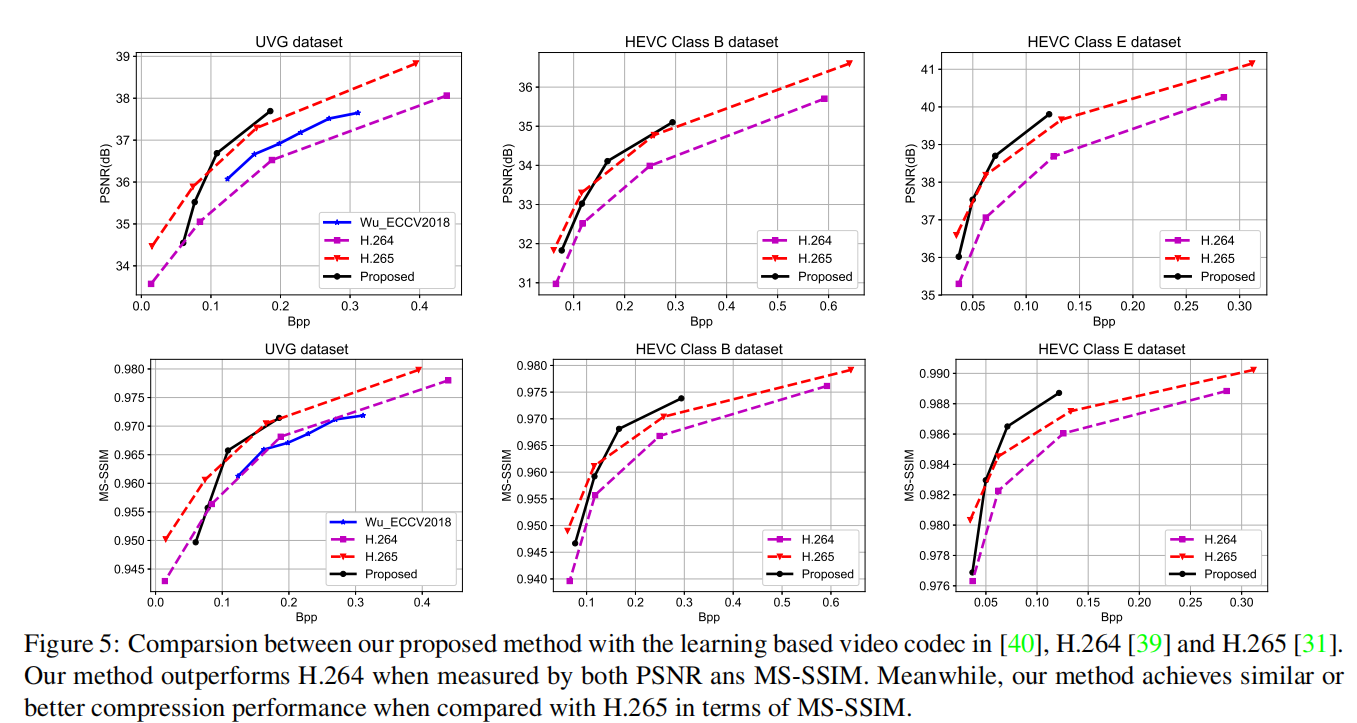
DVC对比了Video Compression through Image Interpolation所提出的深度方法(以下简称Wu网络)以及该论文所使用的H264/H265设置。在UVG测试集上的GOP设置为12,在HEVC测试集上的GOP设置为10,其实验结果如下:
运行时间和模型复杂度
整个端到端的视频压缩框架大小为11M。在Intel Xeon E5-2640 v4 CPU以及单块1090Ti GPU环境下,对于大小为
Wu网络的编解码速度分别为29fps/38fps;DVC网络的编解码速度分别为24.5fps/41fps;- 官方提供的
H264/H265编码软件JM和HM的编码速度为2.4fps/0.35fps; - 商业软件
x264/x265的编码速度为250fps/45fps。
小结
DVC是第一个真正实现了端到端训练的视频压缩深度模型。它的整体架构参考了H264/H265的实现,通过深度模型来替代其中的关键组件;通过RDO损失函数能够同时优化失真率和压缩率。