MnasNet: Platform-Aware Neural Architecture Search for Mobile
原文地址:MnasNet: Platform-Aware Neural Architecture Search for Mobile
摘要
Designing convolutional neural networks (CNN) for mobile devices is challenging because mobile models need to be small and fast, yet still accurate. Although significant efforts have been dedicated to design and improve mobile CNNs on all dimensions, it is very difficult to manually balance these trade-offs when there are so many architectural possibilities to consider. In this paper, we propose an automated mobile neural architecture search (MNAS) approach, which explicitly incorporate model latency into the main objective so that the search can identify a model that achieves a good trade-off between accuracy and latency. Unlike previous work, where latency is considered via another, often inaccurate proxy (e.g., FLOPS), our approach directly measures real-world inference latency by executing the model on mobile phones. To further strike the right balance between flexibility and search space size, we propose a novel factorized hierarchical search space that encourages layer diversity throughout the network. Experimental results show that our approach consistently outperforms state-of-the-art mobile CNN models across multiple vision tasks. On the ImageNet classification task, our MnasNet achieves 75.2% top-1 accuracy with 78ms latency on a Pixel phone, which is 1.8× faster than MobileNetV2 [29] with 0.5% higher accuracy and 2.3× faster than NASNet [36] with 1.2% higher accuracy. Our MnasNet also achieves better mAP quality than MobileNets for COCO object detection. Code is at https://github.com/tensorflow/tpu/tree/master/models/official/mnasnet.
为移动设备设计卷积神经网络(CNN)非常具有挑战性,因为移动模型需要小和快的同时仍然保持准确性。尽管人们在设计和改进所有维度的移动cnn方面已经付出了巨大的努力,但是当需要考虑如此多的架构可能性时,仍旧很难手动平衡这些权衡。在本文中,我们提出了一种自动化移动神经架构搜索(MNAS)方法,该方法明确地将模型延迟纳入到主要目标中,以使搜索能够识别一个模型,该模型在准确性和延迟之间取得了良好的平衡。以往的工作中使用间接度量标准(例如,FLOPS)来考虑延迟,我们的方法通过在手机上执行模型来直接测量真实世界的推理延迟时间。为了进一步在灵活性和搜索空间大小之间取得正确的平衡,我们提出了一种新的分解层次搜索空间,它鼓励整个网络的层多样性。实验结果表明,我们的方法在多个视觉任务中始终优于最先进的移动CNN模型。在ImageNet分类任务中,我们的MnasNet在Pixel手机上以78ms的延迟达到75.2%的top-1准确率,比MobileNetV2[29]快1.8倍,准确率高0.5%,比NASNet[36]快2.3倍,准确率高1.2%。MnasNet在COCO目标检测方面也比MobileNets获得了更好的mAP。代码位于https://github.com/tensorflow/tpu/tree/master/models/officer/mnasnet
主要贡献
- 介绍了一种多目标神经架构搜索方法,它可以在移动设备上优化准确性和真实世界的延迟
- 提出了一种新的分解分层搜索空间,保证层多样性的同时仍能在灵活性和搜索空间大小之间取得适当的平衡
- 在特有的移动设备的延迟约束下,我们在
ImageNet分类和COCO目标检测方面达到了最好的准确率
章节内容
整篇论文结构清晰易懂,不过有关模型设计方面涉及到了强化学习的内容,不容易复现@@@
- 首先设计一个多目标函数作为
reward,同时考虑模型准确率和推导时间 - 然后介绍了一个新的分解分层搜索空间,以及基于强化学习的搜索方法
- 最后介绍了搜索得到的模型,通过实验证明新模型的性能优于之前的结果
本文不涉及自动化移动神经架构搜索方法,所以仅学习MnasNet模型架构以及实验分析
训练环境
- 硬件环境
64 TPUv2single-thread big CPU core of Pixel 1 phones
- 数据集
ImageNet- 从训练集中随机采样
50K张图像作为固定的验证集
- 从训练集中随机采样
COCO
- 训练参数
- 优化器:
RMSProp,decay 0.9 and momentum 0.9 - 权重衰减:
1e-5 - 对于最后一层执行随机失活,因子为
0.2 - 学习率:前
5轮执行warmup,从0-0.256;后续每个2.4轮执行0.97 - 批量大小:
4K - 输入图像:
- 优化器:
- 强化学习
- 使用
NASNet中的RNN控制器 - 共采样
8K个模型,每个模型仅在ImageNet上训练5轮 - 取
top-15的模型在ImageNet上进行完整训练 - 取
top-1的模型在COCO上进行完整训练
- 使用
模型架构
整体架构
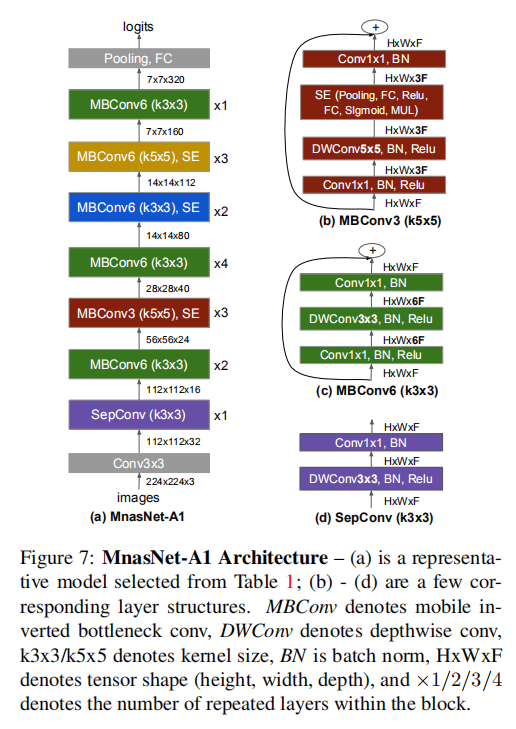
MBConv:反向瓶颈残差块DWConv:深度卷积k3x3/k5x5:卷积核大小BN:批量归一化操作:张量大小 :层重复次数
层多样性
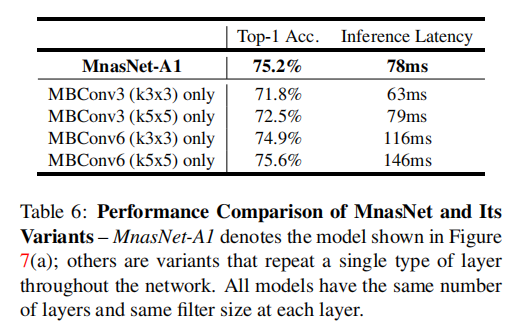
搜索得到的MnasNet模型包含了多个不同模块:
MBConv6 (k3x3)MBConv6 (k5x5), SEMBConv6 (k3x3), SEMBConv3 (k5x5), SESepConv (k3x3)
论文用实验证明了层多样性对模型性能的提高
实验
识别性能
论文选择了前3个拥有不同延迟-性能权衡的MnasNet模型,与MobileNetV2进行比较
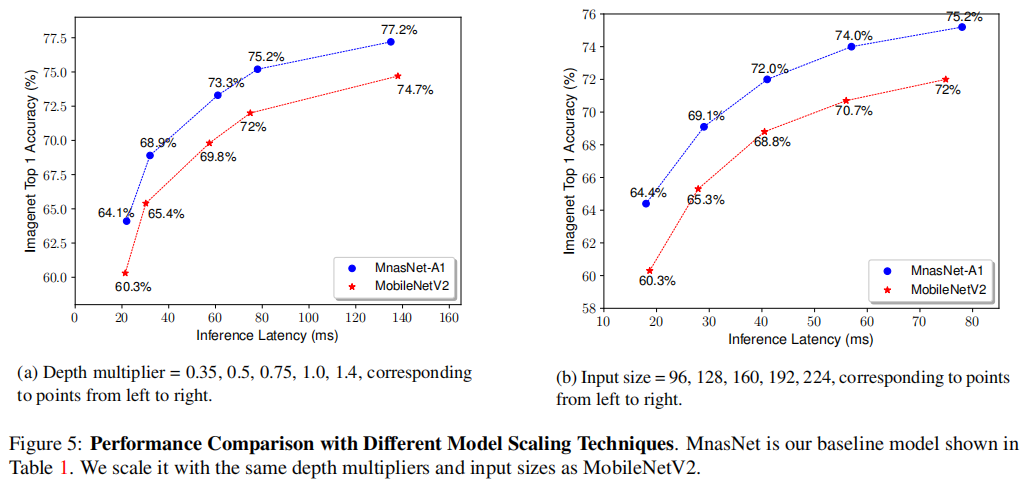
在不同大小的宽度乘法器和分辨率乘法器的情况下,MnasNet均比MobileNetV2更好
检测性能
使用MnasNet作为SSDLite的特征采样器,与YOLOv2/SSD/SSDLite进行比较
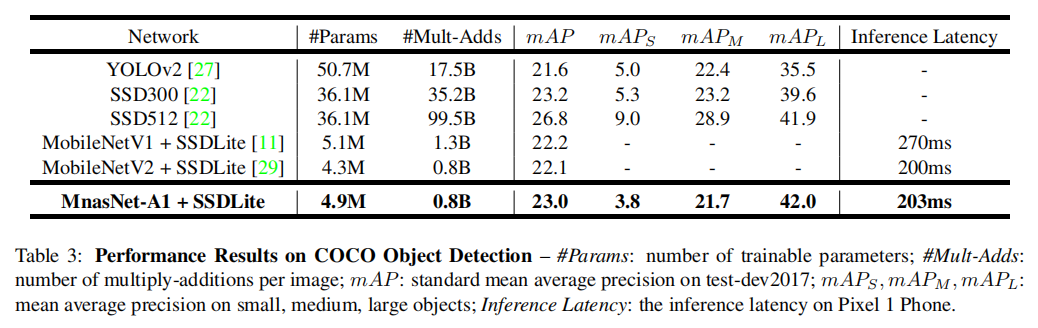
MnasNet在得到相近检测精度和检测时间的同时极大的压缩了参数和FLOPs
小结
MnasNet和ShuffleNetV2一样,都考虑到了FLOPs的局限性,转而使用直接度量标准Speed来进行模型的优化。不过相对而言,MnasNet通过自动化神经架构搜索技术来得到新的模型,咋说呢,更具未来的可能性