Lossless CNN Channel Pruning via Decoupling Remembering and Forgetting
原文地址:Lossless CNN Channel Pruning via Decoupling Remembering and Forgetting
官方实现: DingXiaoH/ResRep
摘要
We propose ResRep, a novel method for lossless channel pruning (a.k.a. filter pruning), which aims to slim down a convolutional neural network (CNN) by reducing the width (number of output channels) of convolutional layers. Inspired by the neurobiology research about the independence of remembering and forgetting, we propose to re-parameterize a CNN into the remembering parts and forgetting parts, where the former learn to maintain the performance and the latter learn for efficiency. By training the re-parameterized model using regular SGD on the former but a novel update rule with penalty gradients on the latter, we realize structured sparsity, enabling us to equivalently convert the re-parameterized model into the original architecture with narrower layers. Such a methodology distinguishes ResRep from the traditional learning-based pruning paradigm that applies a penalty on parameters to produce structured sparsity, which may suppress the parameters essential for the remembering. Our method slims down a standard ResNet-50 with 76.15% accuracy on ImageNet to a narrower one with only 45% FLOPs and no accuracy drop, which is the first to achieve lossless pruning with such a high compression ratio, to the best of our knowledge.
我们提出了ResRep,一种新的无损通道修剪方法(也称为滤波器修剪),旨在通过减少卷积层的宽度(输出通道的数量)来精简卷积神经网络(CNN)。受关于记忆和遗忘独立性的神经生物学研究的启发,我们提议将CNN重新参数化为记忆部分和遗忘部分,前者学习保持性能,后者学习提高效率。通过在前者上使用常规的SGD训练重新参数化的模型,而在后者上使用带有惩罚梯度的新的更新规则,我们实现了结构化稀疏性,使得我们能够将重新参数化的模型等效地转换成具有更窄层的原始体系结构。这种方法将ResRep与传统的基于学习的剪枝范式区分开来,传统的剪枝范式对参数进行惩罚以产生结构化稀疏性,这可能抑制记忆所必需的参数。据我们所知,我们的方法将标准的ResNet-50在ImageNet上的准确率为76.15%,缩小到只有45%的浮点运算且准确率没有下降,这是第一个实现如此高压缩比的无损修剪。
简介
完美剪枝:经过剪枝训练后,待剪枝的通道能够获得足够小的值,那么修剪这些通道有可能不会损坏模型性能,能够得到和剪枝前相同的性能
基于训练的剪枝方法评价指标:
Resistance:经过剪枝训练的模型能够和正常训练的模型保持相同的性能,那么称该剪枝方法具有高抗性;Prunability:如果模型在剪枝阶段拥有高剪枝率,并且仅有些微的性能下降,那么称该剪枝方法具有高剪枝率。
以往基于训练的剪枝方法都存在对高抗性和高剪枝率的平衡,论文提出一种新的剪枝方法 - ResRep。其包含两个关键组件:卷积重参数化(convolutional re-parameterization)以及梯度重置(gradient resetting)
ResRep的灵感来自记忆和遗忘的神经生物学研究。一方面,记忆需要大脑加强一些突触,但削弱其他突触,这类似于CNN的训练过程,使一些参数变大,一些变小。另一方面,通过 spines收缩或缺失来消除突触是经典的遗忘机制之一[50],是提高生物神经网络能量和空间效率的关键过程,类似于剪枝过程。神经生物学研究表明,记忆和遗忘分别由Rutabaga腺苷酸环化酶介导的记忆形成机制和Rac-regulated spine收缩机制独立控制[11,15,53],表明通过两个解耦模块控制学习和修剪更合理。
受这种独立性的启发,我们建议将传统范式中耦合的“记忆”和“遗忘”解耦,因为“记忆”(目标函数)和“遗忘”(惩罚损失)都涉及conv参数,以便它们实现权衡。即传统方法强制每个频道“忘记”,去掉“忘记最多”的频道。相反,我们首先将原始模型重新参数化为“记忆部分”和“遗忘部分”,然后将“记忆学习”(即具有原始目标函数的常规SGD)应用于前者以保持“记忆”(原始性能),并将“遗忘学习”(一种称为梯度重置的定制更新规则)应用于后者以“消除突触”(零输出通道)。更具体地说,我们通过conv-BN-compressor重新参数化原始conv-BN(conv层的缩写,随后是批量归一化[25])序列,其中compressor是逐点(1 × 1) conv层。在训练过程中,我们只给压实机添加惩罚梯度,选择一些压实机通道,并从目标函数中消除它们的梯度。这样的训练过程使得压实机的一些通道非常接近于零,去掉这些通道不会造成修剪造成的伤害。然后我们通过一系列的线性变换,将conv-贝叶斯网络-压缩器序列等效地转换成具有较少通道的单个conv层。最终,生成的模型将具有与原始模型相同的体系结构,但层更窄。图1。b举例说明。请注意,ResRep也可以用于修剪完全连接的层,因为它们相当于1 × 1卷积[40]。
流程

- 给定一个训练好的模型
; - 执行卷积参数化操作(
Convolutional Re-parameterized),在conv-bn层之后添加compactor层,构造新的模型- 初始化
compactor权重参数为单位矩阵; - 其余部分使用已训练的参数;
- 初始化
- 开始迭代
- 输入批量图像,使用正常训练的目标函数计算损失,并求导出梯度;
- 在
compactor层上额外应用梯度重置操作(Gradient Resetting); - 更新梯度
- 完成训练后,对
中各个 compactor层进行滤波器剪枝操作,删除接近于的滤波器维度(比如 ) - 完成剪枝后,将
中 conv-bn-compactor融合在一起,得到模型
基本公式
论文介绍了进行卷积操作和通道剪枝的基本操作。假定卷积层参数如下:
- 输出通道数:
- 输入通道数:
- 卷积核大小:
- 权重矩阵:
- 偏置:
卷积操作如下:
表示输出张量,大小为 表示输入张量,大小为 表示广播函数,将偏置 扩展到
如果在卷积层之后添加一个批量归一化层,那么不再需要卷积层的偏置参数,操作如下:
$$
O_{:,j,:,:} = ((I\circledast K){:,j,:,:} - \mu{j})\frac{\gamma_{j}}{\sigma_{j}} + \beta_{j}, \forall 1\leq j\leq D
$$
表示归一化层均值; 表示归一化层标准差; 表示归一化层缩放因子; 表示归一化层偏置;
假定卷积层下标为
经过剪枝后,通道集合
$$
K^{(i)}{}’ = K^{(i)}{S^{(i)},:,:,:}\ \ K^{(i+1)}{}’ = K^{(i+1)}{:,S^{(i)},:,:}
$$
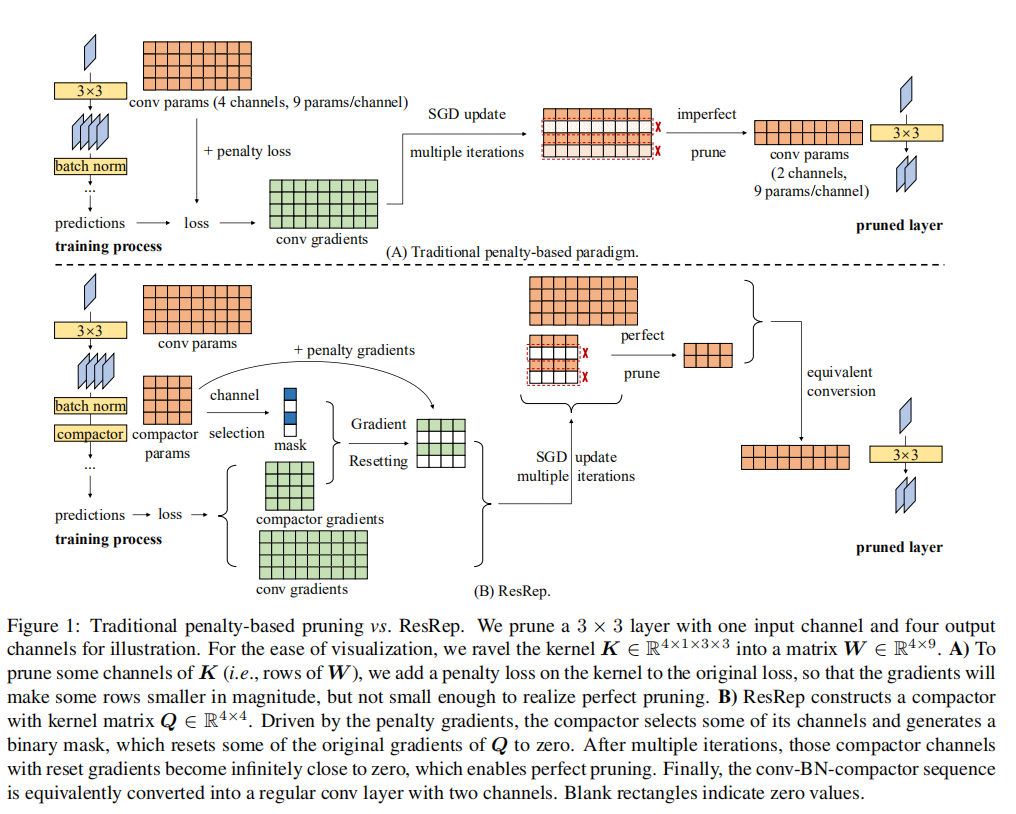
卷积重参数化
卷积重参数化操作分为三部分:
- 训练阶段:将模型各个模块显式的区分为记忆部分和遗忘部分,具体实现方式就是在每个
Conv-BN层之后额外添加一个Compactor层。Compactor层是一个逐点卷积,其卷积核大小为; - 剪枝阶段:仅对
Compactor层进行剪枝; - 部署阶段:将每组
Conv-BN-Compactor层转换成为单个Conv,最终模型不改变原始模型架构
训练
- 给定模型
,指定想要剪枝的 Conv-BN层(论文称之为目标层(target layer)) - 添加一个
Compactor层,格式为Conv-BN-Compactor。其中Compactor层是一个逐点卷积,其内核 - 完成转换后得到模型
,其 Conv-BN层参数保持不变,另外Compactor层权重参数初始化为单位矩阵。这样模型的输出和原始模型 保持一致。
剪枝
完成训练后,仅对Compactor层的滤波器维度进行剪枝,其剪枝原则为减去范数大小小于阈值Compactor层的权重大小为$Q’ = Q{S,:}$
论文推荐剪枝阈值
完成剪枝后,Compactor层卷积核大小为
部署
部署阶段,将Conv-BN-Compactor转换成单个卷积层,其大小为
首先将Conv-BN转换成单个卷积层,其实现如下:
$$
\bar{K}{j,:,:,:} = \frac{\gamma{j}}{\sigma_{j}}K_{j,:,:,:}, \ \ \bar{b}{j} = -\mu{j}\frac{\gamma_{j}}{\sigma_{j}} + \beta_{j}, \forall 1\leq j\leq D
$$
和 是新的卷积层的卷积核以及偏置
接下来就是将Conv-Compactor转换成单个卷积层,其实现如下:
卷积操作具有可加性,将上述公式推理如下:
梯度重置
公式
梯度重置的核心在于对遗忘模块进行逐步掩码训练,这样即保证了记忆模块能够很好的进行性能训练,也能够保证模型具有足够的稀疏性。
传统的剪枝训练方式是额外添加一个稀疏损失
表示输入数据 表示输入标签 表示模型参数集 表示稀疏损失 表示通道集 表示稀疏强度
常用的Group Lasso操作(更适用于通道剪枝)。论文使用Group Lasso作为稀疏损失计算函数,其公式如下:
是 中一组特定的通道(或者称之为待剪枝的通道) 表示欧式距离,其实现如下
$$
\left | F \right |{E} = \sqrt{\sum{c=1}^{C}\sum_{p=1}^{K}\sum_{q=1}^{K}F_{c,p,q}^{2}}
$$
计算得到的梯度如下:
论文也分析了这种梯度更新方式的缺陷,主要在于目标函数和稀疏函数之间会相互竞争,稀疏函数的目的在于将通道的大小趋向于0,而如果目标函数认为该通道有作用,那么它会放大该通道的大小,论文称这种方式是基于竞争的重要性评估(competence-based importance evaluation)。这种方式会带来两个问题:
- 目标函数和稀疏函数共同作用,有可能会偏移模型最优化方向,降低模型性能;
- 如果减少了稀疏化强度,那么会导致剪枝率的下降。
基于上面的考虑,论文提出的梯度重置操作如下:
是一个二值掩码 ,控制是否对某些通道执行梯度更新
梯度重置操作如下:
- 对每个通道都执行梯度更新,但是给予很小的稀疏化强度(
),这种小的优化不改变模型性能; - 对于待剪枝的通道(也就是
Compactor层),可选的设置,这样可以保证 大小稳定的趋向于
实现
论文并没有在训练过程中取消对所有Compactor层的目标函数相关的梯度更新,而是设计了一个更新策略:
- 假定
表示 Compactor层的卷积核; - 最开始训练的时候不设置
的大小为 ; - 经过几轮训练后,
能够反映第 个滤波器的重要性。然后开始进行通道选择( channel selection)- 假定模型共有
个 Compactor; 表示第 个 Compactor的掩码,是一个大小为的二值向量; - 定义
是测量向量,其计算公式如下:
$$
t^{(i)}{j} = \left | Q{j,:}^{(i)} \right |_{2}, \forall 1\le j\le D^{(i)}
$$ - 在每次通道选择过程中,计算
个 Compactor的个通道的度量值,进行从小到大排序,每次选择值最小的通道,设置其掩码为 ,其余未选中的通道掩码为 - 设置超参数
,称之为通道选择限制( channel selection limit),表示通道选择的最大个数。每轮选择一个通道,设置其掩码值为0,,掩码为0的通道数达到后不再进行选择; - 经过几轮的训练之后,重新设置
值,增加其大小,同时重新开始选择通道(所有掩码初始化为1)
- 假定模型共有
实验
- 设置稀疏化强度
; - 设置初始通道选择限制
,每隔200轮
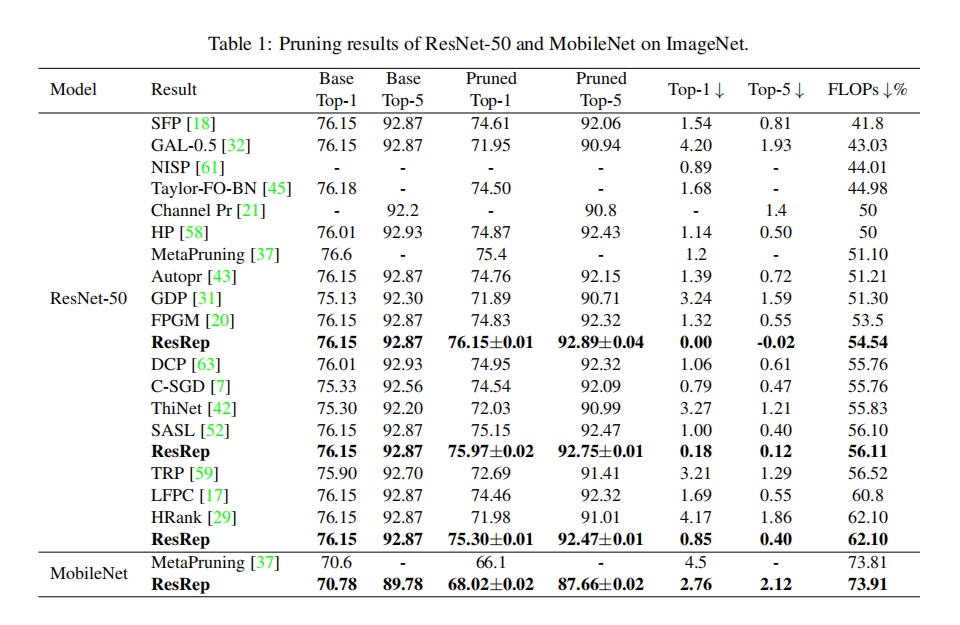
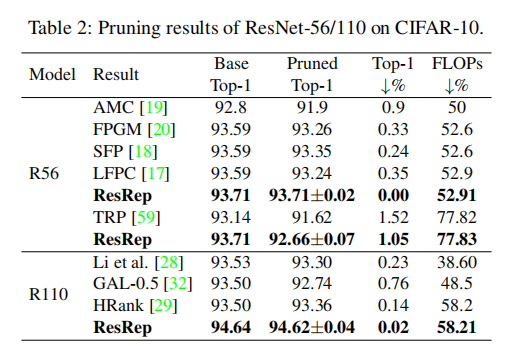
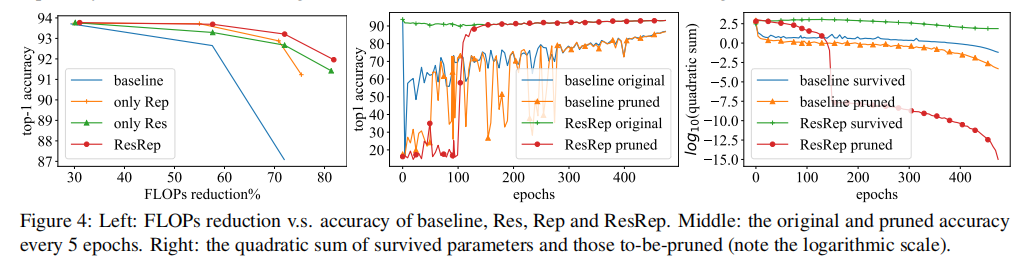
研究
论文研究了分离Res和Rep操作的剪枝操作,其结果如下:
小结
相对于之前的通道剪枝算法,ResRep的理论性更强,通过观察神经学研究,通过梯度重置分离性能训练和稀疏训练,并且通过重参数操作确保训练前后模型架构的一致性