Deep Learning of Binary Hash Codes for Fast Image Retrieval
原文地址:Deep Learning of Binary Hash Codes for Fast Image Retrieval
官方实现:kevinlin311tw/caffe-cvprw15
Pytorch实现:
摘要
Approximate nearest neighbor search is an efficient strategy for large-scale image retrieval. Encouraged by the recent advances in convolutional neural networks (CNNs), we propose an effective deep learning framework to generate binary hash codes for fast image retrieval. Our idea is that when the data labels are available, binary codes can be learned by employing a hidden layer for representing the latent concepts that dominate the class labels. The utilization of the CNN also allows for learning image representations. Unlike other supervised methods that require pair-wised inputs for binary code learning, our method learns hash codes and image representations in a point-wised manner, making it suitable for large-scale datasets. Experimental results show that our method outperforms several state-of-the-art hashing algorithms on the CIFAR-10 and MNIST datasets. We further demonstrate its scalability and efficacy on a large-scale dataset of 1 million clothing images.
近似最近邻搜索是大规模图像检索的一种有效策略。在卷积神经网络(CNN)最新进展的鼓舞下,我们提出了一种有效的深度学习框架来生成用于快速图像检索的二进制哈希码。我们的想法是,当数据标签有效时,可以通过神经网络隐藏层(该隐藏层能够作用于后续的类标签学习)来学习二进制码,同时CNN还可以学习图像表示。与其他需要成对输入进行二进制码学习的有监督方法不同,我们的方法以逐点的方式(也就是单个图像即可)学习哈希码和图像表示,使其适用于大规模数据集。实验结果表明,在CIFAR-10和MNIST数据集上,我们的方法优于几种最先进的哈希算法。我们在包含100万张服装图像的大规模数据集上进一步展示了它的可扩展性和有效性。
引言
在之前的论文中已经证明了深度学习能够有效的作用于图像检索任务,不过模型特征表示常常是高维的,计算上是耗时的。
之前对于CNN特征表示的探索大多集中在性能检索上,并没有考虑计算耗时。由于高维特征带来的高计算量,使得传统的线性搜索(linear search)或穷举搜索(exhaustive search)不适用于大数据集,实际情况下通常使用最近邻(Approximate Nearest Neighbor (ANN))或者基于哈希的方式(hashing based method)进行加速搜索。将高维特征投影到低维空间,然后生成紧凑的二进制码,这样通过二进制模板匹配(binary pattern matching)或者海明距离度量方法(Hamming distance measurement)即可进行快速搜索。
之前的方法采用了逐对方式进行相似性学习,使用相似度矩阵来描述图像对(或者数据对)之间的关系,然后应用这个相似信息来学习哈希函数。这种训练方式对于大数据集而言同样是困难的。论文提出在CNN模型中嵌入隐藏层,通过二值激活函数(比如sigmoid)来学习二进制码,论文主要贡献:
- 创建了一个简单但高效的用于快速图像检索的有监督学习框架;
- 只需要对模型进行简单修改,就能够同步学习特定域的图像表示(正常的图像分类训练)和一组用于快速图像检索的类哈希函数;
- 提出的算法在
MNIST和CIFAR10数据集上超越了之前最好的方法,在CIFAR10数据集上比之前最好方法提高了30%精度,在MNIST数据集上提高了1%精度; - 提出的算法基于逐点模式进行二进制哈希码学习,相比于之前逐对的方法更容易扩展到更大的数据集。
实现
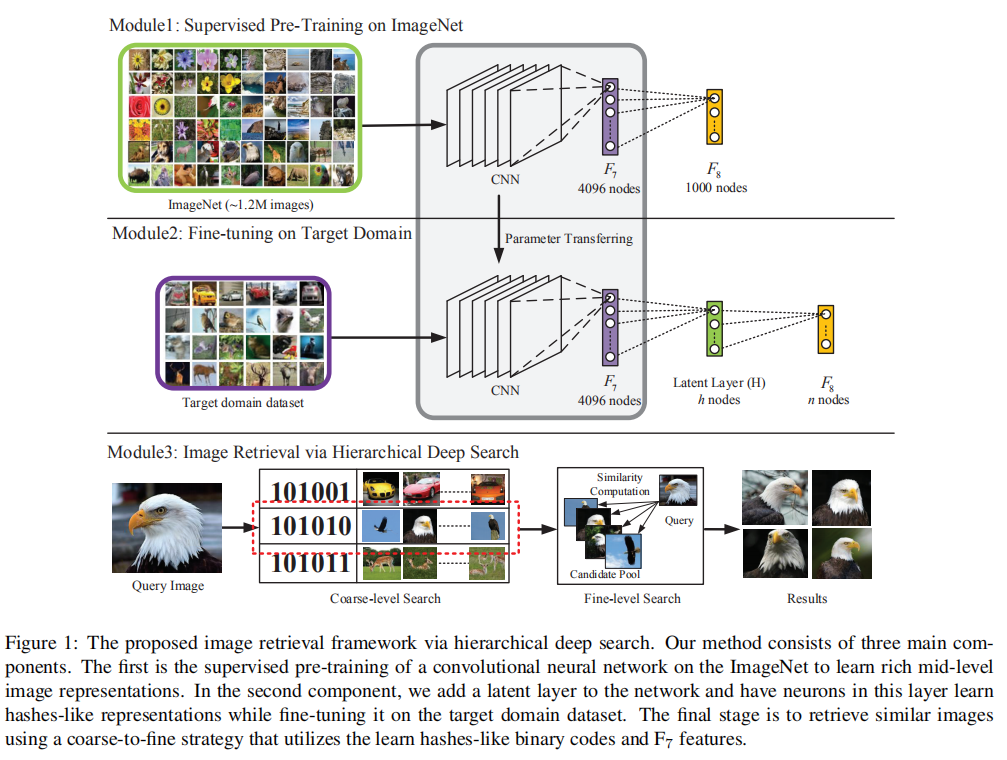
上图是论文提出的整体算法框架,可分为3部分进行:
- 在
ImageNet数据集上进行模型预训练; - 在模型中嵌入隐藏层(
latent layer),使用目标数据集进行微调训练,同步学习特定域图像表示以及一组类哈希函数; - 构建分层深度搜索(
hierarchical deep search)方法进行图像检索。
论文使用AlexNet作为CNN模型进行实验。
类哈希二进制码学习
实现方式:在F7和F8层之间嵌入一个隐藏层H。H是一个全连接层,后跟随着激活函数Sigmoid,经过激活层输出后特征可以近似模拟为二进制码。
分层深度搜索
ZFNet分析了深度CNN模型在训练过程中,前几层(浅层)网络学习局部可视化描述符, 然后更深层网络能够捕获到适用于目标分类的语义信息。论文受此启发,提出从粗到细的搜索策略(coarse-to-fine search strategy):
- 首先使用隐藏层
H输出的二进制码进行图像检索,得到一组候选目标; - 然后对这组相似候选目标进行过滤,论文使用了模型深层输出进行相似度排序。
粗粒度搜索
给定图像
假定
给定查询图像Hamming distance)小于阈值。
细粒度搜索
对于查询图像
欧式距离越小,表示两张图像的相似度越高,完成计算后按照相似度大小进行降序排序得到前
数据集
MNIST:包含10类手写数字,从0到9,共有6w张训练图片和1w张测试图片。所有图片均是灰度图片,大小为28x28;CIFAR-10:包含10类目标,每类有6千张图片,共有6w张。其中训练集包含5w张,测试集包含1w张;Yahoo-1M:包含112, 4087张购物产品图片,共有116类服装类别。该数据集是通过对雅虎购物网站上的图像进行抓取来收集的。所有图片被标记为一个类别,比如上衣、连衣裙、裙子等等。如下图2所示

评估指标
给定图像P@K来评估前
其中
MNIST
分类性能
首先在MNIST数据集上进行微调训练,对于隐藏层48到128。使用SGD进行训练,共训练5w轮,学习率为0.001。实现结果如下表1所示:
`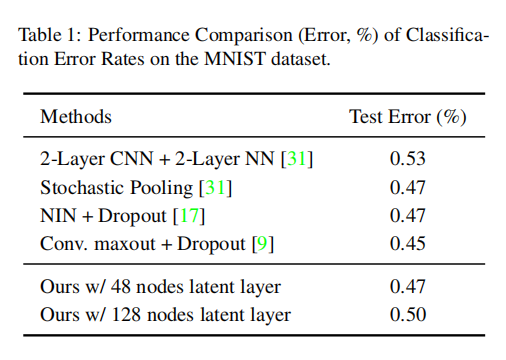
- 加入隐藏层并没有影响模型分类性能;
- 使用
48个节点的模型性能高于128个节点隐藏层的模型性能,这可能是因为48个神经元已经能够满足MNIST数据集,添加更多的节点会导致过拟合。
检索性能
论文使用48个节点隐藏层的模型生成的48位二进制码,使用海明距离度量。随机从测试集中采集了1000张测试图像,对训练集进行图像检索。论文比较了几种最先进的哈希算法,包括有监督的KSH/MLH/BRE/CNNH/CNNH+,以及无监督的LSH/SH/ITQ。
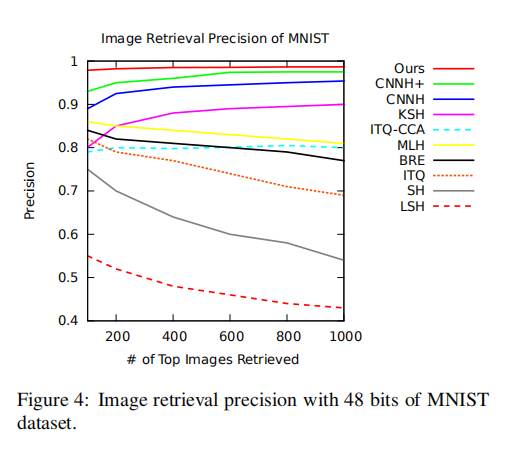
上图4展示了不同算法在不同检索数目下的检索精度,论文提出的深度哈希模型在不同的检索数目下均实现了最好的性能(98.2%正负0.3%检索精度);

上图3展示了
CIFAR10
分类性能
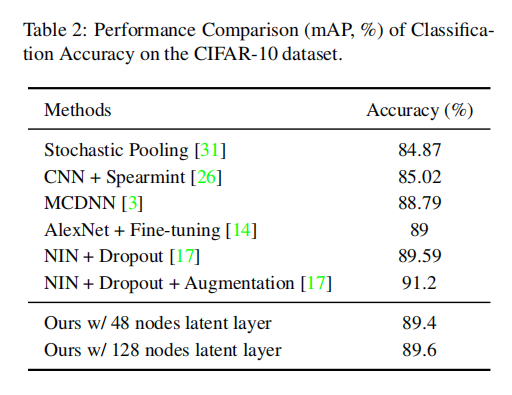
训练设置和MNIST一致,经过5w轮训练后得到89%测试准确率。和其他模型比对如上表2所示,说明在深度CNN模型中嵌入二值隐藏层不会损害模型性能。
检索性能
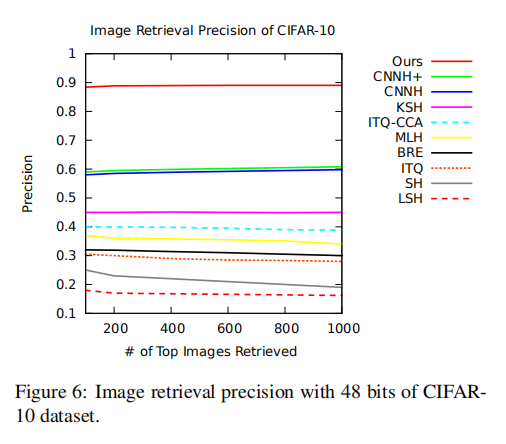
上图6展示了不同算法在不同检索数目情况下的检索精度。论文提出的深度哈希算法在不同检索数目下能够稳定似乎89%检索精度,相比于其他最好的CNNH+,提升了30%精度。

上图5展示了
Yahoo-1M
分类性能
设置Yahoo-1M数据集上微调了75w轮,能够实现83.75%准确率。实现结果如下图7所示:

检索性能
论文设置了4种配置:
AlexNet:仅使用预训练模型的层特征; ES:使用微调训练后的层特征; BCS:使用微调训练后的隐藏层二进制码;HDS:使用微调训练后的层特征和隐藏层二进制码。
当仅使用L2-norm距离进行穷举搜索(或者称为线性搜索);当仅使用二进制码时,基于海明距离进行线性搜索;同时使用1000张检索图像,对数据集进行图像检索。
下图8展示了使用不同配置在不同检索数目下的检索精度。
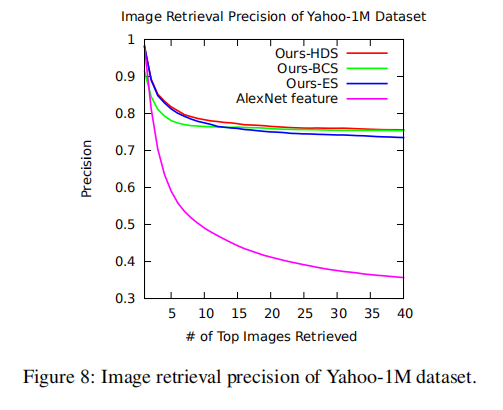
- 经过微调训练后的模型特征(不论是二进制码还是模型特征向量)能够有效的作用于图像检索任务;
- 结合二进制码和特征向量进行分层搜索能够获取到最好的效果,并且在不同检索数目下保持性能稳定。

论文还比较了二进制码的检索时间:
- 在
Geforce GTX780 GPU以及3GB内存下,提取CNN特征需要花费60ms时间; - 在
CPU模式和C++实现下,- 执行两个
4096维特征向量的欧式距离计算需要109.767ms; - 执行两个
128位二进制码的海明距离计算需要0.113ms; - 两者相差
971.3倍。
- 执行两个
小结
很有意思的一篇文章,同时兼顾了检索精度和检索时间,同时简化了训练方式,通过在深度模型中嵌入二进制隐藏层,可以在训练分类模型的同时训练类哈希函数,并且每次计算仅需采集单张图像。
相比于直接计算特征向量,采用哈希函数计算能够节省更多的时间,当检索精度足够的时候,这是一个很好的优化方向。