A ConvNet for the 2020s
官方实现:facebookresearch/ConvNeXt
摘要
The “Roaring 20s” of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model. A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers (e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually “modernize” a standard ResNet toward the design of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.
视觉识别的“轰鸣20年代”始于Vision Transformers(VIT)的引入,它很快的取代了卷积网络成为最先进的图像分类模型。只不过原生ViT无法应用于后续通用的计算机视觉任务(比如目标检测和语义分割),通过重新引入卷积网络模块,分层Transformer(比如Swin Transformers)使得Transformer可以作为通用的视觉backbone,并在各种视觉任务中表现出卓越的性能。然而,这种混合方法的有效性在很大程度上仍然归功于Transformer的固有优势,而不是来自于卷积的归纳偏置属性。在这项工作中,我们重新审视了设计空间并测试了纯卷积网络所能达到的极限。我们基于Vision Transformer的设计逐步将标准ResNet“现代化”,由此发现了几个关键组件,这些组件在扩展过程中对性能有很大影响。这次探索的结果是一个纯卷积网络模型簇,称为ConvNeXt。ConvNeXts完全由标准的卷积网络模块构成,在准确率和可扩展性方面与Transformers相当,达到87.8%的ImageNet top-1准确率,并且在COCO检测和ADE20K分割方面优于Swin Transformers,同时保持了标准卷积网络的简单性和高效性。
引言
在传统图像处理时代,滑动窗口(sliding window)策略已经被证明对于计算机视觉而言是最有效的处理方式(比如Viola-Jones人脸检测器等等),而这正是卷积神经网络自带的属性(卷积层的局部连接+参数共享模式),另外卷积网络的特性(比如平移不变性(translation invariance))也适用于计算机视觉各个领域。
ViT(Vision Transformer)脱胎于NLP领域的Transformer架构,给出了新的视觉处理的视角。通过最开始的patchify层,将图像分割为一组patches,剩余的操作就类似于自然语言的处理。这种操作方式不再考虑图像处理的特性,而且通过Transformer特有的缩放(scaling)属性,借助更大的模型和数据集,ViT的准确率可以大大超过ResNet架构。ViT仅能作用于目标分类领域,因为其全局注意力架构的计算复杂度和图像大小呈二次方比例,无法应用于更高分辨率的输入(比如目标检测/目标分割)。
Swin Transformer是Hierarchical Transformer架构,引入了滑动窗口策略,不再局限于有限的输入图像大小,能够应用于下游的目标检测/目标分割等等方向。ViT能够吸引如此多注意力的原因在于它的性能超过了卷积网络,而关键组件是Transformer的multi-head self-attention设计以及特有的缩放属性。
类似于ST站在Transformer角度结合卷积网络的特性实现最好的性能,论文站在卷积网络的角度,通过调研ST的架构设计以及训练方式,并且结合卷积网络发展过程中出现的各种优异组件,逐步将ResNet改造成为类Transformer架构,最后得到一个新的纯卷积网络模型簇 - ConvNeXt。

Roadmap
论文首先参考ViT训练配置来训练ResNet50,将得到的结果作为基准;然后研究一系列设计决策来对ResNet50进行改造:
- 宏架构(
Macro design) ResNeXt- 反向瓶颈层(
Inverted bottleneck) - 更大的卷积核(
Large kernel size) - 微架构(
Various layer-wise micro designs)
下图2是在改造过程中每一步得到的模型性能评估(基于ImageNet-1K数据集)
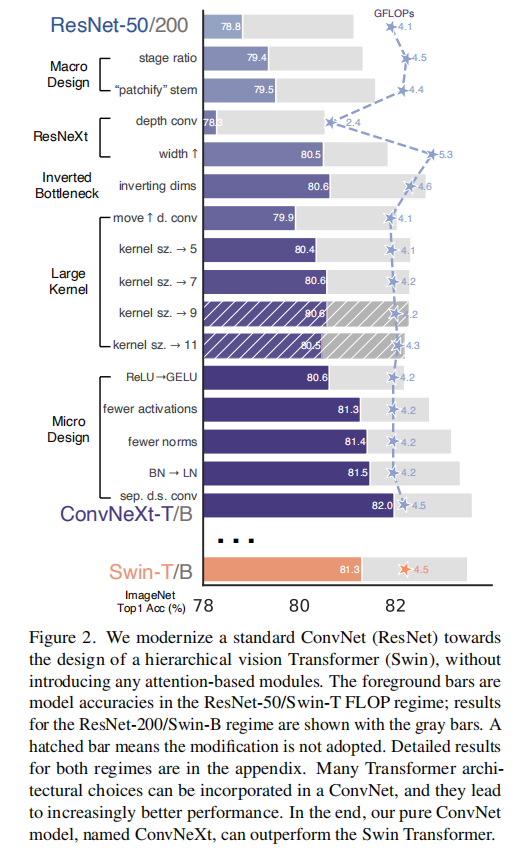
训练技巧
论文重新设计了训练策略,参考了DeiT和Swin Transformer训练技巧:
- 训连轮数从
90轮扩展到300轮; - 使用
AdamW优化器; - 数据增强策略包括
Mixup、Cutmix、RandAugment、Random Erasing; - 正则化策略包括
Stochastic Depth、Label Smoothing。
更完整的训练配置参考下面实验章节
除了基准训练以外,
- 创建
ConvNeXt基准模型之前该找过程中均采用这个训练配置(除了禁止EMA,因为实验发现它会损害BN层训练); ConvNeXt模型簇的训练均采用这个配置(除了随机深度比率(stochastic depth rate)会基于变体自定义)。
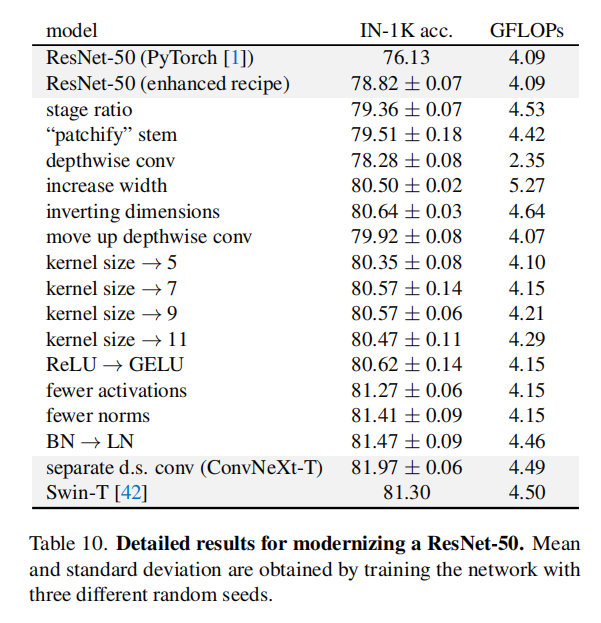
在基准训练完成后,ResNet50准确率从76.1%提升到78.8%(+2.7%)。
Macro Design
Swin Transformer遵循了ConvNets架构,实现了多阶段(multi-stage)设计,每个阶段拥有不同的输入特征图大小。论文重点参考了其中两个特性:
- 调整每个阶段的深度
- 分块化
stem层
深度调整
Swin Transformer遵循了ResNet设计理念,每层拥有不同数目的blocks,只不过调整了块比率:对于Swin-T,阶段计算率(stage compute ratio)是1:1:3:1;对于更大的Swin Transformer而言是1:1:9:1。论文遵循了这一设计理念,将ResNet50每个阶段的块数目(3, 4, 6, 3)调整为(3, 3, 9, s3)。调整后的ResNet50的FLOPs类似于Swin-T,准确率从78.8%上升到79.4%。
论文也指出拥有更高效的块比率实现,不过对于ConvNeXt而言就使用这个设置了。
Patchify
stem层的目的在于下采样输入图像大小:
ResNet:stem层设计为使用卷积层(核大小,步长为 2)+ 最大池化层;ViT:stem层设计为仅使用卷积层(14或者16大小的卷积核,non-overlapping设计,也就是步长也为14或者16);Swin Transformer:类似于ViT设计,使用卷积核步长设置为4。
论文参考了ST设计(称之为patchify stem),使用核大小为4的卷积层作为stem层。调整后的ResNet50准确率从79.4%上升到79.5%。
ResNeXt-ify
论文参考了ResNeXt网络的设计思路:通过分组卷积减少FLOPs,同时扩展宽度来弥补损失的性能(use more groups, expand width)。论文最后使用的是深度卷积结构(分组卷积的特例,分组数等同于通道数,仅执行逐通道的空间信息融合),同时参考Swin-T设计,将通道数从64扩展到96。调整后的ResNet50准确率上升到80.5%,同时FLOPs增加到5.3G。
反向瓶颈层
论文参考了Swin Transformer中反向瓶颈层的设计(即中间隐藏层的膨胀维度是输入维度的4倍),对ResNet50的瓶颈层进行调整,如下图3中图(a)和图(b)所示:
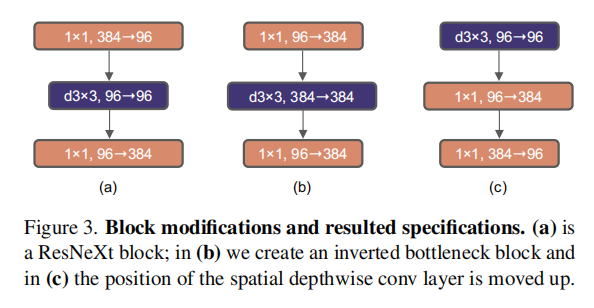
上图(b)应该写错了吧,最后一层应该是384 -> 96才对
虽然深度卷积层增加了FLOPs,但是下采样瓶颈层的shortcut ResNet50的FLOPs减小到4.6G,同时准确率从80.5%提升至80.6%。在ResNet-200/Swin-B架构中,提升性能更明显(81.9% to 82.6%)。
更大的卷积核
ViT和卷积网络最大的差别之一在于全局注意力(non-local self-attention)设计,它允许每个层拥有一个全局感受野。而对于卷积网络而言,更倾向于通过堆叠VGGNet,经过多年的发展也拥有高效的硬件支持。虽然Swin Transformer调整为在局部感受野中执行注意力操作,但是感受野大小为
- 上移深度卷积层;
- 增加卷积核大小。
最终实现如下图4所示:
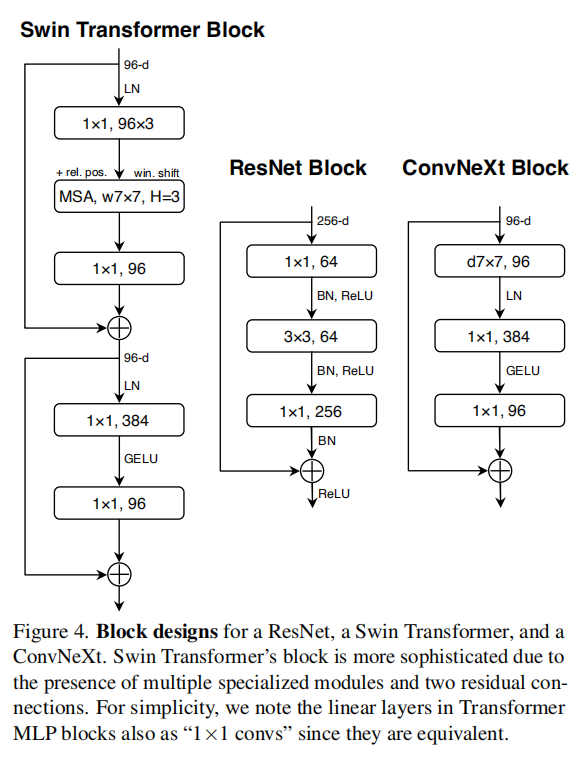
上移深度卷积层
参考Transformer MSA块设计,将反向瓶颈层的深度卷积上移。这一步减少了计算量到4.1G,同时退化性能至79.9%。
增加卷积核大小
论文实验了不同尺寸的卷积核大小:3/5/7/9/11。性能随着感受野增加逐步提高,从79.9%(3x3)上升到80.6%(7x7),同时网络FLOPs几乎保持不变。论文在更大的架构(ResNet-200)上也进行了实验,发现
Micro Design
下面论文专注于层级别的优化,主要有
- 使用
GELU替换ReLU; - 更少的激活函数;
- 更少的归一化层;
- 使用
LN代替BN; - 单独的下采样层。
使用GELU替换ReLU
最初的ViT仍旧使用ReLU(Rectified Linear Unit),但是最新发展的Transformer架构均使用了GELU(Gaussian Error Linear Unit)。论文同样对ResNet50进行了替换,准确率没有变化(80.6%)。
更少的激活函数
Transformer和ResNet的块差别之一就是Transformer拥有更少的激活函数。在Transformer块结构中,拥有key/query/value线性嵌入层(linear embedding layer)、投影层(projection layer)和两个线性层,但是仅拥有一个激活函数;而在ResNet块结构中,每个卷积层之后均跟随一个激活函数。
论文参考了Transformer块结构设计,在每个ResNet块结构中消除多余的激活函数,仅在两个GELU。通过这种方式,准确率提高了0.7%,上升到81.3%,匹配Swin-T的性能。
更少的归一化层
Transformer块结构拥有更少的归一化层,论文参考了这一设计,移除了两个BN层,仅在BN层。这一调整提升性能至81.4%,超越了Swin-T网络。
论文通过训练发现在块最开始阶段增加BN层并不会提升性能。
使用LN代替BN
BN(Batch Normalization)层能够帮助减少过拟合并加快训练收敛,不过研究人员也发现BN还有许多复杂之处,可能会对模型的性能产生不利影响。在Transformer结构中LN(Layer Normalization)替代了BN,论文参考了这一设计。在原始ResNet50网络中,直接使用LN替代BN会导致性能下降;但是在调整后的ResNet50网络中,执行这一操作可以提升性能,准确率达到81.5%。
单独的下采样层
在ResNet设计中,每个阶段的第一个残差块执行下采样任务,使用步长为2的shortcut连接,使用步长为2的Swin Transformer设计中,在每个阶段之间单独设置了一个下采样层。论文采纳了这一设计,在每个阶段之间使用步长为2的
这一修改会导致训练不稳定,Swin Transformer增加了归一化层(LN)去提高训练稳定性,共3个位置:
- 在每个下采样层之前;
- 在
stem层之后; - 在最后的全局归一化层之后。
通过这一调整,最终的准确率达到82%,显著超越了Swin-T的81.3%。
结语
上述修改将ResNet-50改造成为ConvNeXt-T。它和Swin-T相比,拥有近似相同的FLOPs、参数量、吞吐性能和内存占用。每一步调整的FLOPs和准确率变化如下表10所示
具体结构如下表9所示
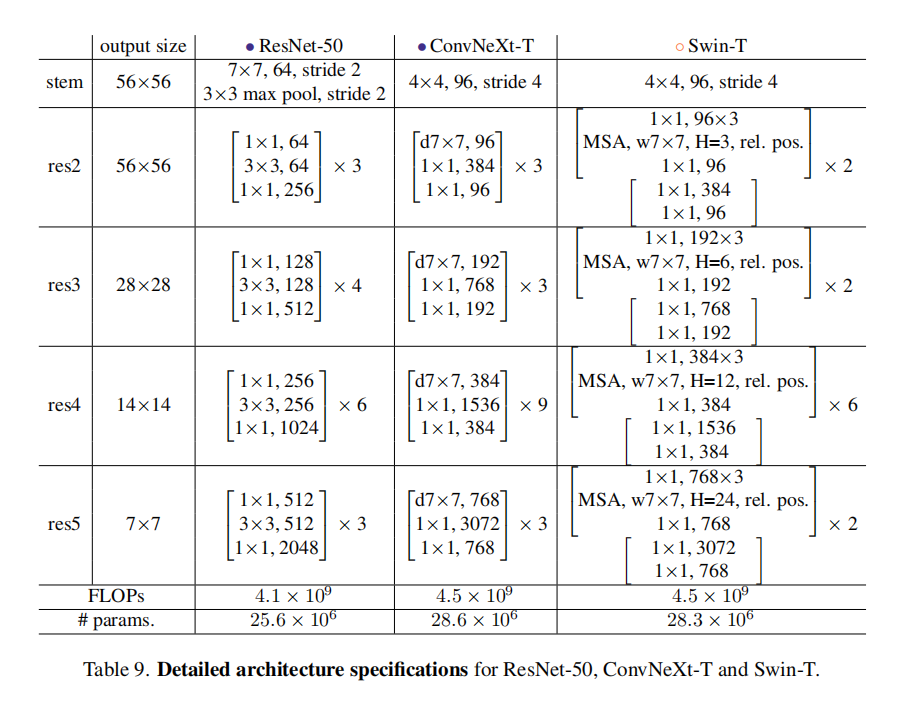
ConvNeXt
ResNet-200/Swin-B
论文还基于Swin-B架构对ResNet-200进行了改造,具体策略和ResNet-50/Swin-T一致,每一步调整后的性能变化如下表11所示:
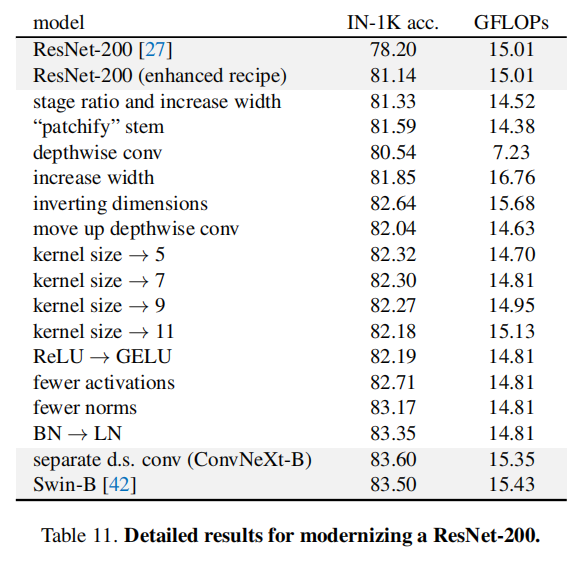
对于ResNet-200而言,每个阶段的块数目为(3, 24, 36, 3),遵循Swin-B的(3, 3, 27, 3)设置。这种调整动态减少了FLOPs,为了保持相近的计算量,将宽度从64提升至84;在采用深度卷积之后,进一步提升至128。
ResNet-200相比于ResNet-50
- 对于反向瓶颈层的设置具有更好的性能增益(
+0.79% vs. +0.14%); - 另外增大卷积核大小为
5(不是7)达到最佳性能(为了保持统一架构,所以最后都配置了7x7大小卷积核); - 使用更少的归一化层能够获取更大的性能增益(
+0.46% vs. +0.14%)。
整体架构
论文构造了网络ConvNeXt-T/S/B/L,它们分别和Swin-T/S/B/L拥有相似的复杂度。其中ConvNeXt-T/B分别是改造ResNet-50/Swin-B和ResNet-200/Swin-T的最终产物。论文还进一步放大得到ConvNeXt-XL。ConvNeXt模型簇仅仅在每个阶段的通道数ResNet和Swin Transformer设计,下一阶段的通道数双倍于上一阶段,详细参数如下图所示

实验
训练设置
论文尝试了两种训练方式:
- 直接在
ImageNet 1K数据集上训练; - 先在
ImageNet 22K数据集上预训练,然后在ImageNet 1K数据集上微调。
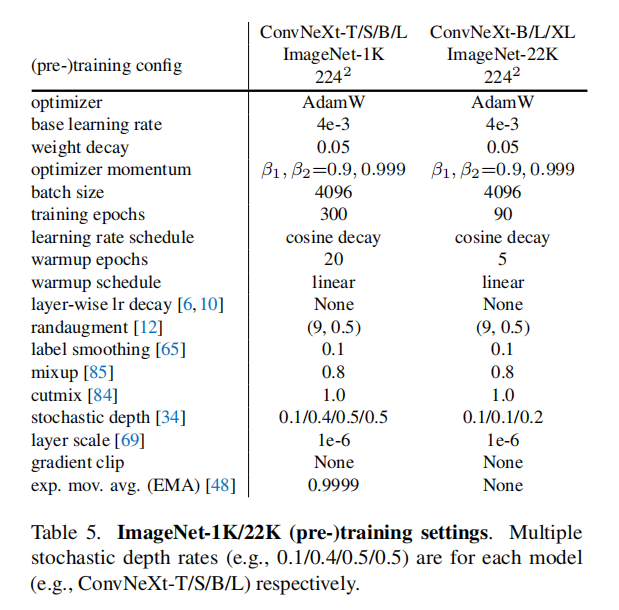
直接训练
- 轮数:
300轮; - 优化器:
AdamW; - 学习率:
4e-3; - 学习率调度:前
20轮linear warmup,后续余弦衰减; - 批量大小:
4096; - 权重衰减:
0.05; - 数据增强:
Mixup + Cutmix + RandAugment + Random Erasing; - 正则化方式:
Stochastic Depth + Label Smoothing; Layer Scale:初始值1e-6;- 其他:
Exponential Moving Average (EMA)(可以缓解大模型的过度拟合)
预训练
预训练设置参考直接训练,做了以下3点调整:
- 轮数:
90轮 warmup:前5轮- 禁止
EMA。
微调训练
微调训练参考直接训练,做了如下调整:
- 轮数:
30轮 - 优化器:
AdamW - 学习率:
5e-5 - 学习率调度:余弦衰减 + 分层学习率衰减(
layer-wise learning rate decay) - 禁止
warmup; - 批量大小
512; - 权重衰减:
1e-8。
默认的预训练、微调训练和测试使用的输入分辨率均为224x224。论文额外微调了384x384输入图像,应用于直接训练和预训练模型。
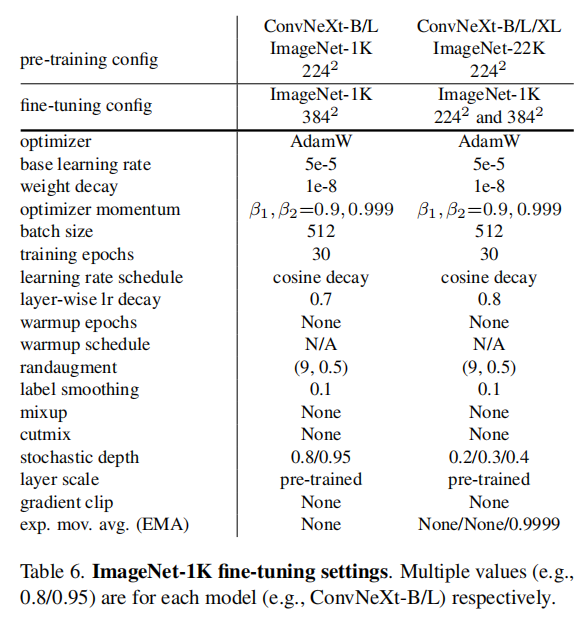
论文观察到即使预训练阶段EMA(直接训练ImageNet-1K或者ImageNet-22K)被使用了,微调使用EMA并不会导致性能提升(除了ConvNeXt-L,使用在ImageNet-1K上的预训练模型进行微调,如果不使用EMA,性能显著下降)。
- 在微调阶段,使用分层学习率衰减(每
3个块组成一个组); - 当微调输入图像大小为
224x224时,测试阶段的裁剪率为0.875; - 当微调输入图像大小为
384x384时,测试阶段的裁剪率为1.0(即不裁剪)。
测试结果
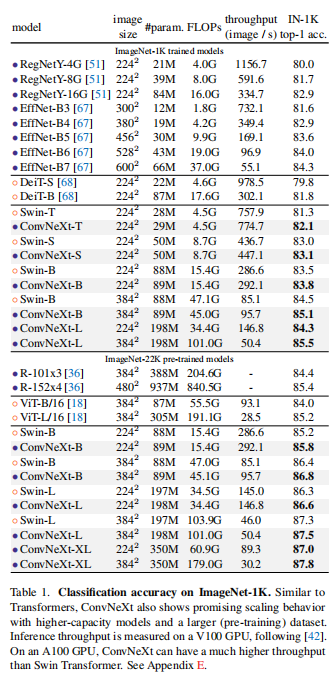
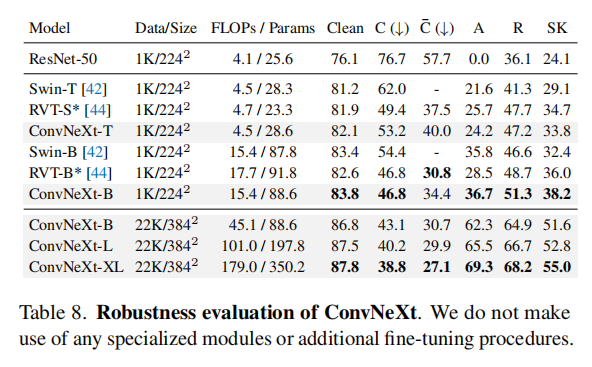
ConvNeXt vs. ViT
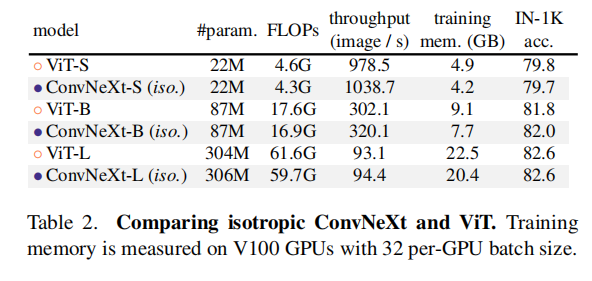
论文同时调整了ConvNeXt架构以匹配ViT设计,基于ViT架构,论文同样超越了ViT性能。
下游任务
。。。
小结
这是一篇非常工程化的文章,详细的把每一步调整和变化都记录下来。通过整篇论文的描述,可以发现Transformer结构中融入了很多的卷积网络特性,同样的,在卷积网络中融入Transformer特性也能获取性能提升。
另外,从论文实现中也可以发现,模型架构是核心,训练配置也是关键因素,包括更长的训练轮数、更好的优化器/学习率调度器、更丰富的数据增强策略和正则化策略。
到目前为止,目标分类还是计算机视觉最基础也最关键的研究领域,在目标分类中出现的新架构和新模型对于下游的检测/分割/识别均有强大的推动作用。
最高准确率是一个关键指标,其他的FLOPs、模型大小、训练时间、推理时间等等都是后续关注的内容,就像Swin Transformer一样,只要获取了最高的准确率,虽然实用性不强,但是自然的会成为学术界的研究热点,更多人和资源会投入到其中,总会有后续的优化出现。
几个问题:
- 这会不会是纯卷积网络最后的回光返照,毕竟最后效果只是和
Swin Transformer相近(当然这也是论文的预设前提); - 论文针对
ResNet进行了手动改造(ResNet是2015年发布的),获取得到ConvNeXts。目前最好的纯卷积网络应该是EfficientNet系列,那么是不是也可以基于EfficientNets进行手动改造呢? - 手工设计的
ConvNeXt能够达到最好的效果,是不是NAS还可以继续出新的架构? - 计算机视觉+深度学习的发展已经走过十年了,卷积神经网络发挥了最关键的作用。下一个十年,什么才是核心,
Transformer?还是说ConvNet + Transformer? - 对于
Swin Transformer而言,是否可以通过剪枝、蒸馏、量化来进一步推动落地 ?