激活函数
介绍激活函数及其特性
- Sigmoid
- Tanh
- ReLU
- Leaky ReLU
- Maxout
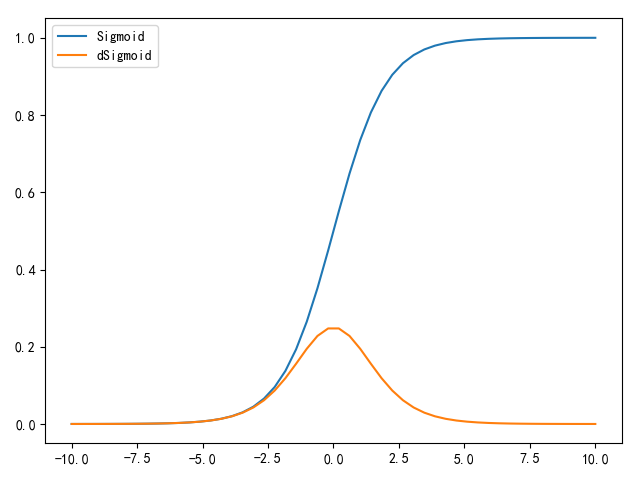
Sigmoid
Sigmoid函数是最早出现的激活函数,估计是因为逻辑回归模型的缘故
它能够将输入数据压缩到[0,1]之间,值越小,越接近于0;值越大,越接近于1。数学公式如下:
目前基本不使用Sigmoid作为激活函数,主要有两个缺陷
- 当激活值处于饱和(
saturate)状态(接近0或1),此时得到的梯度几乎为0(如下图所示),也就是说无法在反向传播过程中对权重进行有效更新,网络也将停止学习。所以初始化权重值不能过大,否则会导致激活函数饱和 - 因为
Sigmoid的取值范围是[0,1],所以其输出不是零中心(zero-centered)。如果输入的数据总是正值,会导致计算得到的梯度值变为全正或全负(依赖于线性运算的表达式)。非零中心会导致权重更新时呈 字形下降,这个问题可以通过初始化权重时平衡正负值来减轻影响
1 | def sigmoid(x): |
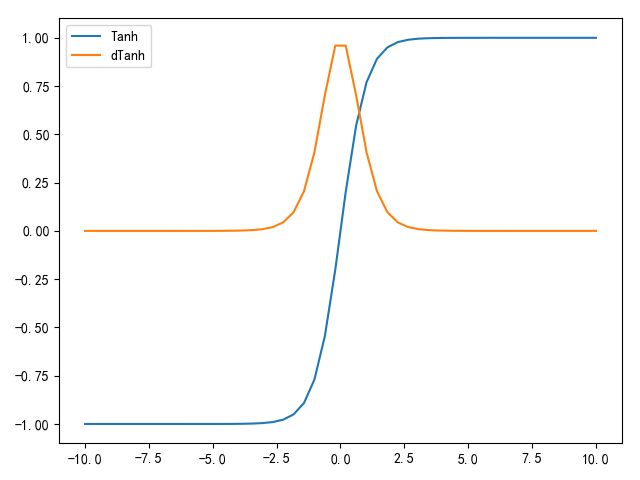
Tanh
Tanh(全局正切)函数在Sigmoid函数的基础上进一步发展,其将取值压缩在[-1,1]之间,值越小,越接近于-1;值越大,越接近于1。数学公式如下:
其中
所以
根据公式可知,
1 | def tanh(x): |
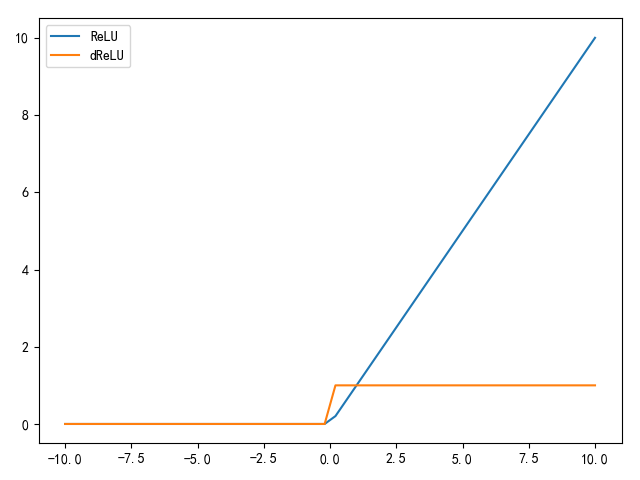
ReLU
ReLU(Rectified Linear Unit,整流线性单元)激活函数是因为在AlexNet网络中的使用而得到了推广。当输入小于0时,输出为0;否则,输入为输出值。其数学公式如下:
$$
\frac {\varphi f(x)}{\varphi x}=
\left{
=1(x\geq 0)
$$
优势如下:
- 计算高效。达到同样训练误差率的时间,使用
ReLU能够比tanh快6倍 - 实现简单。相比于
sigmoid/tanh需要指数运算,ReLU仅是线性阈值操作
缺陷如下:
- 输出值没有零中心
- 当输入值小于
0时,梯度消失,权值不再更新
如果步长(learning rate,学习率)设置过大,有可能导致梯度更新后,神经元线性计算结果永远小于0,无法再次更新权值,也就是说这个神经元在训练过程中死亡了,所以需要合理设置步长大小
1 | def relu(x): |
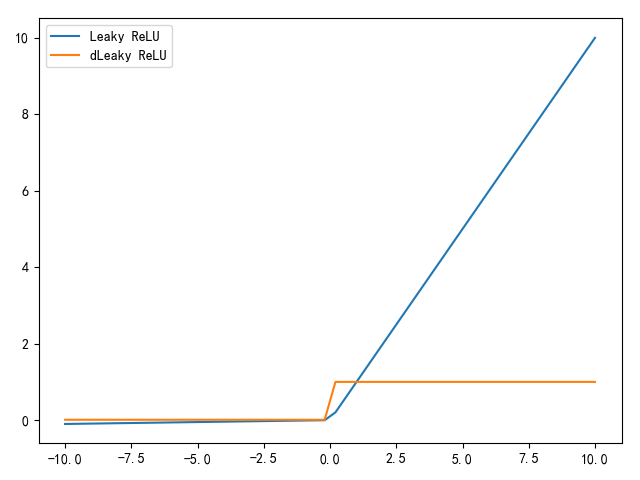
Leaky ReLU
Leaky ReLU试图解决ReLU单侧梯度消失的问题,其实现公式如下:
$$
\frac {\varphi f(x)}{\varphi x}=
\left{
$$
其中
1 | def leaky_relu(x, a=0.01): |
小结
推荐使用顺序:ReLU > Leaky ReLU > Tanh > Sigmoid