Rethinking of Pedestrian Attribute Recognition
官方实现:valencebond/Rethinking_of_PAR
摘要
Pedestrian attribute recognition aims to assign multiple attributes to one pedestrian image captured by a video surveillance camera. Although numerous methods are proposed and make tremendous progress, we argue that it is time to step back and analyze the status quo of the area. We review and rethink the recent progress from three perspectives. First, given that there is no explicit and complete definition of pedestrian attribute recognition, we formally define and distinguish pedestrian attribute recognition from other similar tasks. Second, based on the proposed definition, we expose the limitations of the existing datasets, which violate the academic norm and are inconsistent with the essential requirement of practical industry application. Thus, we propose two datasets,
and , constructed following the zero-shot settings on pedestrian identity. In addition, we also introduce several realistic criteria for future pedestrian attribute dataset construction. Finally, we reimplement existing state-of-the-art methods and introduce a strong baseline method to give reliable evaluations and fair comparisons. Experiments are conducted on four existing datasets and two proposed datasets to measure progress on pedestrian attribute recognition.
行人属性识别的目标是为视频监控摄像头拍摄到的行人图片赋值多个行人属性。尽管已经提出了很多的方式并且也得到了很大的提升,但是我们认为现在是时候去重新分析这个领域的现状。我们从三个视角重新回顾和思考最近取得的进展。首先,目前并没有关于行人属性识别明确且完整的定义,对此我们正式定义行人属性识别,并且指出它和其他相似任务不一样的地方。其次,基于我们的定义,我们发现了行人属性识别数据集的缺陷,它们违反了学术规范并且和实际工业应用的需求并不匹配。因此,我们提出了两个新的数据集:
引言

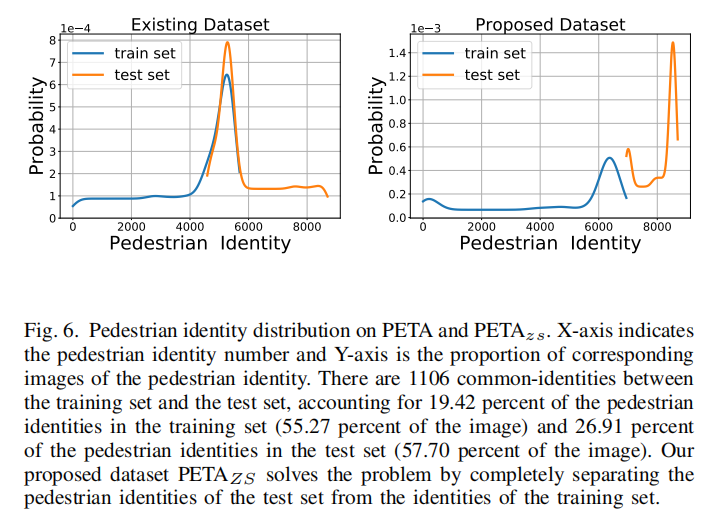
已有的数据集在训练集和测试集上存在相同行人身份的数据,这个不符合实际环境(往往生产条件下遇到的都是新的人物)。作者提出zero-shot pedestrian identity的标准,保证训练环境和测试环境不存在相同的人物。上图一比对了RAP和
行人属性识别(pedestrian attribute recognition)任务和人类属性识别(human attribute recognition)任务的关键差异性在于裁剪后的行人图片(cropped pedestrian images):PAR得到的行人图片都是低分辩率并且是完整的行人图片(low-resolution, and the entire pedestrian body is located in the center of the images.)。如下图2所示。

作者详细的评估了4个已有的数据集:PETA/RAP1/RAP2/PA100K,之前的论文在这些数据集上面的实验或多或少存在缺陷:
- 简单的将样本划分为训练集和测试集,并没有评估集,这样无法准确的测试算法的泛化性能;
- 存在数据泄漏(
data leakage):训练集和测试集之间存在相同的行人身份,这些数据之间仅存在很小的背景差异性以及姿态变化。
论文贡献有三个方面:
- 对于PAR给出明确定义:
- 行人属性识别是什么?(What is pedestrian attribute recognition?)
- 行人属性识别与其他类似任务的本质区别是什么?(What is the essential characteristic of pedestrian attribute recognition different from other similar tasks?)
- 提出新的数据集和评估协议:
- 现有数据集不能够真正的测量出行人属性识别方法的性能;
- 新的数据集和评估协议可以更正确的进行测量。
- 进行了完备的实验:
- 对于现有的方法,在已有的数据集和新提出的数据集上,在相同实验条件设置下的性能;
- 测试了不同的实验因素对于算法的性能影响。
定义
确切定义
论文给出了行人属性识别的确切定义:给定训练集合,由一组输入-目标对(input-target pairs)
相似任务
- 行人属性识别 vs. 人类属性识别(
human attribute recognition)- 差异点一:
- 行人属性识别数据集的数据中大多数仅包含一个行人,并且它位于图像中心;
- 人类属性识别数据集的数据中有可能包含多个姿态差异巨大的人类。
- 差异点二:
- 行人属性识别的数据通过监控摄像头收集,通常是低分辨率;
- 人类属性识别的数据通过网络检索收集,通常是高分辨率。
- 差异点三:
- 行人属性识别的数据可以提供辅助信息来帮助行人追踪;
- 人类属性识别的数据无法提供相关信息。
- 差异点一:
- 行人属性识别 vs. ReID相关属性识别(
ReID-related attribute recognition)- 行人属性识别的属性标注基于实例级别(Instance Level),也就是基于当前图像中的行人数据;
- ReID相关属性识别的标注基于对象级别(Identity Level),具体示例如下图3所示。

数据集
已有数据集
- PETA((PEdesTrian Attribute):包含19000张图片,拥有61个二值属性以及4个多类别属性。这些数据来自于10个小数据集;
- RAP (Richly Annotated Pedestrian):拥有41585张图片,通过商场的26个视频摄像头采集得到,拥有69个细粒度属性以及3个环境因子(视点、遮挡样式和身体部位);
- RAP2:基于RAP,拥有84928张图片和72个属性;
- PA-100K (Pedestrian Attribute):拥有100000张图片,26个属性。
这些数据集中测试集和训练集存在相同对象的分析如下图所示:

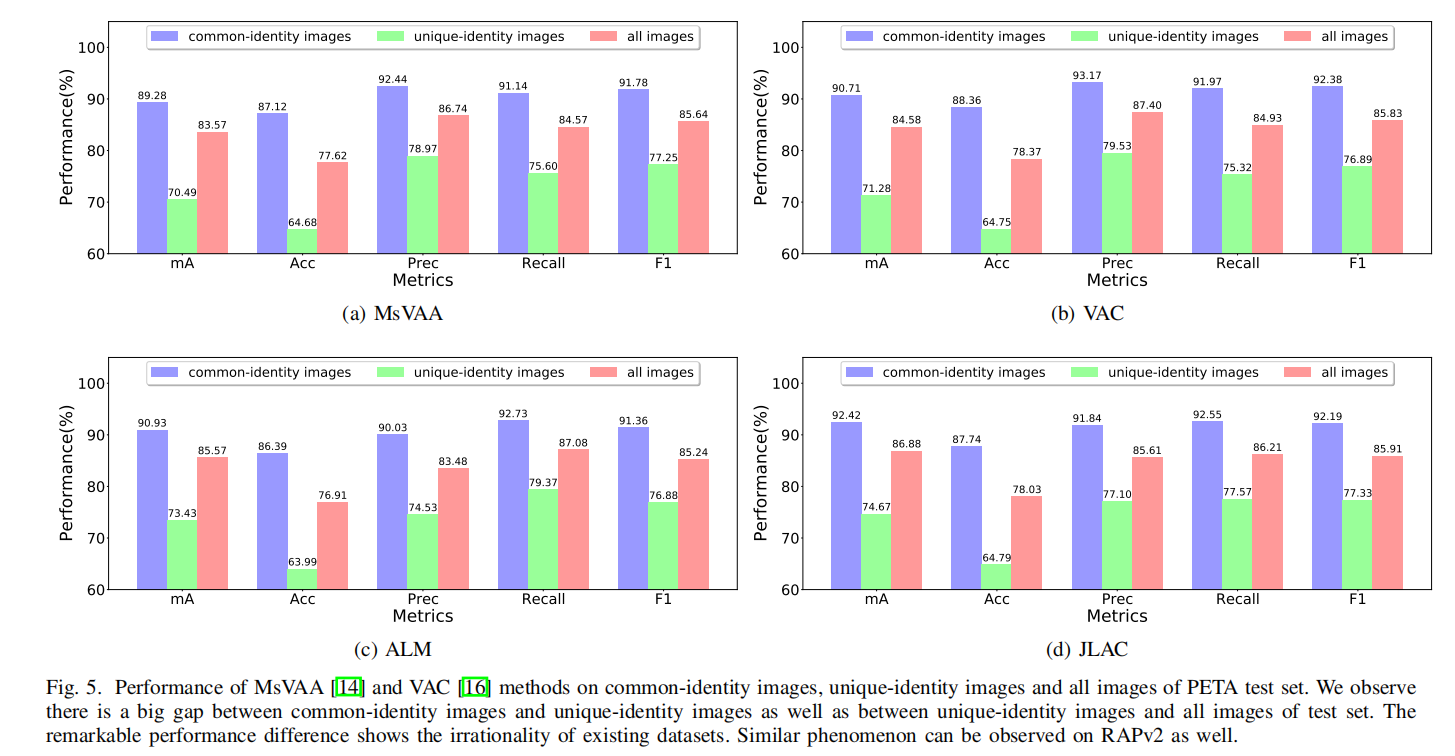
论文复现了4个最先进的方法(MsVAA/VAC/ALM/JLAC),比较了这些方法对于common-identity(对象同时出现在训练集和测试集)和unique-identity(对象仅出现在测试集)的性能差异(就是common的好,unique的差),揭示了数据泄漏导致的不准确评估。
划分标准
论文提出了5条具体的划分标准,涉及训练集/测试集/验证集的数据划分、不同属性的正负样本比例以及分布。

, , 分别表示行人对象(一个对象可以有多张图片)的训练集、验证集和测试集; 表示集合基数,也就是该集合的元素个数; 和 表示验证集和测试集的样本个数; 和 表示验证集和测试集第 个属性的正样本比例; 、 、 是阈值,分别控制了验证集和测试集中对象数量、图像数量和属性正样本数量的差异性。

具体的数据集划分实现上图所示,通过新的划分策略,论文提出了两个新的数据集
算法
给定训练集
表示损失函数; 表示特征提取器; 表示分类器; 和 分别表示特征提取器和分类器的参数;
测试阶段,输出结果还会输入到sigmoid函数进行最终的预测:
$$
\hat{y}{ij}=\begin{cases}
1 & \text{ if } p{ij}\geq t_{cls} \
0 & \text{ if } p_{ij}< t_{cls}
\end{cases}
$$
是sigmoid函数; 表示分类阈值; - 输出概率向量表示为
; ,表示第 个图像在第 个属性上的概率。
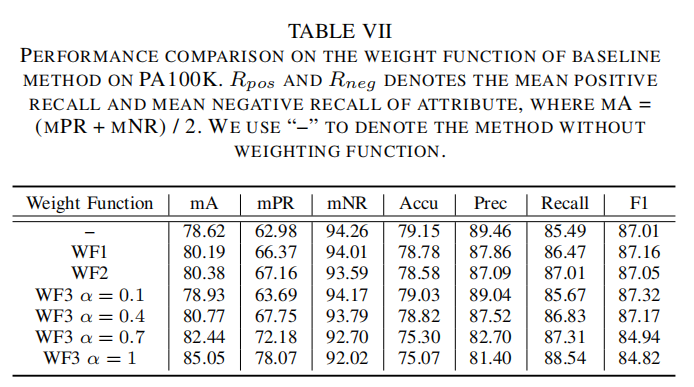
论文新提出了行人属性识别的基准方法,它采用二元交叉熵损失(binary cross-entropy loss),并且增加了权重函数,具体格式如下:
其中
表示训练集中第 个属性的正样本比例;
最后一个更复杂,据论文说是为了解决通用的长尾分布问题。
是一个超参数,用于调节正样本率和负样本率之间的权重。论文将上述3个公式分别命名为 、 和 ,并进行了消融实验,如下表所示。
实验
数据集和评估标准
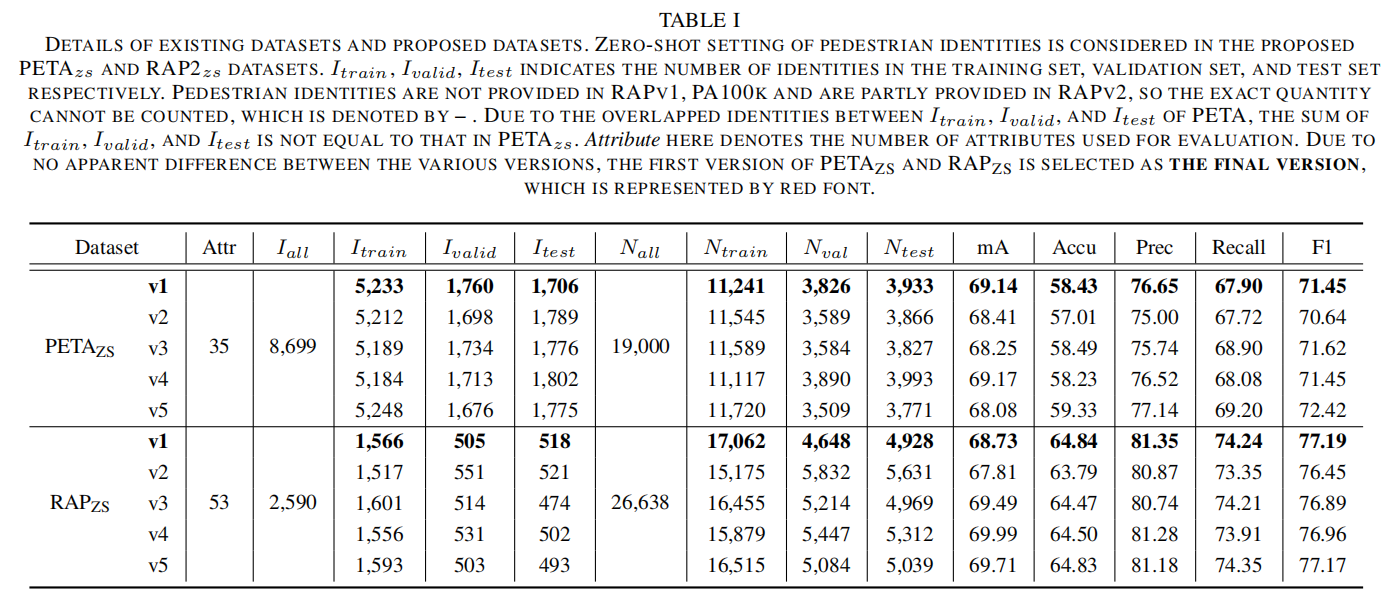
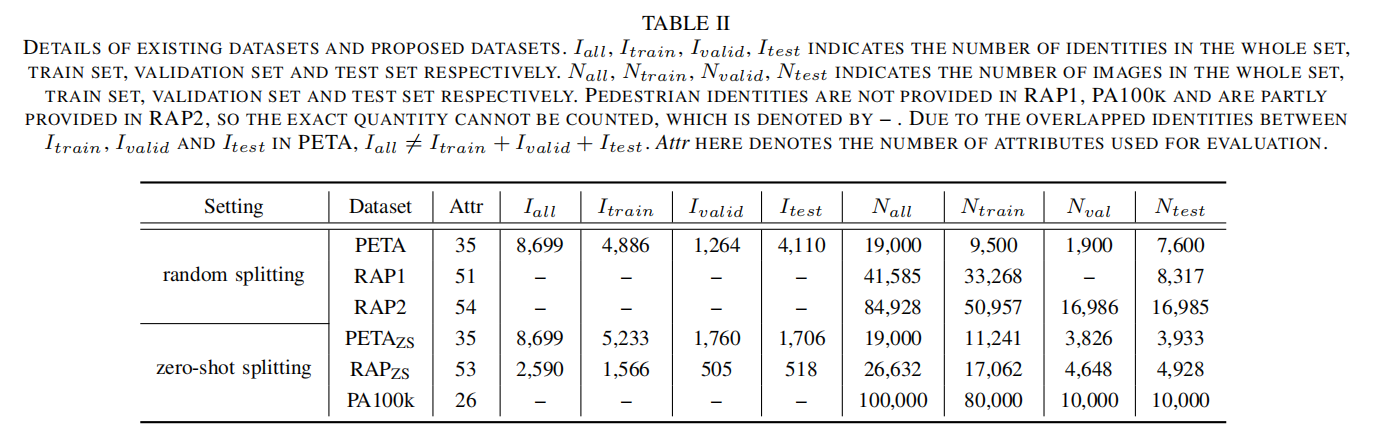
论文针对6个数据集,分别采用两种采样方式(随机采样和零样本采样)得到训练集和测试集,图下表2所示:
另外,论文设置了5个评估标准。4个实例级别(Instance Level)的度量,包括准确率(ACC)、精度(Precision)、召回率(Recall)和F1-score,具体计算公式如下:
表示第 个样本的真阳性(标注为1,预测为1)属性数量; 表示第 个样本的假阳性(标注为0,预测为1)属性数量; 表示第 个样本的假阴性(标注为1,预测为0)属性数量; 表示训练集图像总数。
对于属性级别(Attribute Leval)的度量,采用mA(Mean Accuracy)进行评估,具体计算公式如下:
表示第 个属性的真阳性(标注为1,预测为1)属性数量; 表示第 个属性的真阴性(标注为0,预测为0)属性数量; 表示第 个属性的假阳性(标注为0,预测为1)属性数量; 表示第 个属性的假阴性(标注为1,预测为0)属性数量; 表示训练集中属性类别总数。
实验细节
- 基于Pytorch进行实现,使用ResNet50作为Backbone;
- 作为输入,行人图像被缩放为
(高x宽); - 采用Adam优化器,初始学习率为1e-3,权重衰减为5e-4;
- 。。。
- 。。。
- 默认采用加权函数
。
实验结果
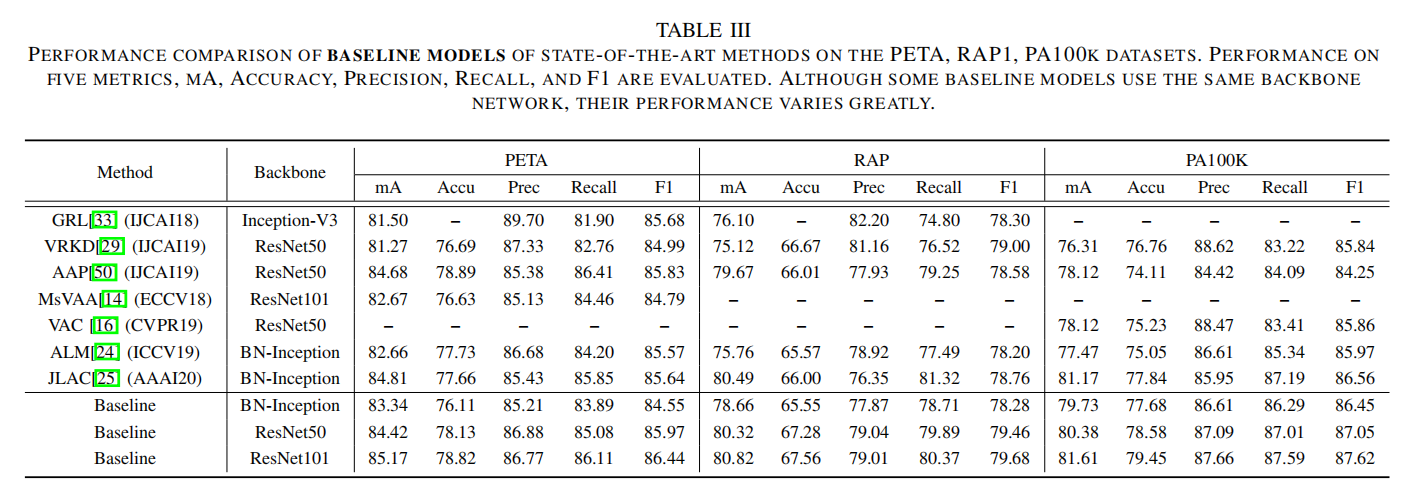
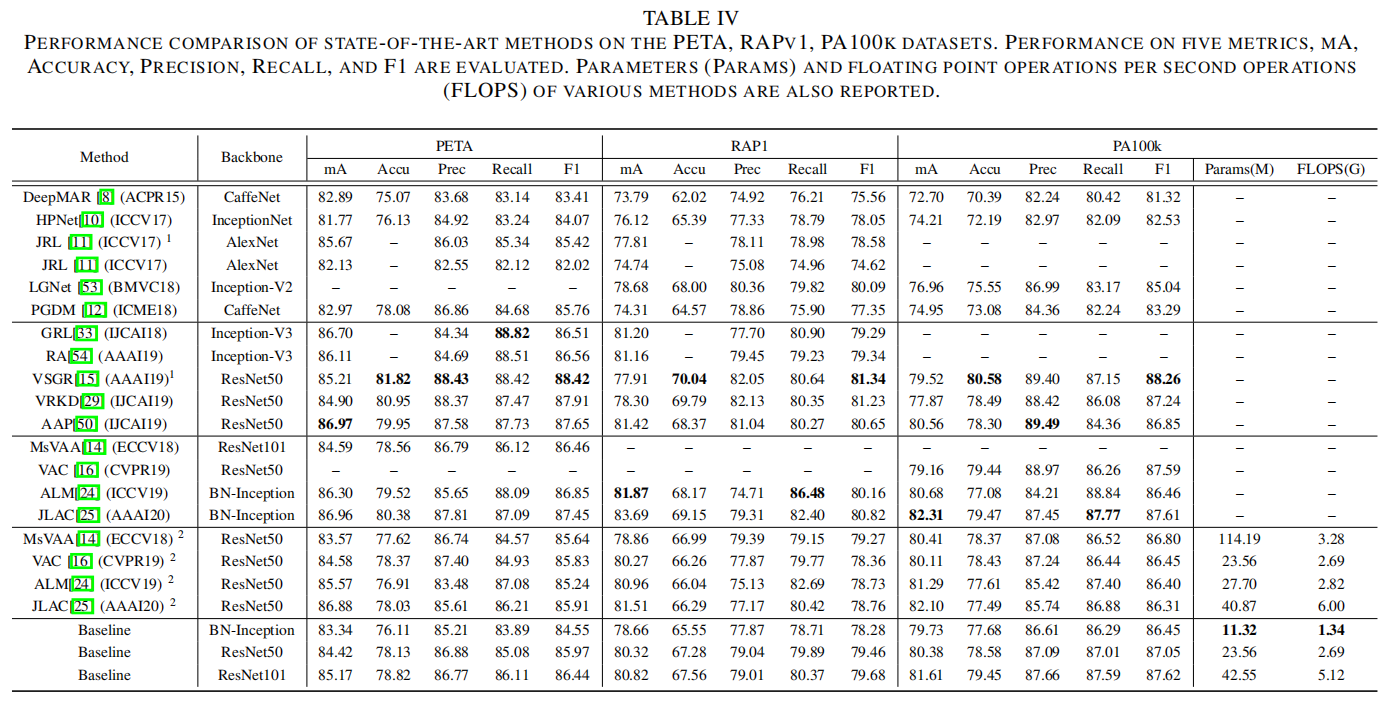
在不同数据集上评估最先进的算法和论文提出的Baseline方法,如下表3和4所示。
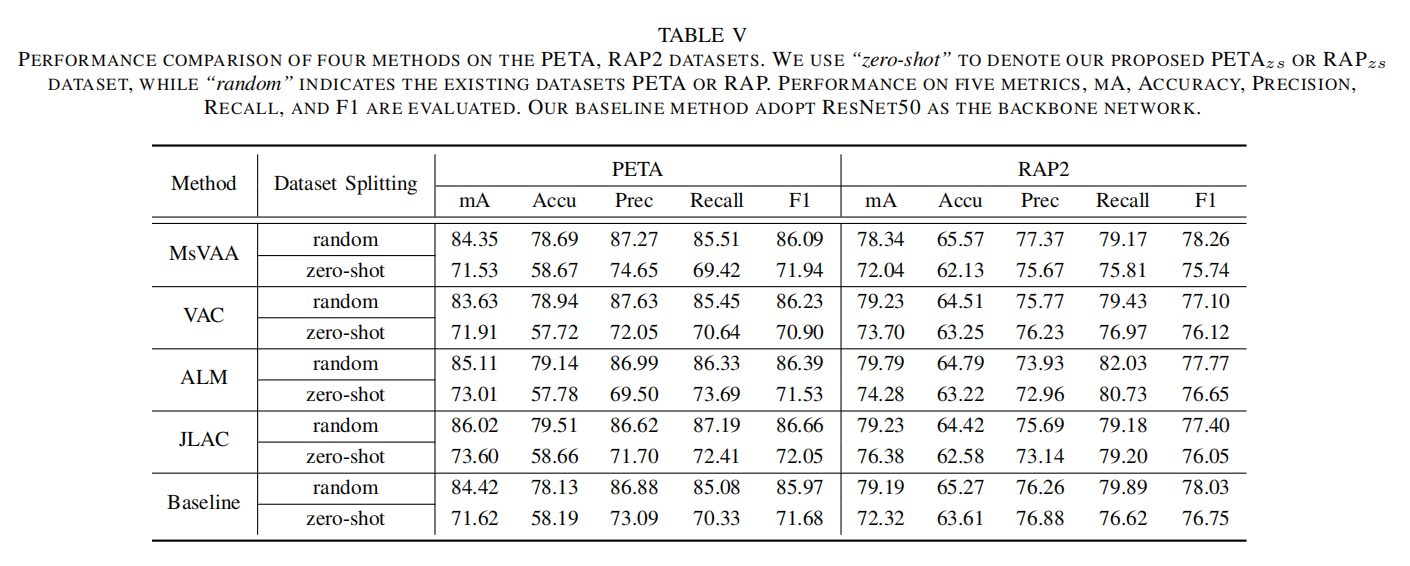
采用不同数据集划分标准,可以发现算法评估结果有很大变化,证明了论文提出的zero-shot的必要性。
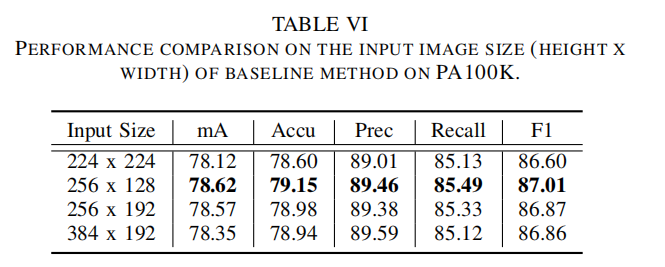
论文还实验了不同输入大小对于Baseline方法的性能影响,如下表6所示,最好的输入设置为
小结
行人属性识别是一个小领域,针对它的研究大体逃不出多分类或者多标签相关的方法,但是它的确存在真实的场景需求,并且随着深度学习算法的成熟和落地,它的实际应用会越来越广泛,比如视频监控场景/自动驾驶场景的行人分析。所以在学术任务上如何提出更好的定义和评估方法,确实有它的必要性和关键作用。
这几年在不同视觉任务上陆陆续续出现了不少Rethinking开头的论文,针对这个领域之前的发展进行总结和回顾,并且提出更新的标准来进一步促进学术研究。对于我来说,行人属性识别还是相对好理解的视觉任务,这篇论文的研究思路非常值得我学习和关注,比如对数据集和评估标准进行再分析和优化,然后进行详细的评估实验,就是一篇很优秀的论文。