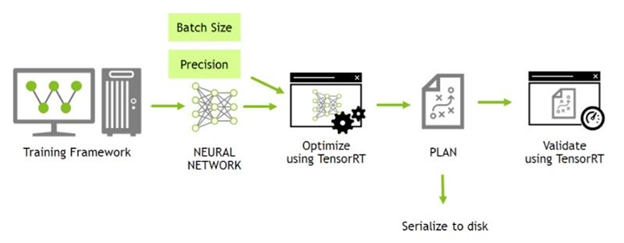
Pytorch分类/检测/分割模型转换到ONNX格式,最后转换成TensorRT Engine文件进行推理(Python)。
Pytorch2ONNX PyTorch提供了内置函数torch.onnx.export ,可以将训练好的模型导出为ONNX格式,从而便于在不同推理框架中部署。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 import numpy as np import onnx import onnxruntime as ort import torch import torchvision def validate_onnx_model(onnx_path: str = "pytorch.onnx") -> None: """ 验证 ONNX 模型是否合法。 Args: onnx_path (str): ONNX 模型文件路径。 """ print(f"Validating ONNX model at {onnx_path}...") onnx_model = onnx.load(onnx_path) onnx.checker.check_model(onnx_model) print("ONNX model is valid.") def compare_outputs(model_input: torch.Tensor, torch_output: torch.Tensor, onnx_path: str = "pytorch.onnx") -> None: """ 使用 ONNX Runtime 推理并对比 PyTorch 和 ONNX 的输出结果。 Args: model_input (torch.Tensor): 输入张量。 torch_output (torch.Tensor): PyTorch 模型的输出。 onnx_path (str): ONNX 模型路径。 """ print("Checking ONNX Runtime support...") print("Supported ORT version:", ort.__version__) print("Available providers:", ort.get_available_providers()) # 初始化推理会话(使用 CPU 执行器) session = ort.InferenceSession(onnx_path, providers=["CPUExecutionProvider"]) # 打印输入输出信息 input_info = session.get_inputs()[0] output_info = session.get_outputs()[0] print("ONNX model info:") print(f" Input: {input_info.name}, Shape: {input_info.shape}") print(f" Output: {output_info.name}, Shape: {output_info.shape}") def to_numpy(tensor: torch.Tensor) -> np.ndarray: return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy() # 构建输入并运行 ONNX 推理 inputs = {input_info.name: to_numpy(model_input)} onnx_output = session.run(None, inputs) # 对比输出结果 print("Comparing outputs between PyTorch and ONNX Runtime...") print("PyTorch output shape:", to_numpy(torch_output).shape) print("ONNX Runtime output shape:", onnx_output[0].shape) try: torch.testing.assert_close(torch.from_numpy(onnx_output[0]), torch_output, rtol=1e-3, atol=1e-5) print("✅ Exported model has been tested with ONNX Runtime. The results match!") except AssertionError as e: print("❌ Output mismatch between PyTorch and ONNX Runtime.") raise e if __name__ == "__main__": # 设置模型与输入 print("Loading PyTorch model...") model = torchvision.models.resnet18(pretrained=True) model.eval() # 确保模型处于评估模式 dummy_input = torch.randn(1, 3, 224, 224) onnx_output_path = "./resnet18.onnx" # 导出 ONNX 模型 print("Exporting model to ONNX format...") torch.onnx.export( model, dummy_input, onnx_output_path, export_params=True, # 存储训练参数 opset_version=12, # ONNX 算子集版本 do_constant_folding=True, # 优化常量 input_names=["input"], # 输入名称 output_names=["output"], # 输出名称 dynamic_axes=None # 固定尺寸输入 ) print(f"Model exported to {onnx_output_path}") # 验证 ONNX 模型 validate_onnx_model(onnx_output_path) # 获取 PyTorch 输出用于验证 with torch.no_grad(): torch_output = model(dummy_input) # 比较 ONNX 和 PyTorch 输出 compare_outputs(dummy_input, torch_output, onnx_output_path)
版本兼容 不同的PyTorch版本支持的opset版本范围可能不同,比如在PyTorch 1.13.1中,torch.onnx.export的函数说明:
1 2 3 4 5 ... opset_version (int, default 14): The version of the `default (ai.onnx) opset <https://github.com/onnx/onnx/blob/master/docs/Operators.md>`_ to target. Must be >= 7 and <= 16 ...
可以使用以下脚本打印出ONNX模型的版本信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import onnx model = onnx.load("model.onnx") print("IR Version:", model.ir_version) print("Opset Import:", model.opset_import) print("Producer Name:", model.producer_name) print("Producer Version:", model.producer_version) # OUTPUT IR Version: 7 Opset Import: [version: 12 ] Producer Name: pytorch Producer Version: 1.13.1
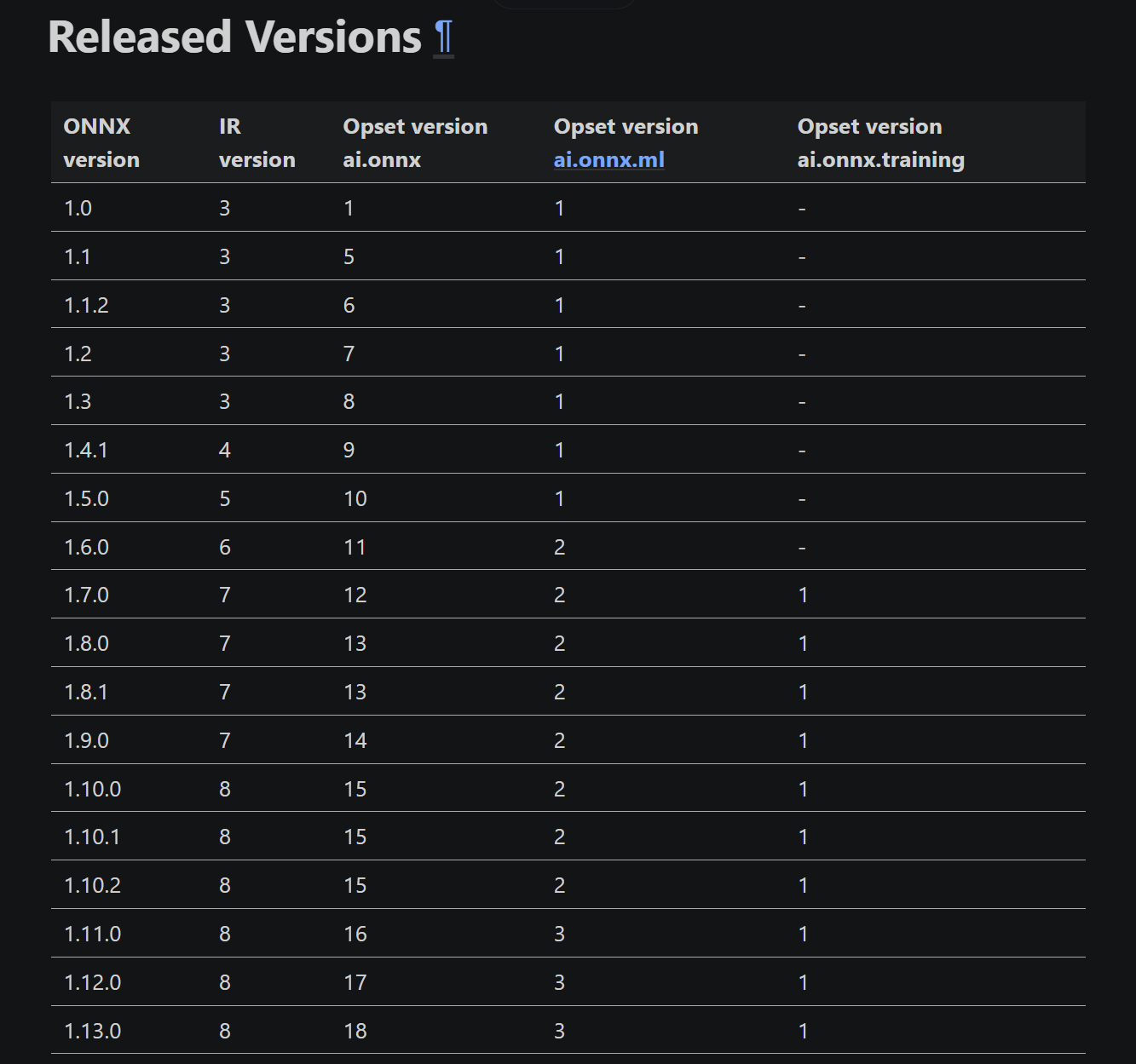
对于ONNX来说,它定义了三种版本号类型:
intermediate representation (IR) specification:表示ONNX图结构和操作符的抽象描述格式,是ONNX模型的基础结构标准;Operator specifications:也就是opset version,表示当前模型所使用的ONNX操作集合版本。每个OpSet包含一组特定的操作符及其行为定义;model version:这是ONNX模型自身的版本号。
这三种版本相互独立,因此一个特定版本的ONNX模型库(即onnx Python包)可能支持多种IR或OpSet版本。具体参考ONNX Versioning
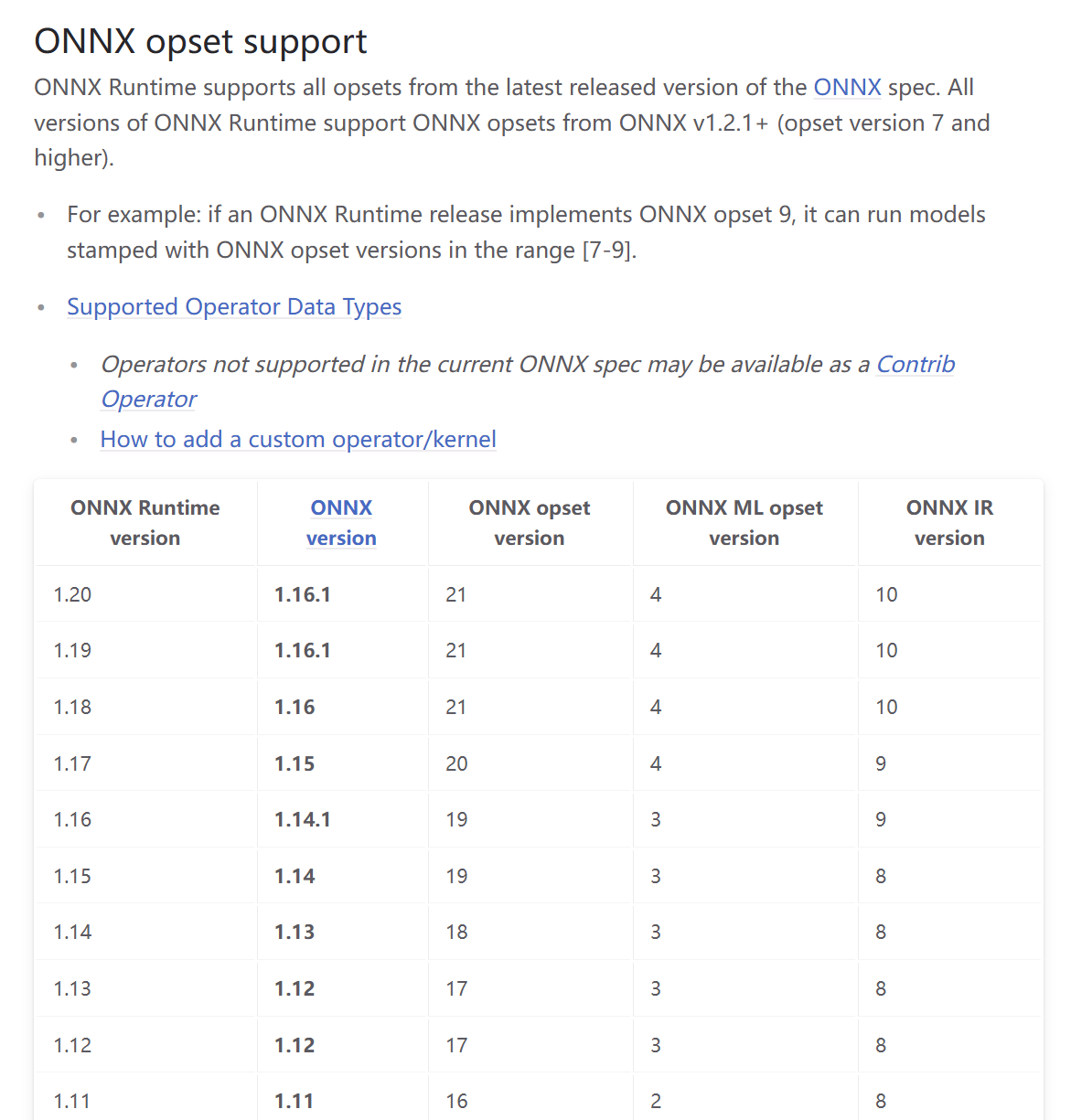
同样的,ONNX Runtime也对ONNX模型的版本有兼容性限制。不同版本的ONNX Runtime支持的ONNX模型版本和OpSet也有所不同。,具体参考ONNX Runtime compatibility
注意:低版本的TensorRT可能不支持高opset_version或高ir_version的ONNX模型。
ONNX2TensorRT 对于ONNX模型转换成TensorRT模型,需要设置好输入大小(固定还是动态)和精度(FP32/FP16)。除了调用API来手动转换外,TensorRT提供了命令行转换工具trtexec :
注意:TensorRT自带了trtexec,位于/path/to/tensorrt/bin/trtexec,比如/usr/bin/tensorrt/bin/trtexec
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 # 全精度转换(固定形状) trtexec \ --onnx=model.onnx \ --saveEngine=model.trt \ --explicitBatch # 半精度转换(推荐用于部署) # 新语法使用--memPoolSize=workspace:4096MiB替换--workspace=4096 trtexec \ --onnx=model.onnx \ --saveEngine=model.trt \ --explicitBatch \ --fp16 \ --inputIOFormats=fp16:chw \ --outputIOFormats=fp16:chw \ --memPoolSize=workspace:4096MiB # 动态形状转换(生产环境最佳实践) trtexec \ --onnx=model.onnx \ --saveEngine=model.plan \ --explicitBatch \ --minShapes=images:1x3x640x640 \ --optShapes=8x3x640x640 \ --maxShapes=16x3x640x640 \ --fp16 \ --inputIOFormats=fp16:chw \ --outputIOFormats=fp16:chw \ --memPoolSize=workspace:4096MiB \ --warmUp=10 \ --duration=30 \ --avgRuns=10
模型加载相关参数
--onnx=<path>:指定输入模型为 ONNX 格式--explicitBatch:启用显式批量模式(Explicit Batch Mode)
引擎生成与保存相关参数
--saveEngine=<path>:保存生成的TensorRT引擎文件(.trt或.plan)
输入数据相关参数
--shapes=<input_name>:<shape>:
定义输入张量的形状(适用于动态形状模型)
示例:--shapes=image:32x3x640x640,scale_factor:32x2
image:32x3x640x640:表示输入图像张量的形状为 [batch_size, channels, height, width],即[32, 3, 640, 640]scale_factor:32x2:表示另一个输入张量 scale_factor 的形状为[32, 2]
--minShapes=<input_name>:<shape>:
定义动态形状模型的最小输入形状
示例:--minShapes=input:1x3x224x224
--maxShapes=<input_name>:<shape>:
定义动态形状模型的最大输入形状
示例:--maxShapes=input:16x3x224x224
--workspace=<size_in_MB>
设置 GPU 内存的工作空间大小(以 MB 为单位)
示例:--workspace=1024
--inputIOFormats=fp16:chw
定义输入张量的格式为 FP16 和通道优先(Channel-Height-Width, CHW)
FP16:表示输入数据将以半精度浮点数(FP16)格式传递CHW:表示输入张量的维度顺序为 [channel, height, width]
--outputIOFormats=fp16:chw
定义输出张量的格式为 FP16 和通道优先(CHW)
性能相关参数
--batch=<size>
设置推理的批量大小(仅在隐式批量模式下有效)
示例:--batch=32
--avgRuns=<num>
计算平均性能时使用的运行次数
示例:--avgRuns=5
构建选项相关参数
--fp16:启用 FP16(半精度浮点数)推理以提高性能
TensorRT TensorRT不同版本的变化非常大,往往不能够兼容,所以转换和推理实现均在同一个TensorRT环境下实现。
1 2 # python -c "import tensorrt as trt; print(trt.__version__)" 7.2.2.1
Docker Nvidia提供了配置好依赖环境的Docker镜像,可以在容器中进行模型转换和推理:
1 2 docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:20.12-py3 docker run -it --runtime nvidia --gpus=all --shm-size=16g -v /etc/localtime:/etc/localtime -v $(pwd):/workdir --workdir=/workdir --name tensorrt-v8.x ultralytics/yolov5:v7.0
相关实现
相关阅读
Pytorch2ONNX
ONNX2TensorRT
ONNX/ONNXRuntime