YOLACT: Real-time Instance Segmentation

论文: YOLACT: Real-time Instance Segmentation
GITHUB: dbolya/yolact
摘要
We present a simple, fully-convolutional model for real-time instance segmentation that achieves 29.8 mAP on MS COCO at 33.5 fps evaluated on a single Titan Xp, which is significantly faster than any previous competitive approach. Moreover, we obtain this result after training on only one GPU. We accomplish this by breaking instance segmentation into two parallel subtasks: (1) generating a set of prototype masks and (2) predicting per-instance mask coefficients. Then we produce instance masks by linearly combining the prototypes with the mask coefficients. We find that because this process doesn’t depend on repooling, this approach produces very high-quality masks and exhibits temporal stability for free. Furthermore, we analyze the emergent behavior of our prototypes and show they learn to localize instances on their own in a translation variant manner, despite being fully-convolutional. Finally, we also propose Fast NMS, a drop-in 12 ms faster replacement for standard NMS that only has a marginal performance penalty.
我们提出了一种简单的、全卷积的实时实例分割模型,在单个Titan Xp上以33.5 fps的速度在MS COCO上实现了29.8 mAP,这比其他的方法都快得多。注意:我们只需要单个GPU就可以训练得到这个结果。我们通过将实例分割分解为两个并行的子任务来实现这一点:(1)生成一组原型掩码;(2)预测每个实例的掩码系数。然后,我们通过将原型掩码与掩码系数线性组合来生成实例掩码。由于这一过程不依赖于repooling,我们发现这种方法可以产生高质量的掩码并表现出时间稳定性。此外,我们分析了掩码的涌现行为(the emergent behavior),尽管分割分支是全卷积网络,它们还是能够对不同位置的实例目标有敏感性。最后,我们还提出了Fast NMS,它比标准NMS快12毫秒,而且性能损失很小。
引言
之前的实例分割模型大多借鉴了两阶段目标检测模型的设计,例如 Mask R-CNN 借鉴了 Faster R-CNN。这类模型首先生成候选框(Region Proposals),然后通过额外的特征定位步骤,将候选框内的特征进行repooling(使用 RoI Pooling 或 RoI Align 层),最终输入到掩码预测器生成掩码。这种架构本质上是顺序的,难以通过借鉴单阶段目标检测模型来进一步加速推理过程。
论文提出的 YOLACT (You Only Look At Coefficients) 实现了一个全新的单阶段实例分割框架,将实例分割任务分解为两个并行的子任务:
- 任务一:在整个图像上生成非局部原型掩码字典。
- 任务二:逐个实例预测一组掩码系数。
最终,将原型掩码与每个实例的掩码系数进行线性组合(即乘法运算),就能够生成完整全图的实例分割掩码。这种实现方式具有以下优点:
- 高效性:由于并行架构的设置以及极度轻量化的集成步骤(assembly process),YOLACT 在目标检测模型的基础上仅增加了非常有限的资源消耗,能够轻松实现 30 FPS 的实时运行速度。
- 高质量掩码:由于掩码使用了整个图像空间的完整内容进行生成,因此不需要经过repooling带来的质量损失,对于大目标的掩码质量显著优于其他两阶段实例分割模型。
- 通用性:论文提出的实例分割框架是通用的,可以扩展到几乎任何目标检测模型(包括单阶段或两阶段目标检测模型)。
通过这些创新,YOLACT 不仅提高了实例分割的速度和效率,还保持了高质量的分割结果。
YOLACT
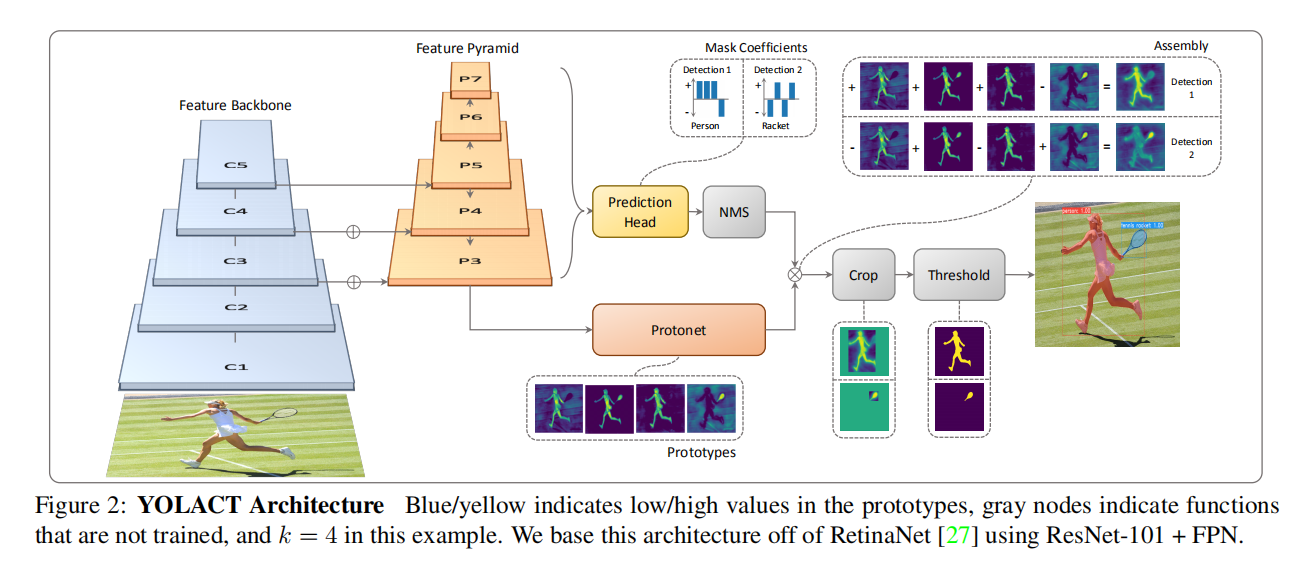
YOLACT在单阶段目标检测架构的基础上,引入了一个额外的掩码分支,使得模型能够并行地处理两个任务:目标检测和实例分割。
- 在掩码分支中,采用全卷积网络(FCN)生成一组与图像尺寸相同的原型掩码。这些原型掩码的生成过程不依赖于特定的实例;
- 在目标检测分支中,添加了一个掩码系数预测HEAD,为每个检测到的实例预测一组对应的掩码系数。
对于经过非极大值抑制(NMS)筛选后的预测框,可以将相应的目标掩码系数与原型掩码进行线性组合,从而获得该实例的最终分割掩码。这一过程与Mask R-CNN不同,后者需要一个额外的特征定位步骤(feature localization step)来处理实例掩码。
论文强调了掩码的空间相关性(spatially coherent),即相邻像素倾向于属于同一个实例。卷积层的输出能够保持这种空间相关性,而全连接层则会破坏这种特性。传统上,两阶段实例分割模型通过特征定位模块(包含卷积或池化操作)来维持掩码的空间结构。相比之下,YOLACT对单阶段检测器进行了创新性的改进,它并行计算原型掩码和掩码系数,并在最后引入一个集成步骤(the assembly step)以生成每个实例的分割掩码。
作者做过实验,直接使用全连接层输出的向量变形为掩码的效果不如通过卷积层生成的原型掩码。这进一步证明了保留空间相关性对于实例分割任务的重要性。
原型掩码
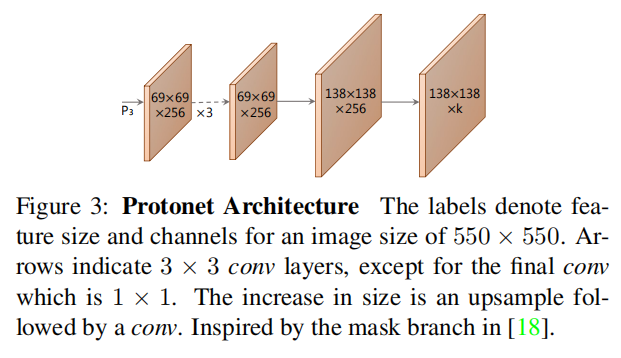
论文为掩码分支设计了一个全卷积网络(称为Protonet),该网络通过多层卷积运算和上采样操作,最终输出包含k个原型掩码的特征图。这种设计借鉴了标准语义分割网络的结构,但有一个关键区别:Protonet本身并不直接计算损失。相反,它生成的原型掩码与目标检测分支预测的掩码系数结合后,才共同用于计算实例掩码预测与真实值之间的损失。
在构建Protonet的过程中,作者观察到两个重要的设计选项:
- 特征层次的选择:通过实验发现,使用Backbone网络更深层的特征作为Protonet的输入,可以生成更为鲁棒的实例掩码。这表明较深的特征层包含了更多具有判别力的信息,有助于提高掩码的质量。
- 原型掩码分辨率的影响:研究还显示,生成较高分辨率的原型掩码不仅能提升实例掩码的整体质量,还能显著改善对小目标的分割效果。高分辨率的掩码能够捕捉到更精细的边界信息,这对于准确地分离较小或形状复杂的物体至关重要。
基于上述观察,最终的Protonet采用了FPN(Feature Pyramid Network)中的P3层特征作为输入,以确保获得足够的空间细节,同时对输出的原型掩码应用了ReLU非线性激活函数。这一选择不仅使得原型更加易于解释,而且有助于模型学习到更具区分度的掩码表示,从而进一步提升了实例分割的性能。
掩码系数
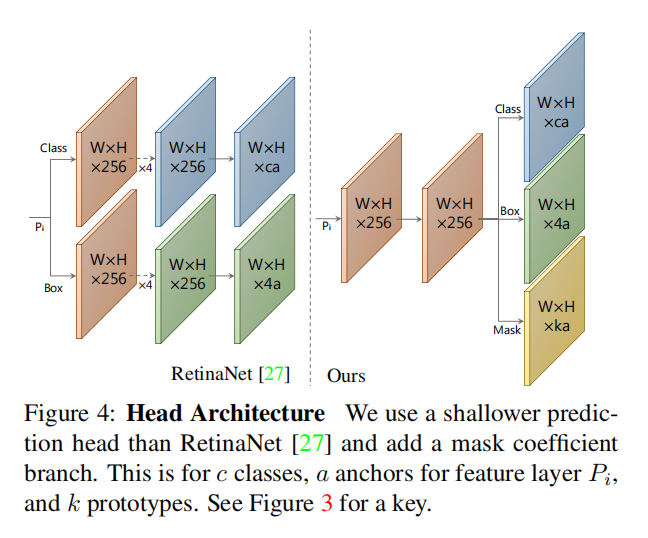
在YOLACT的目标检测分支中,除了传统的类别概率和预测框的预测外,还额外增加了对k个掩码系数的预测。所以每个锚点最终会输出4 + c + k个系数,其中4是用于定义边界框的坐标参数,c表示类别的数量,k表示与原型掩码对应的掩码系数。
论文还提出为了提高模型的鲁棒性和稳定性,对全连接(FC)层输出的k个掩码系数应用tanh激活函数。tanh函数能够将掩码系数的取值限制在[-1, 1]之间,这不仅有助于稳定训练过程,还能使得生成的掩码系数更加可靠。通过引入这种非线性变换,模型能够在不同的实例之间更清晰地区分,并且对于不同大小和形状的目标具有更好的鲁棒性。
掩码集成
表示sigmoid函数,取值在 (0, 1)之间。表示原型掩码,大小为 ; 表示掩码系数,大小为 ;
损失函数
论文一共设计了3个损失:分类损失
Cropping Masks
- 评估阶段: 在评估模型性能时,YOLACT使用预测的边界框来裁剪集成后的实例掩码。这样可以将每个实例的掩码限制在其相应的边界框内,然后与真实掩码进行比较。
- 训练阶段: 计算
时会将损失值除以相应真值框的面积,这样做可以提高模型对各种尺寸目标的泛化能力。
其他创新
除了掩码分支和目标检测分支的并行计算,以及额外增加的掩码集成步骤,论文还进行了一系列创新和改造,包括不限于目标检测模型的选择和改造,后处理NMS的优化以及训练过程中损失函数的优化。只是这些技术在后续发展中逐渐被却取代或者简化,所以本文不再详细描述。
- 对于Backbone Detector,论文基于RetinaNet进行改造;
- 论文使用ResNet-101 + FPN的变种作为默认的特征提取器;
- 后续出现的目标检测模型和实例分割模型,倾向于采用更轻量化且高效的架构;
- 对于NMS,论文实现了Fast NMS进行批量加速;
- 随着GPU的发展以及NMS变种的改进,不再依赖Fast NMS这样额外的优化手段。
- 对于训练,论文增加了语义分割损失来强化掩码的预测;
- 在yolov5-seg网络的训练中,不再增加语义分割损失进行增强训练。
实验
掩码结果
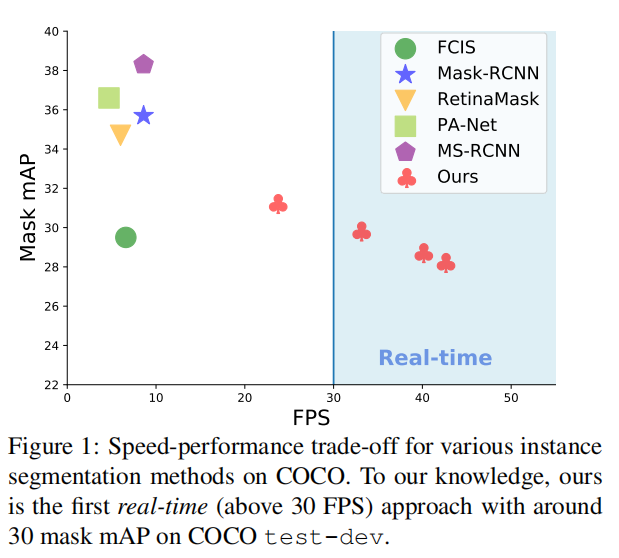
YOLACT 论文在MS COCO test-dev数据集上对模型的实例分割性能进行评估,并与当时其他最先进的SOTA实例分割算法进行了比较。论文在单个NVIDIA Titan Xp GPU上测试了所有模型的推理速度。
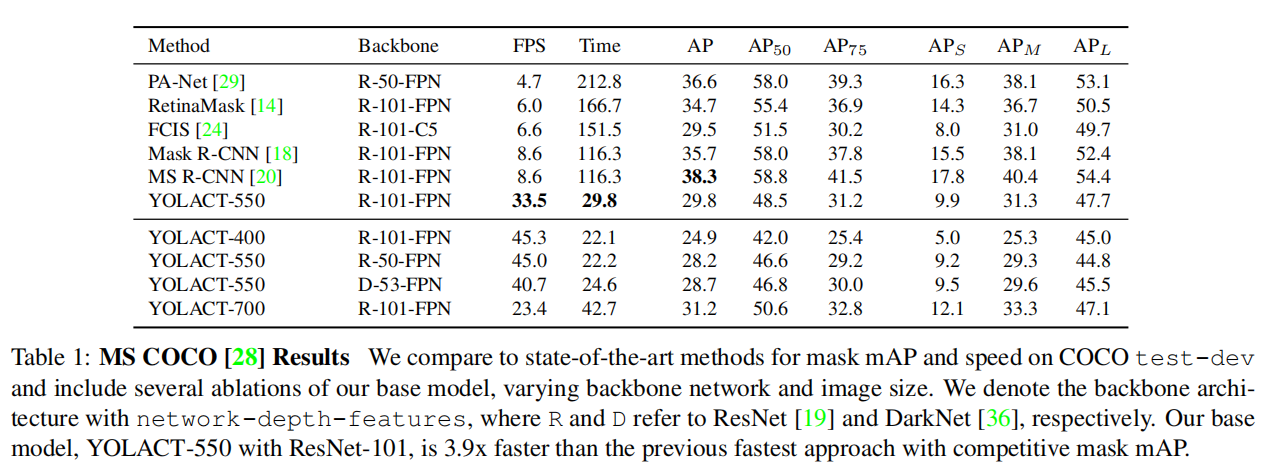
掩码质量
在MS COCO test-dev数据集上,YOLACT 和 Mask R-CNN 的性能差异随着IoU阈值的提高而发生变化。在mAP_50条件下,YOLACT 与 Mask R-CNN 的差距为9.5 AP;而在更严格的mAP_75条件下,这一差距缩小至6.6 AP。尤其值得注意的是,在95% IoU阈值下,YOLACT 达到了1.6 AP,而 Mask R-CNN 仅为1.3 AP。这表明,随着分割标准变得更加严格,YOLACT 展现出更好的掩码质量,能够在高精度要求的任务中提供更为准确的实例分割结果。这种现象反映了YOLACT 在生成高质量掩码方面的优势,尤其是在处理复杂形状和细节时的表现更为突出。

分析
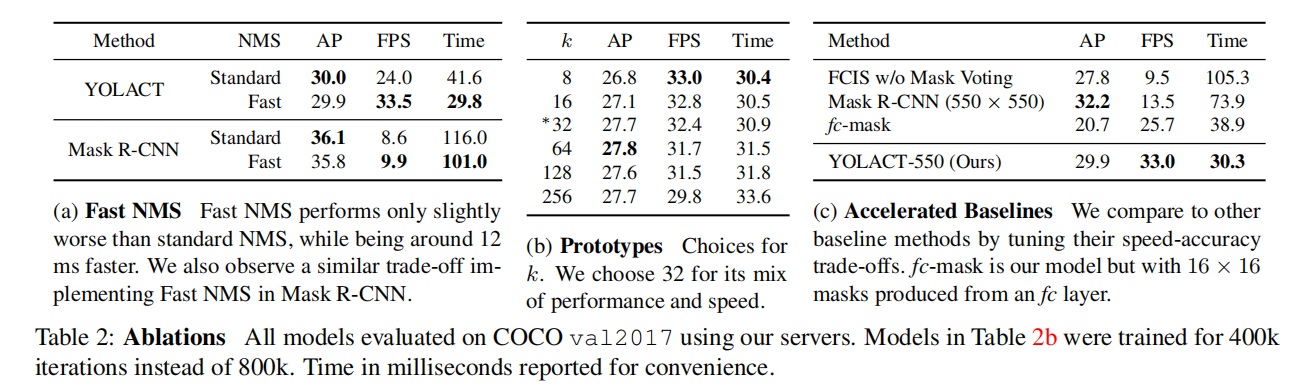
YOLACT 是首个能够达到30 FPS的实时实例分割算法,虽然显著提升了推理速度,但是其性能相较于其他最先进的SOTA算法仍旧存在一定差距。论文分析了由于掩码生成算法导致的某些错误,具体表现为以下两种情况:
- 定位失败(Localization Failure):
- 描述:当图像中存在多个目标时,YOLACT 可能在各实例的掩码中无法准确定位目标。
- 影响:这会导致生成的掩码不准确,特别是在密集场景或多目标环境中,模型难以区分不同实例的边界。
- 泄漏(Leakage):
- 描述:YOLACT 使用预测框来裁剪实例掩码,因此网络没有学会抑制裁剪区域外的噪声。
- 影响:当预测框不准确的时候,可能导致掩码包含不必要的背景信息或相邻目标的部分内容,从而降低分割精度。
这些局限性反映了YOLACT在处理复杂场景时的挑战,尤其是在需要高精度分割的应用中。尽管如此,YOLACT通过并行计算掩码分支和检测分支实现了显著的速度优势,适合对实时性要求较高的应用场景。未来的工作可能会集中在改进这些方面,以进一步提升模型的准确性和鲁棒性。

YOLACT 和 Mask R-CNN 在 COCO 测试集上的性能差异主要源于目标检测器的表现,而非掩码生成算法。具体来说,两者在 mask mAP 和 box mAP 上的差距都非常接近(YOLACT 为29.8 vs 32.3,Mask R-CNN 为35.7 vs 38.2),表明掩码生成的质量相当。因此,6 mAP 的整体性能差距主要是由于目标检测器的错分类( misclassification)和预测框未对齐(box misalignment)导致的,这突显了改进检测精度和框对齐能力的重要性。
小结
YOLACT是首个在MS COCO 2017 test-dev数据集上达到30 mAP,同时帧率超过30 FPS的实时实例分割算法。其最重要的创新在于并行计算原型掩码和目标检测分支,然后逐实例集成原型掩码和掩码系数生成最终的实例掩码。论文通过实验表明,提升目标检测器的能力是实例分割性能提升的关键因素,后续的研究也证实了替换更强的目标检测器可以显著提高YOLACT的实时实例分割性能。
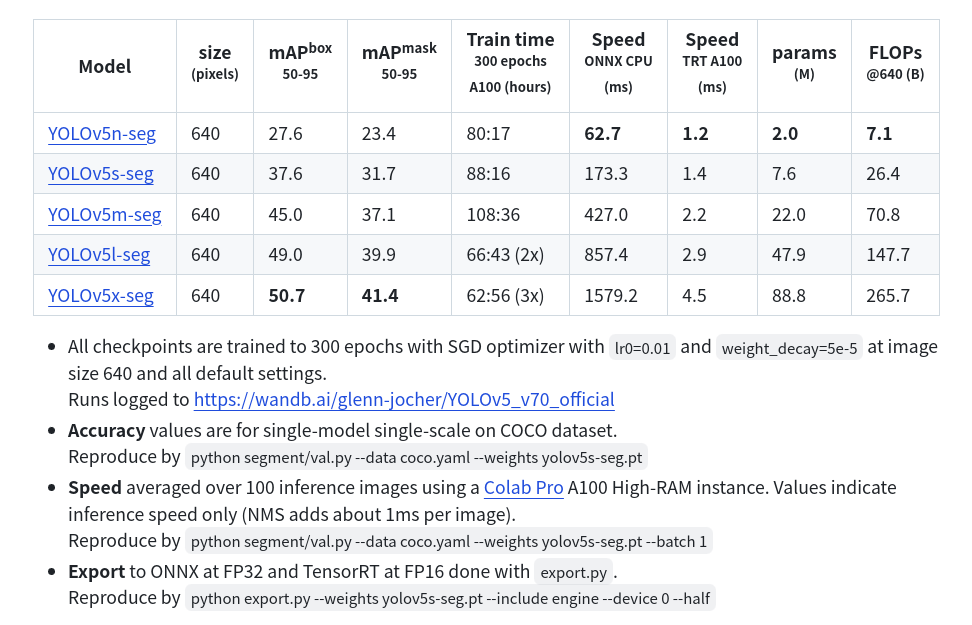
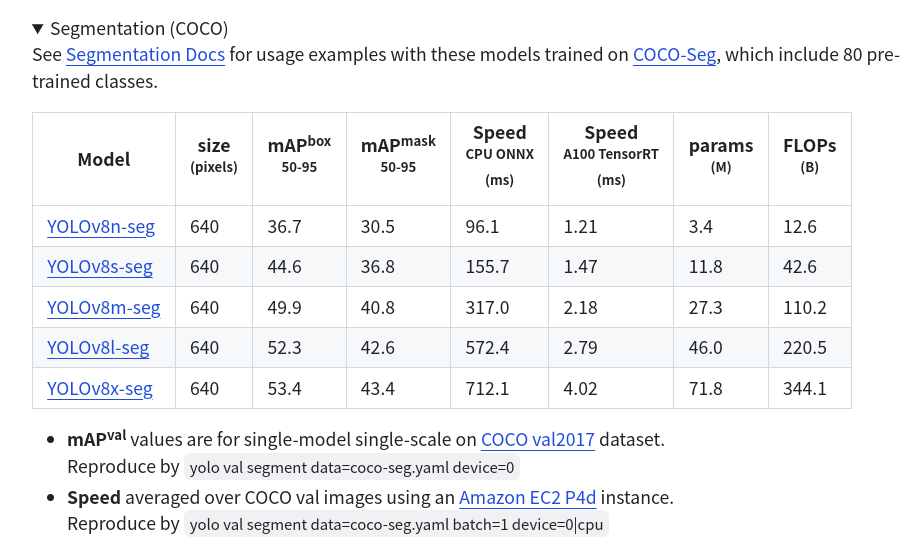
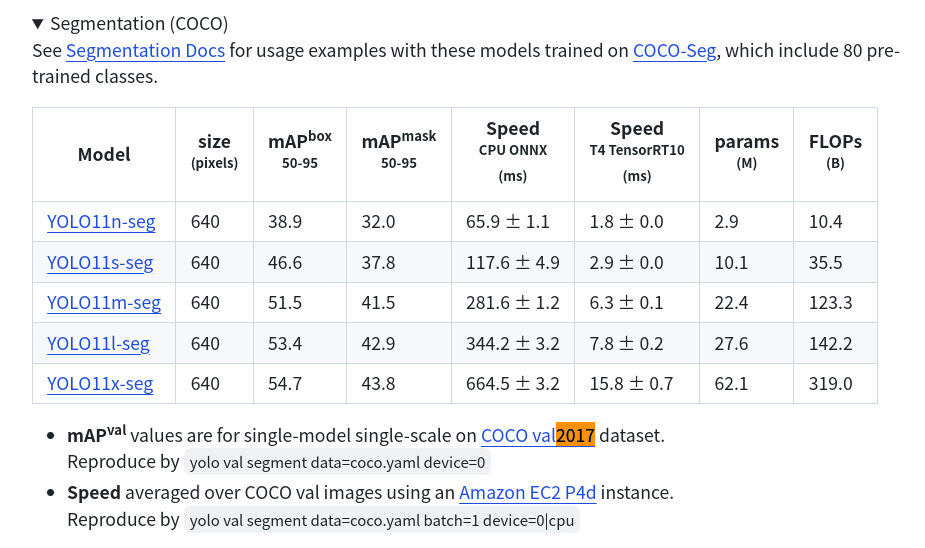
YOLOv5-seg是2022年提出的实时实例分割算法,借鉴了YOLACT的设计思想,在YOLOv5目标检测算法的基础上增加了原型掩码分支,并通过并行计算的方式实现了高效的实时实例分割能力。该算法在MS COCO 2017 val数据集上达到了当时的SOTA性能。2023年发布的YOLOv8-seg和2024年发布的YOLO11-seg继续沿用了这一设计理念,进一步优化了实时实例分割的性能。