A Benchmark on Tricks for Large-scale Image Retrieval
原文地址:A Benchmark on Tricks for Large-scale Image Retrieval
摘要
Many studies have been performed on metric learning, which has become a key ingredient in top-performing methods of instance-level image retrieval. Meanwhile, less attention has been paid to pre-processing and post-processing tricks that can significantly boost performance. Furthermore, we found that most previous studies used small scale datasets to simplify processing. Because the behavior of a feature representation in a deep learning model depends on both domain and data, it is important to understand how model behave in large-scale environments when a proper combination of retrieval tricks is used. In this paper, we extensively analyze the effect of well-known pre-processing, post-processing tricks, and their combination for large-scale image retrieval. We found that proper use of these tricks can significantly improve model performance without necessitating complex architecture or introducing loss, as confirmed by achieving a competitive result on the Google Landmark Retrieval Challenge 2019.
度量学习进行了许多研究,它已经成为实现高性能的实例级别图像检索方法的关键因素。与此同时,人们对于能够显著提升性能的前处理和后处理技巧反而关注较少。此外,我们还发现大多数之前的研究使用了小规模数据集来简化处理。因为深度学习模型中特征表示的性能同时取决于领域知识和大数据,所以为了能够合理的组合不同的检索技巧,理解模型在大规模环境中的行为是很重要的。在本文中,我们广泛分析了许多已知的前处理和后处理技巧,以及它们的组合对于大规模图像检索的影响。我们发现在不引入复杂架构或者损失之前,正确的使用这些技巧就可以显著的提高模型性能。论文在2019年谷歌地标检索挑战赛上取得了有竞争力的结果。
引言
论文发现之前的研究存在一种讨论,就是在小规模数据集(比如Oxford5k或者Paris6k)上使用精心设计的损失函数或者模型架构进行评估。因为这些数据集基于理想的条件进行了构建,所以得到的算法不能够保证拥有足够的泛化能力。而相对大的数据集(比如Oxford105k或者Paris106k)也存在另一种套路,就是检索数据集和查询数据集足够小,额外加入了大量无关的图像作为干扰集。论文还发现了大量的有助于提升算法性能的前处理和后处理算法,这些技巧并没有被很好的总结而导致没有产生最佳组合。
本文的目标在于组合不同的前处理和后处理技巧,分析它们在大规模数据集下的检索性能。如下图1所示:
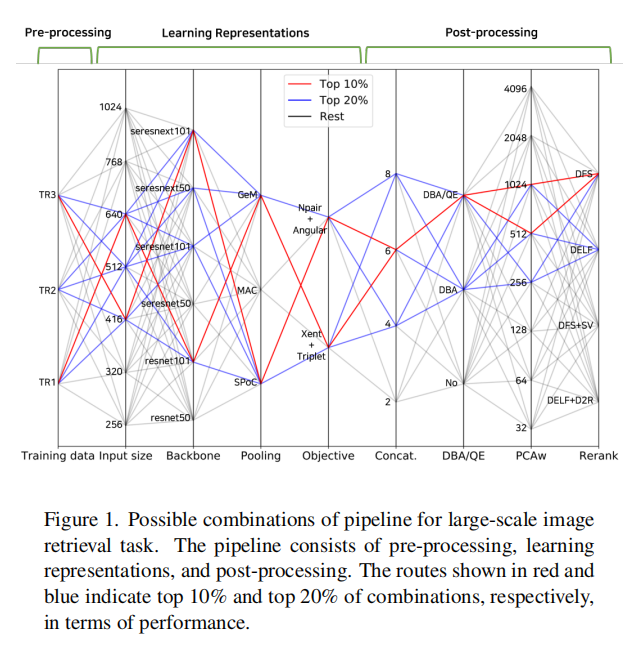
论文主要贡献分为两方面:
- 分析了众多前处理和后处理技巧的影响,以及在大规模图像检索数据集上详细探索了它们之间的组合;
- 通过正确的组合不同的技巧,论文得到了非常有竞争力的结果。在
Google地标检索挑战2019上获得了第8名。
前处理技巧
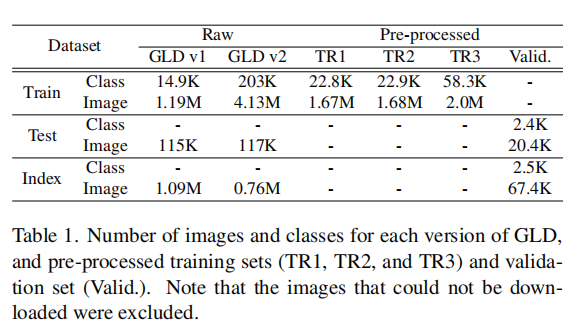
论文使用GLD v1(Google landmark dataset 2018)和GDL v2(Google landmark dataset 2019)作为实验的两个大规模检索数据集,它们详细的数据见下表1所示:
针对这些大规模数据集的处理,论文抛出两个问题:
- 数据集越大,存在越多的噪声数据。如何消除这些噪声来提升训练数据的质量,从而提高模型性能?
- 如何能够在大规模数据集上尽可能快速的进行实验?
因为GLD数据集拥有超过70万张检索数据以及超过10万张查询数据,所以论文首先描述了如何通过移除噪声图像和构建小规模验证集来规避这些问题。
训练数据清洗
清洗数据集的目标在于最大化类间方差(maximize inter-class)同时最小化类内方差(minimize intra-class)。论文通过聚类算法(the density-based spatial clustering of applications with noise (DBSCAN))来清洗训练数据,最终获得三个数据集(TR1/TR2/TR3)。详细说明如下:
TR1. 首先利用GLD v1作为训练数据得到一个模型,提取测试集和检索集的特征后使用DBSCAN进行聚类清洗,每个聚类作为一个新的类别加入到训练集,最终得到TR1数据集。
TR2. 在GLD v2的检索集中包含了许多干扰图像,这些图像并不是地标数据,而是诸如文档、肖像和自然景观等场景。论文使用了相同的清洗流程(使用GLD v1训练的模型提升GLD v2检索集的特征,然后进行聚类),然后挑选其中的聚类作为新的类别,加入到TR1得到TR2数据集。
TR3. GLD v1训练集的规模比GLD v1大的多,其中包含了更多的噪声类别和图像。论文首先使用Open Image Dataset和the iNaturalists Dataset训练一个二值分类器,移除GLD v2训练集中的自然景观图像。然后,对每个类别进行聚类,当单个类别数据聚类得到多个类别时,选择其中最大的一个聚类并舍弃其他数据。另外,移除GLD v2训练集出现的TR2图像数据,最后得到的成为TR3。
小规模数据验证
论文还是构建一个足够小的验证数据集,已允许足够快速的性能验证。从GLD v2训练数据集中采样2%的数据,然后划分为测试集和检索集,另外,选取噪声聚类作为一个新的类别加入,因为GLD v2的测试集和检索集也包含了非常多的干扰图像。
试验结果

上图展示了清洗前后的数据结果。第一行展示了同一个标签下不同数据的结果,可以发现存在同一个建筑的室内、室外甚至局部的图像。这些数据导致了极大的类内变化,有可能会干扰模型的学习,特别是逐对排序损失(pair-wise ranking loss)的学习。另外,自然场景图像也会干扰模型训练,因为它们之间存在非常小的类间差异。经过聚类清洗后,保留同一个类别中最大的聚类,移除其余干扰数据,能够得到更清晰的数据集,如第二行所示。
论文使用N-pair + Angular双重损失,训练了不同的数据集。训练大小为1024维度特征向量进行推理。结果如下表二所示
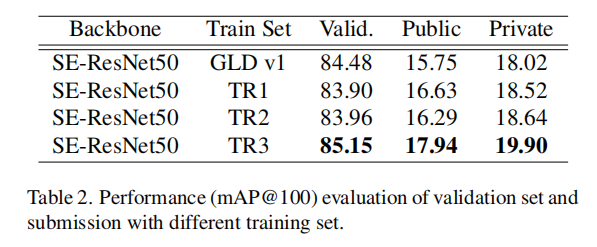
- 比较
GLD v1和TR1,可以发现来自于测试集和检索集的聚类类别有助于提高模型性能; - 比如
TR1和TR2,可以发现两者训练的模型性能差别不大。论文分析是因为它们之间的数据和类别数量差异不大; - 论文还训练了
GLD v2数据集,但是由于训练数据的噪声太大导致无法从原始数据中训练得到合适的模型; - 使用清洗
GLD v2的训练数据集生成的TR3,论文得到了最好的基准性能。
训练
在训练环节,论文专注于探索合适的池化函数和损失函数的组合。
池化函数
论文比较了三种池化函数:SPoC、MAC以及GeM。
目标函数
对于检索任务而言,通常会结合分类任务一起进行训练。论文尝试了两种组合:
Xent + Triplet. 论文组合了交叉熵损失(Cross-Entropy Loss)以及三元组损失(Triplet Loss)进行训练,其中三元组对来自于同一批次数据的hard example mining。
N-pair + Angular. 论文尝试了逐对排序损失:N-pair和Angular。因为Angular损失可以集成到N-pair损失函数中,所以在训练中能够结合基于距离的损失和以及角度的损失进行优化。
单模型训练
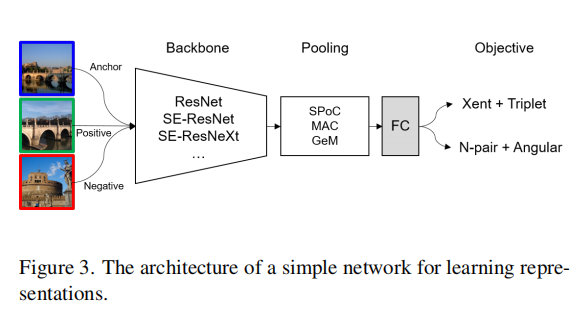
训练结构如上图3所示。使用ResNet、SE-ResNet以及SE-ResNext作为基准模型;在池化操作之后,连接全连接层和L2归一化层得到最终的特征图。上述架构可以产生backbone(6) × pooling(3) ×objective(2) = 36种组合。
实验结果
- 对于
N-pair + Angular损失函数组合,使用256 x 256作为训练阶段输入,使用416 x 416作为推理阶段输入; - 对于
Xent + Triplet损失函数组合,使用320 x 320作为训练阶段输入,使用640 x 640作为推理阶段输入; - 输入向量的维度统一为
1024。
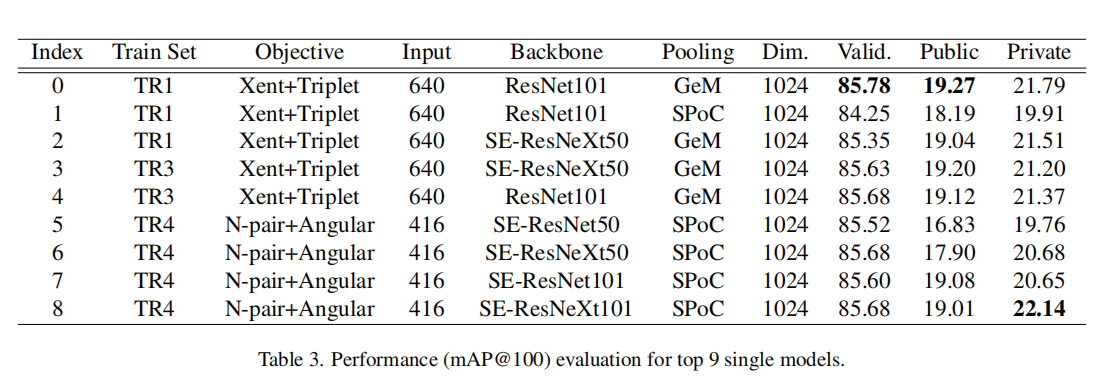
性能最好的前9个模型性能如上表3所示。
池化. 不论哪一种组合,MAC的性能最差。最好的池化方法依赖于目标函数,SPoC对于N-pair + Angular性能最好,GeM对于Xent + Triplet性能最好。
目标函数. Xent+Triplet组合对于TR1的性能最好,论文分析是因为Xent损失函数对于数据质量非常敏感,而TR3包含了少部分重复类别。
输入大小. 论文变化了不同的输入大小,如下图4(a)所示。更大的输入能够得到更大的特征图,包含更丰富的信息,从而获得更好的性能。另外,当输入大小达到某一个点的时候,性能会出现下降。
后处理技巧
论文详细研究了以下后处理技巧:
- 特征集成(
feature ensemble) - 数据库增强(
database augmentation (DBA)) - 查询扩展(
query expansion (QE)) - 重排序(
reranking)
多个特征集成
特征集成只是多个特征的简单连接,但是在对于视觉任务而言非常有效。论文想要探索其中一个关键问题:哪些特征的组合是最好的?(what features would be the best to be combined?)。
基于上一节采用不同主干网络、不同池化方法以及不同的目标函数训练得到的单模型,最终得到1024维度特征向量。论文尝试了不同的组合方式:
- 随机选择一组特征进行连接;
- 变化组合的特征数量;
- 仅使用最好的单个特征向量。
实验结果在后续章节会有展示。
DBA和QE
DBA. 数据端增强策略实现如下:对于每条特征,从数据库中采集和它最相近的前topK条特征向量(k-NN),进行加权求和得到增强的特征向量,参与实际图像检索工作。其目的在于通过对最近邻的特征点进行平均来获得更具鲁棒性和更具判别力的图像表示。其权重向量计算如下:
其中
QE. 查询扩展也是常用的增强特征鲁棒性和判别力的有效方式。对于每个查询图像,从特征库中检索得到topK个最近邻特征向量(k-NN);将查询特征和检索得到的前topK个特征重新组合得到二次查询特征向量。这一过程可以重复多次,最终得到的组合特征对特征库重新进行检索,得到最终的检索图像列表。同样的,可以使用权重向量
PCA白化
白化描述符也是常用的后处理方法,通常会在一个单独的数据集中,使用训练后模型提取特征向量,通过PCA(principal component analysis,主成分分析)方式进行无监督学习。论文在实验过程中针对DBA和QE得到的4096维度特征向量进行PCA白化(1024维度特征向量。最后,再次应用L2归一化。
重排序
重排序指的是针对初始排序阶段获取的前topK个候选列表,再次进行排序操作。这一操作基于假设前提,就是真值图像出现在topK个候选列表中。论文尝试了两个不同的重排序方法:
- 基于全局描述符的图搜索(
graph search based on the global descriptor); - 基于局部描述符的局部匹配(
local matching based on the local descriptor)。
Graph search. 论文使用了Diffusion(DFS)算法,它是一种捕获特征空间中图像流形的机制。通过离线构建数据集的邻域图,它能够高效的搜索流形。这种方法改善了对小目标和杂乱场景的检索,尤其适合GLD的数据集领域。
Local matching. 论文也尝试了通过图像的空间信息进行重新排序。给定两幅图像,使用RANSAC提取对应匹配信息,统计相关点(inliers)的数量。对于大规模数据集而言,对所有可能的查询和检索图像执行几何校验的成本非常昂贵的,论文仅针对全局描述符检索得到的前DELF(预训练),然后对每张图像提取1K维度局部特征。论文也发现了不相关图像之间也有可能存在高匹配成绩,所以设置了过滤阈值,当候选图像的检索相似度超过
实验结果
多特征集成
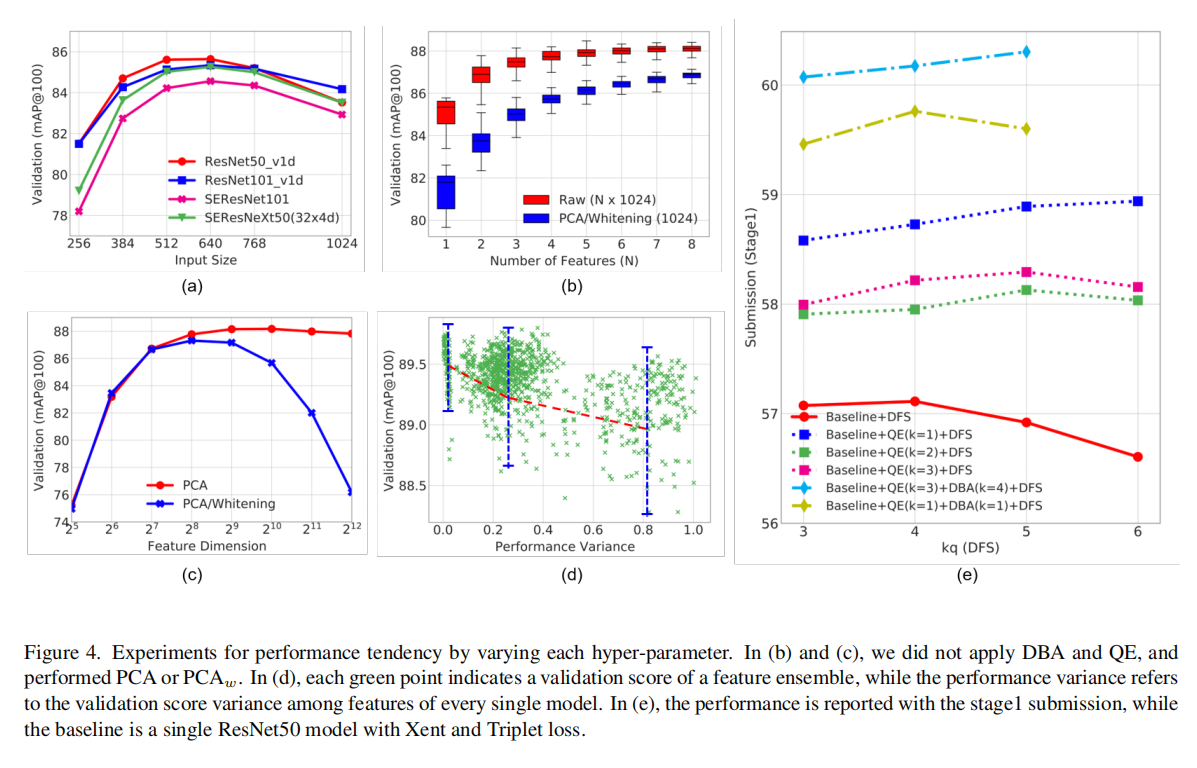
从上图4(a)可以发现,当特征集成数量增加时,性能普遍增强,不过增加的性能增益有限。基于计算损耗以及性能增益的考虑,论文推荐采用4~6条特征的集成。
论文还测试了best one策略的有效性,实验结果如图4(b)所示。没有理解best one的概念:难道指的是随机采样的特征组合中最好的那一条组合?还是通过白化方式将多条连接在一起的特征缩减到一条特征大小?
DBA/QE和PCA-Whitening
论文尝试了两种方式:
- 针对连接的特征执行
PCA创建全局描述符,后续再分别执行DBA和QE; - 先针对每条特征执行
DBA和QE操作,然后再执行PCA。
实验结果如下表4所示,可以发现第二种方式的性能更好。
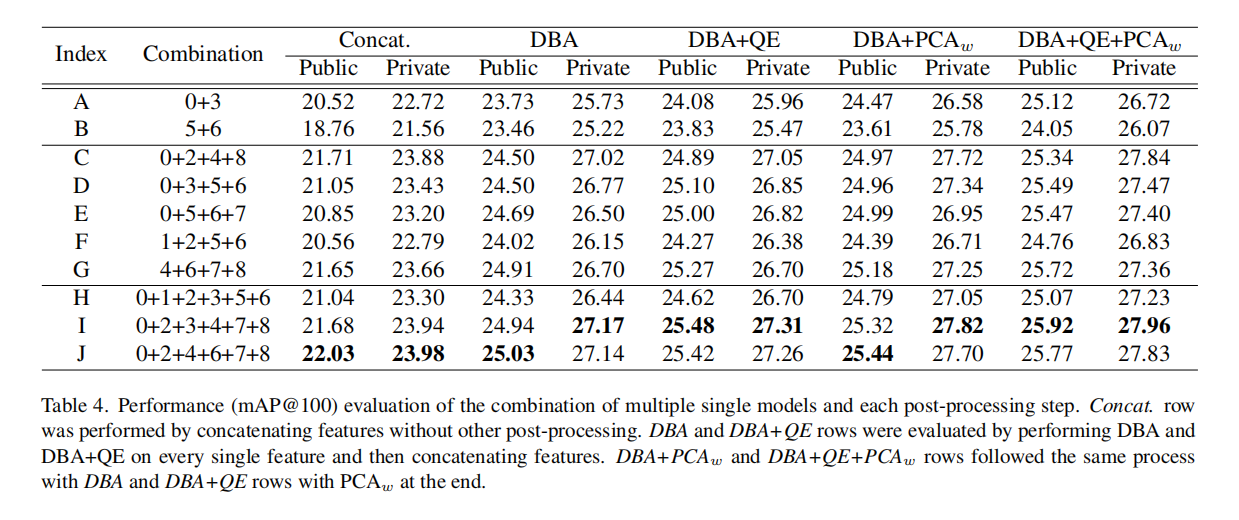
论文发现是否先针对特征执行DBA和QE操作,影响其他后处理方法的性能。上表4展示了在DBA和QE之后应用PCA和白化操作一致性增强了性能,而上图4(b)展示了仅执行PCA白化操作一致性退化了性能。另外,论文还发现了在DBA和QE之后应用PCA白化操作,1024维度的输出向量是最优的,而仅执行PCA白化操作的话,性能会得到退化,如上图4(c)所示。
从上述实验可以发现,DBA和QE不仅仅提高了特征的表征能力,还保持了维度衰减的鲁棒性。可以DBA和QE操作,论文在实验中发现
重排序
论文参考D2R(detect-to-retrieve, 结合检测方法进行检索)实现,使用地标检测器检测和裁剪感兴趣区域,然后使用DELF提取局部特征。其实验结果如下表5所示
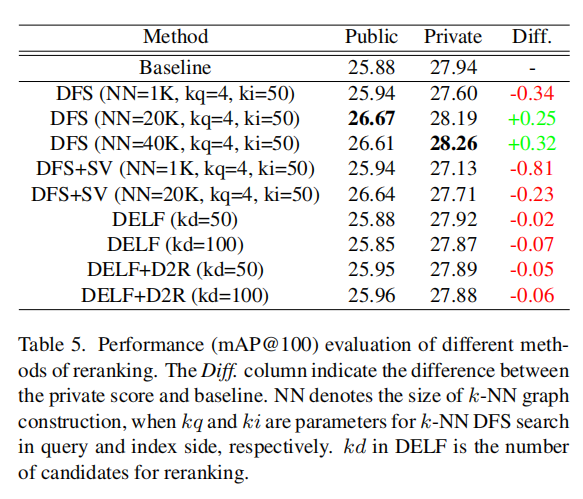
从检索结果来看DELF+D2R的局部匹配方式并不能有效的提升大规模数据集GLD。论文还尝试了DFS算法进行重排序,如上图4(e)所示。具体实现就不描述了,后续学习到再说。
Google Landmark Retrieval Challenge
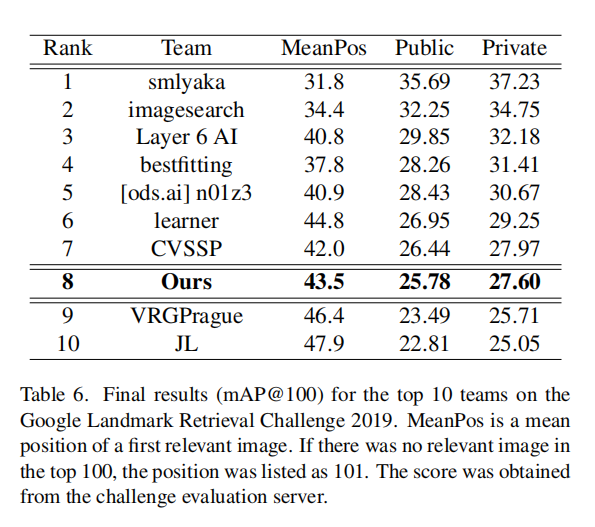
上表6是论文在GLD 2019的最终竞赛结果。论文选择了上表4中的特征组合DBA和QE(超参数1024大小;最后,使用DFS+SV(NN=20K)重排序前top100个候选列表。另外,从上表5的结果可以发现论文最终实现的结果进一步得到了提升。
小结
又是一篇工程性能爆满的实践性质论文,详细描述了
- 前处理阶段:聚类清洗噪声数据以及创建合适的验证数据集;
- 训练阶段:采用不同的基准模型、池化方法以及损失函数;
- 后处理阶段:组合
特征集成/DBA/QE/PCA白化以及重排序算法。
从论文的实验过程中可以发现:
- 对于数据而言
- 更大规模的数据以及类别能够提升性能(比如
TR3相对于TR1/TR2,如上表2所示); - 通过清洗数据来尽可能的减少类内变化同时增大类间差异能够提升性能(比如通过聚类清洗同一类的噪声数据);
- 适当增加噪声数据来模拟实际环境能够提高模型泛化性能(比如通过聚类算法来提取某几个自然场景类别加入到地标训练集)。
- 更大规模的数据以及类别能够提升性能(比如
- 对于训练而言
- 结合分类任务和检索任务是一种常用的训练手段,尤其对于检索任务而言。
- 对于后处理而言
- 特征集成是一种有效的性能提升方法;
DBA和QE能够增强特征表征能力,同时提高特征鲁棒性(在维度衰减前后);PCA白化需要结合DBA和QE(在它们之后执行)才能提升性能;- 重排序实现需要更多的尝试和探索。
在论文中也隐约提到了后续发展的方向:
- 结合检测算法来增强检索性能;
- 采用更强大的损失函数来提升性能;
- 探索更有效的重排序算法(论文提供的实现我觉得还是太复杂了)。
论文并没有提供具体实现,所以需要逐步的进行算法实现和调试,才能进一步提升实际落地的检索任务性能。