Particular object retrieval with integral max-pooling of CNN activations
原文地址:Particular object retrieval with integral max-pooling of CNN activations
摘要
Recently, image representation built upon Convolutional Neural Network (CNN) has been shown to provide effective descriptors for image search, outperforming pre-CNN features as short-vector representations. Yet such models are not compatible with geometry-aware re-ranking methods and still outperformed, on some particular object retrieval benchmarks, by traditional image search systems relying on precise descriptor matching, geometric re-ranking, or query expansion. This work revisits both retrieval stages, namely initial search and re-ranking, by employing the same primitive information derived from the CNN. We build compact feature vectors that encode several image regions without the need to feed multiple inputs to the network. Furthermore, we extend integral images to handle max-pooling on convolutional layer activations, allowing us to efficiently localize matching objects. The resulting bounding box is finally used for image re-ranking. As a result, this paper significantly improves existing CNN-based recognition pipeline: We report for the first time results competing with traditional methods on the challenging Oxford5k and Paris6k datasets.
最近,基于卷积神经网络(CNN)的图像表示被证明能够为图像搜索提供有效的描述符,优于CNN之前的短向量表示。然而,这种模式与几何感知重排序方法不兼容,在某些特定的目标检索基准上,依赖于精确描述符匹配、几何重排序或者查询扩展的传统图像搜索系统仍旧优于CNN特征表示。论文通过使用来自CNN的相同原始信息,重新审视了两个检索阶段,即初始搜索和重排序。通过对多个图像区域进行编码,我们构建了紧凑的特征向量,而且不需要向网络提供多个输入。此外,我们还扩展了积分图像来处理卷积层激活之后的最大池化操作,使我们能够有效地定位匹配目标,生成的边界框最终用于图像重排序。本文显著改进了现有的基于CNN的识别流程:我们首次报告了在具有挑战性的Oxford5k和Paris6k数据集上可以与传统方法竞争的检索结果。
引言
传统的图像搜索算法采集局部不变特征后,还需要经过过滤(filtering)和重排序(re-ranking)阶段。在过滤阶段将数据库图像按照相似度进行排序,在重排序阶段对排名前N位的数据库图像再次进行排序。在过滤阶段和重排序阶段结合几何信息(geometric information)或者智能码本(smart codebooks),能够进一步提升性能。
论文基于CNN特征对过滤和重排序阶段进行优化,包括以下三方面:
- 从卷积层激活中提取出一个紧凑的图像表示,它编码了多个图像区域并且不需要向网络多次输入数据进行计算,实现上类似于
Fast-RCNN/Faster-RCNN; - 扩展了广义平均算法(一篇
2009年的论文),通过积分图计算最大池化操作,这种方式可以直接在2D特征图上进行目标定位(如下图一所示); - 在图像重排序阶段应用定位算法,实现了一个简单但是高效的查询扩展方法。

背景
假定输入图像ReLU作为最后一个卷积层输出,保证所有元素均为非负值。
论文将3D张量输出看成一组2D特征图输出:MAC(maximum activations of convolutions):
论文利用MAC来计算两张图像之间的余弦相似度,另外,在计算相似度之前还需要减去输入图像的平均像素值。和全连接层输出不同,MAC的计算并没有编码激活在特征图上的位置,另外它编码了每个滤波器最大的局部响应,因此具有平移不变性(translation invariant)。下图2展示了两幅图像中最相近的子区域,

区域编码
论文提出一种新的卷积特征提取方案:首先提取多个图像子区域,分别提取特征向量并进行后处理,之后求和得到单个特征向量,进行R-MAC。
区域特征向量
在上一节描述了基于全局卷积层输出的特征向量
其中
R-MAC
下一步提取40%,可以均匀采样3所示:
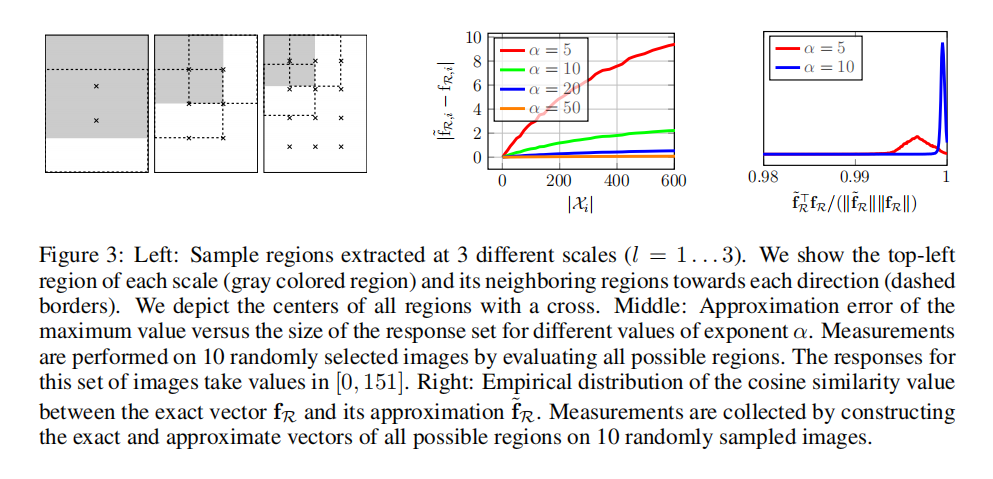
R-MAC( regional maximum activation of convolutions)计算如下:
- 采集多个尺度下的子区域;
- 分别计算子区域特征向量;
- 分别执行后处理(
L2归一化 + PCA-白化 + L2归一化); - 求和子区域特征向量得到单个特征向量;
- 最后执行
归一化。
目标定位
论文首先扩展了积分图计算,以实现近似最大池化(approximate max-pooling)操作;另外,论文还提出了一种目标定位方案,有助于尽可能缩减图像中搜索目标区域个数,提高检索效率。
近似积分最大池化操作
论文扩展了广义平均算法来模拟区域
$$
\tilde{f}{R,i}=(\sum{p\in R}X_{i}(p)^{\alpha})^{\frac{1}{\alpha}}\approx
\max_{p\in X_{i}(p)}=f_{R, i}
$$
其中3中显示了平均近似误差$\left| \tilde{f}{R,i} - f{R,i} \right|$与图像区域大小的关系:
越大,误差越低; - 图像区域越大,误差越高。
上述方法通过累加各个空间位置的大小来近似模拟最大池化的计算。这样的话通过积分图(Viola & Jones 人脸检测2001年经典论文)算法就可以进行区域特征向量4个角点就可以完成最大池化值的计算。
论文随机采样了10张图像,计算所有可能区域并比较了精确区域向量3右所示。最终定义超参数10。
窗口检测
假定图像
$$
\hat{R}=argmax {R\subseteq \Omega}\frac{\tilde{f}{R}^{T}q}{\left|\tilde{f}_{R} \right| \left|q \right| }
$$
区域branch and bound)搜索算法(2009年发布的论文ESS),虽然有效降低了搜索区域个数但是仍旧存在检索速度慢,占用内存高的缺陷。
AML
论文进一步对分支定界搜索算法进行了优化,提出AML(approximate max-pooling localization)搜索策略,限制了提出区域的个数以及检索方式。
检索、定位以及重排序
论文详细描述了在初始搜索和重排序阶段的具体优化实现。
初始检索
计算数据集和查询集图像的MAC或者R-MAC特征向量。在初始检索阶段,使用MAC/R-MAC特征向量计算查询图像与数据集图像两两之间的余弦相似度,并按照相似度大小进行排序。
重排序
在重排序阶段,对初始搜索阶段中相似度排序前AML,每张数据集图像分别获取多个候选区域,计算与查询集图像的相似度,选取最高的一个候选区域参与重排序。
注意:在初始搜索阶段可以使用白化-MAC或者R-MAC;在AML定位过程中使用L2归一化MAC,完成定位后,再次使用白化MAC或者R-MAC进行排序。
查询扩展
进行上述重排序操作之后,论文还提出可以再次使用查询扩展算法进行重排序。合并查询图像和排序Top-5图像的特征向量,再次对前Top-N图像进行相似度排序。
实验
设置
- 数据集:
Oxford5k(5063张图像)、Paris6k(6412张图像),以及100k的干扰图像; - 评估标准:
mean Average Precision (mAP); PCA:测试Oxford5k数据集时从Paris6k中学习,反之亦然;- 卷积特征:
AlexNet:ImageNet预训练,提取最后的池化层输出,特征通道数为256;VGG16:ImageNet预训练,提取最后的池化层输出,特征通道数为512。
定位准确率
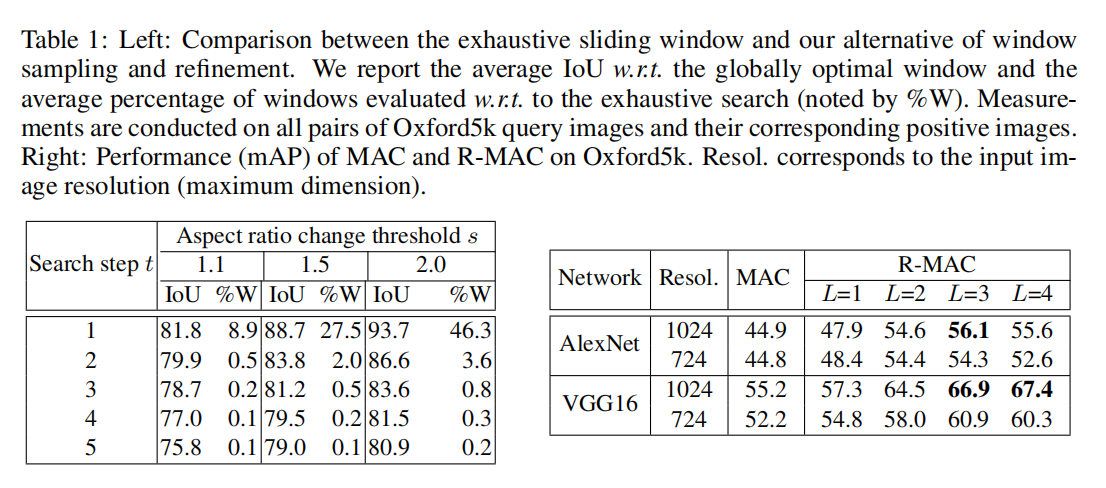
评估AML的定位准确率,论文使用Intersection over Union (IoU)评估定位结果,如上表一所示。最终设置超参数
检索和重排序
评估MAC和R-MAC进行检索的性能,其中每个MAC向量执行了L2归一化、PCA-白化以及再次L2归一化,R-MAC的后处理如上面章节所述。实验结果如上表一所示,论文还比较了不同输入大小图像的影响,发现保持原始图像大小能够得到更好的效果。论文也评估了不同尺度特征区域的影响,单独融合VGG16在Oxford5k上得到mAP=63.0;进一步融合mAP=65.4;最后融合mAP=66.9。在后续实验中,对于R-MAC提取,设置超参数
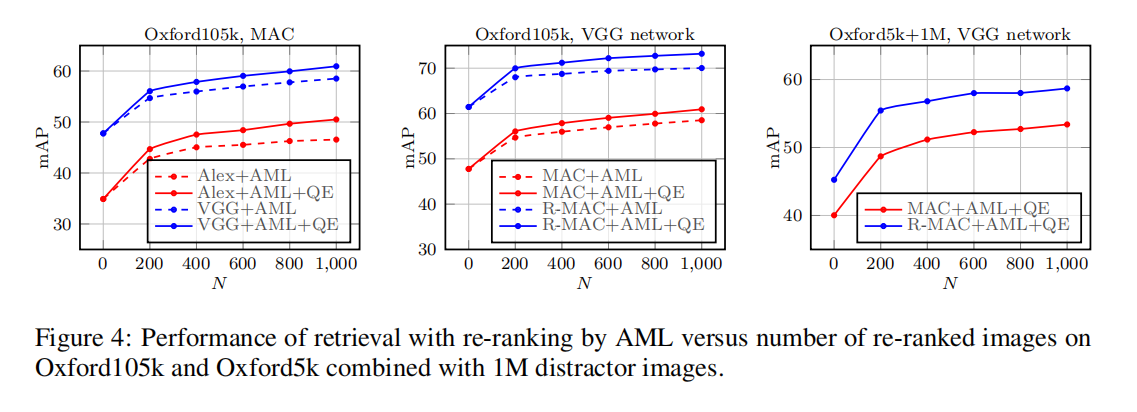
论文还研究了AML在重排序阶段的性能提升,如下图4所示。
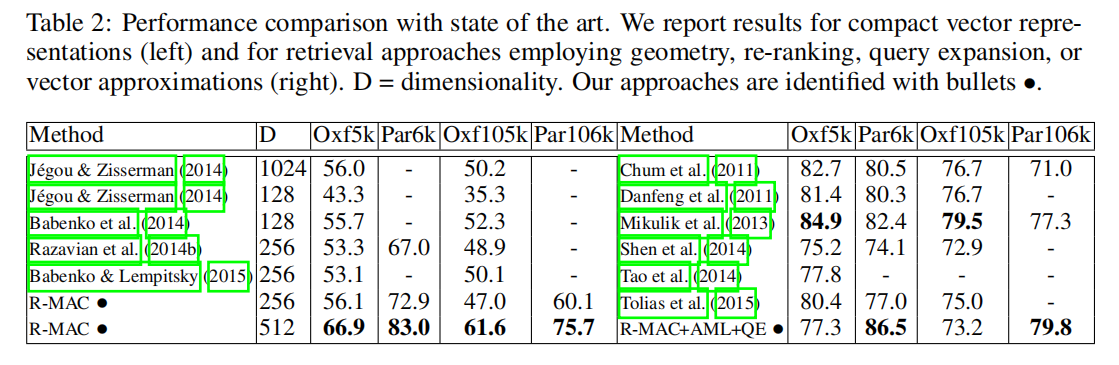
比较SOTA
论文还比较了其他最先进的基于局部特征的图像检索算法,显示了R-MAC+ AML + QE的优越性:
小结
论文针对初始搜索阶段和重排序阶段进行了改进。对于初始排序阶段,首先提出MAC(Maximum activations of convolutions),其实现就是针对卷积层输出的特征张量执行全局最大池化操作;然后进一步改进提出R-MAC(Regional maximum activation of convolutions),通过固定网格大小采集多个不同尺度子区域,分别对各个子区域执行最大池化操作(提取MAC特征向量)后进行聚合得到最终的特征向量。在重排序阶段,对相似度排序前Top-N数据集图像再次进行排序。提出AML(approximate max-pooling localization)定位算法,从每个候选图像中提取多个候选区域,和查询集图像两两计算相似度,选择相似度最大的一个子区域参与重排序。
相较于之前的Visual Instance Retrieval with Deep Convolutional Networks或者Aggregating Deep Convolutional Features for Image Retrieval,本文提出了一个更加完整的图像检索算法:不仅仅关注于特征描述符的建立,还改进了重排序阶段的实现。
R-MAC使用固定网格进行子区域提取和融合,不可避免的会融合大量背景区域,增加背景噪声的干扰;另外AML基于分支定界算法的优化进行目标定位,相对于基于深度学习的目标检测算法而言缺乏检测准确率和检测效率。这些都是后续论文提出的优化路径。