Learning Transferable Visual Models From Natural Language Supervision
摘要
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained model weights at this https https://github.com/openai/CLIP.
目前最先进的计算机视觉算法经过训练后能够预测一组固定的目标类别,但是这种有监督的预训练方式约束了算法的通用性和可用性,因为如果要识别其他类别需要额外的标记数据进行训练。直接从原始文本中学习图像是一种有前景的替代方案,它利用了更广泛的监督来源。我们证明了一种高效且可扩展的预训练方法,从互联网收集4亿条图像-文本对数据集,然后从头开始训练哪个文本对应哪个图像,就能够学习得到SOTA算法。预训练完成后,可以使用自然语言来描述学习到的视觉类别(或者没有出现在预训练数据集中的类别),使模型能够以零样本的方式迁移到下游任务。我们通过对30多个不同的现有计算机视觉数据集进行基准测试来研究这种方法的性能,这些数据集涵盖了OCR、视频动作识别、地理定位和许多类型的细粒度目标分类等任务。该模型可以轻松地迁移到大多数任务中,不需要任何特定于数据集的训练,性能上就可以和有监督的基线方法相媲美。比如,我们的算法不需要使用ImageNet训练数据集(128w张图片),准确率就可以媲美ResNet-50。预训练的模型和推理代码已开源:https://github.com/openai/CLIP。
CLIP概述
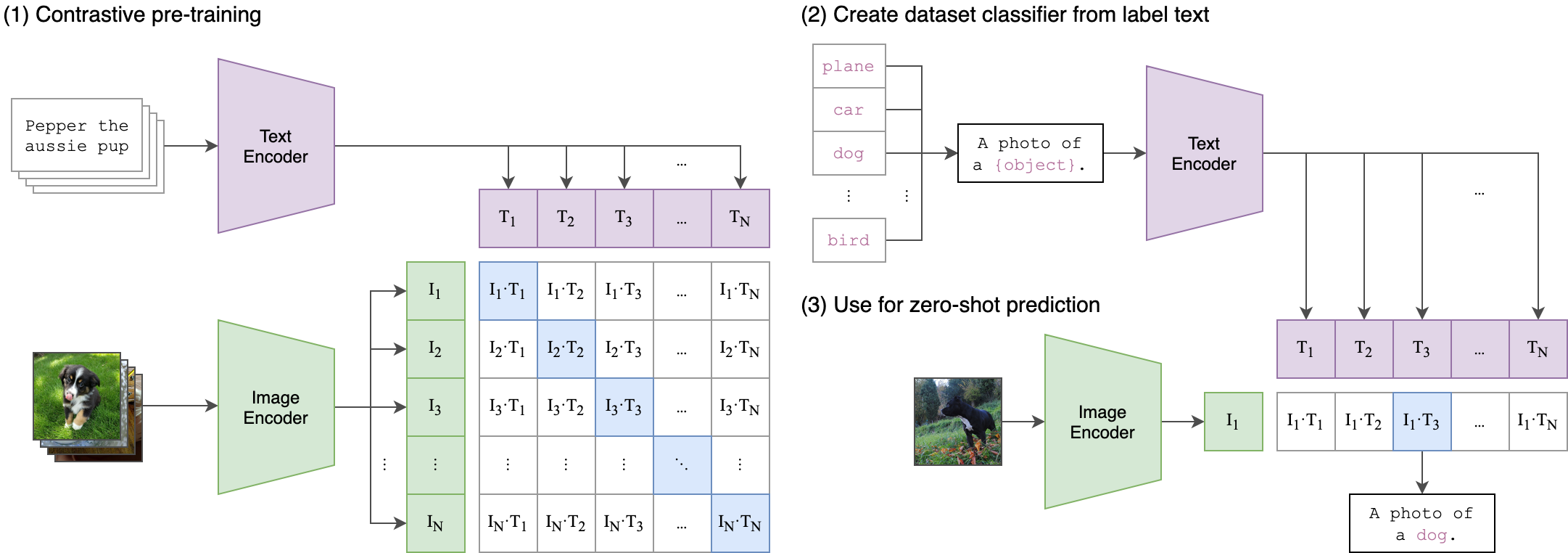
在NLP领域已经发生了预训练算法的范式革命,使用任务无关的算法架构(task-agnostic architectures)预训练从互联网收集的海量数据(web-scale collections of text),就可以以零样本的方式迁移到下游任务,代表性的算法就是2020年发布的GPT-3。但是在计算机视觉领域,使用人工标记数据集(crowd-labeled datasets)进行算法训练还是主流范式,虽然之前很多年一直有人在研究无监督训练的方法,在基准数据集上的验证效果一直不如有监督训练的算法。本文有两点创新,一是通过互联网收集创造了更大规模的图像-文本对数据集,一共包含4亿条图像-文本对(400 million (image, text) pairs);二是设计了全新的算法架构CLIP(Contrastive Language-Image Pre-training),是一种从自然语言监督中学习的有效方法。论文在计算机视觉算法的基准数据集进行的实验证明了CLIP算法可以零样本(zero-shot)迁移到下游任务。
论文有详细介绍采集数据集和预训练CLIP的关键内容,不过并没有开源数据集和训练代码,只是开源了推理代码和预训练权重。有其他团队分别开源了超大规模的图像-文本对数据集和CLIP的训练工程。
CLIP的核心思想是**将图像和文本映射到同一个特征空间,使得它们的特征向量可以直接比较。特征向量经过归一化后,通过余弦相似度计算匹配程度。**在分类任务中,可以进一步将相似性分数转换为概率分布;在检索任务中,可以直接使用相似性分数。论文提供了示例代码:

1 | # 导入必要的库 |
运行结果如下:
1 | (py39) zjykzj@LAPTOP-S3BIPLGN:~/repos/CLIP$ python3 demo.py |

图像编码器
对于图像预处理,CLIP算法的操作跟常规的深度学习算法没啥差别:
- 读取图像并转换到RGB颜色空间
- 等比缩放
- 中央裁剪
- 归一化到[0, 1]区间
- 标准化(Normalization)
1 | def _convert_image_to_rgb(image): |
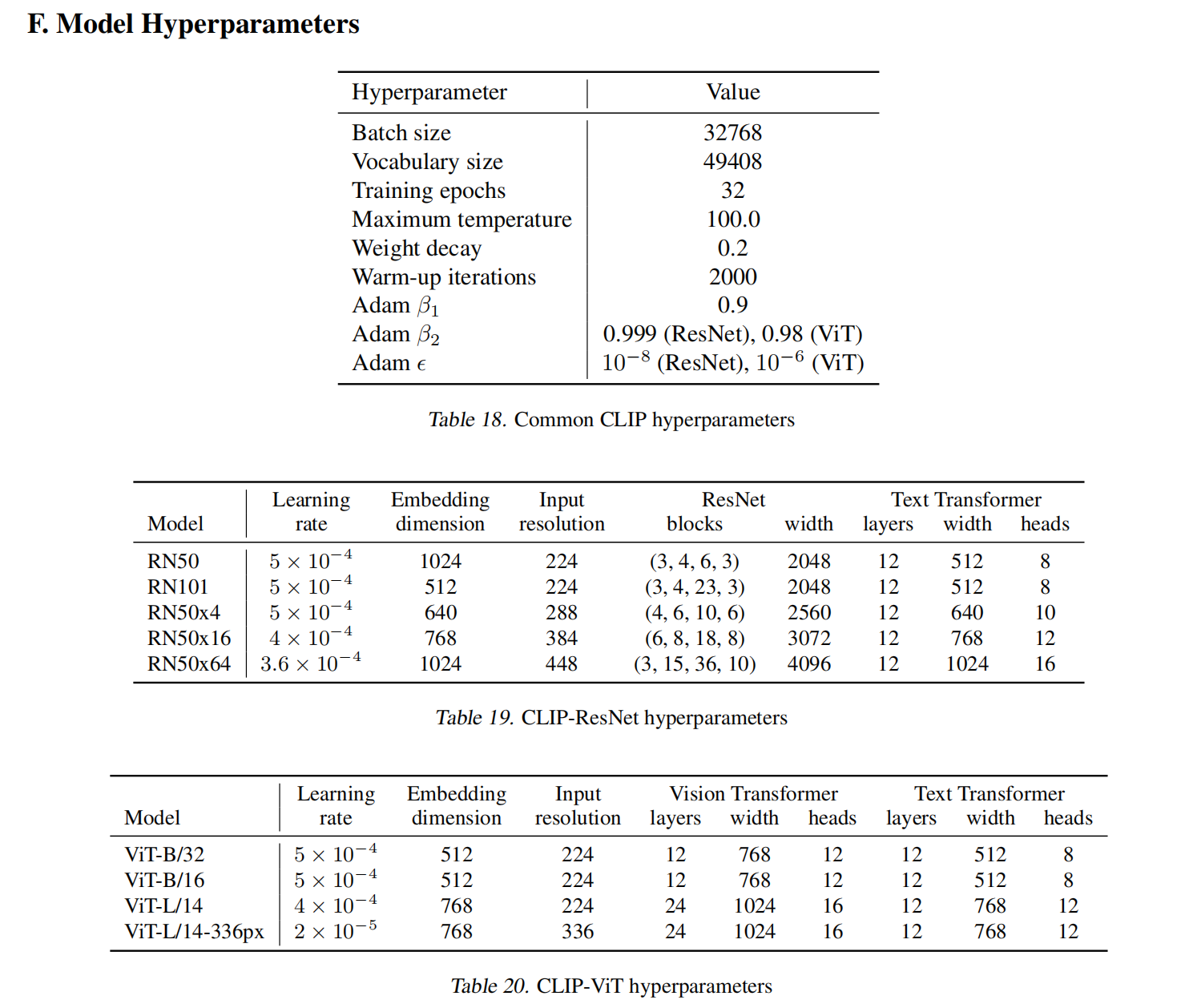
对于CLIP的图像编码器,论文尝试了多种算法架构,包括ResNet系列(RN50|RN101|RN50x4|RN50x16|RN50x64)和Vision Transformer系列(ViT-B/32|ViT-B/16|ViT-L/14|ViT-L/14@336px),输入预处理后的图像数据得到特征向量。
- 这里的RN50x4/x16/x64是论文基于EfficientNet方式通过复合缩放公式放大ResNet得到的算法架构,它们的计算量约等于ResNet50的4倍、16倍和64倍;
- 所有的模型均训练32轮,
- 对于RN50x64,使用592个V100 GPU训练了18天;
- 对于ViT-L/14,使用256个V100 GPU训练了12天;
- 训练完ViT-L/14之后,使用336像素输入大小额外训练一轮得到ViT-L/14@336px;
文本编码器
对于文本预处理,CLIP算法自定义了SimpleTokenizer,将文本列表通过BPE(Byte Pair Encoding)分词算法编码为token列表,从而将文本编码为向量形式。操作流程如下:
- 清理文本
- 对输入文本进行预处理,包括去除多余空白字符、修复损坏字符(如 HTML 实体或 Unicode 编码错误)等;
- 这一步确保文本在后续处理中不会因不规范的字符而产生问题。
- BPE分词
- 使用BPE算法将文本分割成子词单元(subword units);
- 每个子词单元会被映射到一个唯一的 token ID;
- 例如,单词
"diagram"可能被分解为子词["dia", "gram"],然后进一步映射为对应的token ID。
- 添加特殊标记
- 在每个文本的开头添加起始标记
<|startoftext|>,表示文本的开始; - 在每个文本的结尾添加结束标记
<|endoftext|>,表示文本的结束; - 最终token列表会变为:
[<|startoftext|>, token_1, token_2, ..., token_n, <|endoftext|>]。
- 在每个文本的开头添加起始标记
- 固定长度处理
- 注意:CLIP算法的文本编码器要求输入序列的长度固定为77(包括起始标记和结束标记);
- 所以实际的子词单元最多可以有75个(因为包含了起始标记
<|startoftext|>和结束标记<|endoftext|>); - 如果文本的token数量少于77,则会在末尾填充零(相当于
<PAD>标记); - 如果文本的token数量超过77,则会截断到77,并确保最后一个token是结束标记
<|endoftext|>。
对于文本编码器,论文参考2019年论文Language models are unsupervised multitask learners使用的基于Transformer的文本模型。
相似性计算
注意:不同架构的图像编码器输出的特征向量长度不一,同时CLIP算法针对不同架构的图像编码器配对了不同配置的文本编码器。模型具体细节如下:
完成图像特征向量和文本列表特征向量的计算后,
- 对图像特征向量和文本特征向量分别进行L2归一化(即将每个特征向量除以其L2范数)
- 这一步确保了特征向量的模长为1,从而简化后续相似度计算
- 计算图像特征向量与文本特征向量之间的余弦相似度,结果得到两个相似度矩阵
- logits_per_image:表示每个图像与所有文本的相似度
- logits_per_text:表示每个文本与所有图像的相似度(即logits_per_image的转置)
1 | class CLIP(nn.Module): |
提示词工程
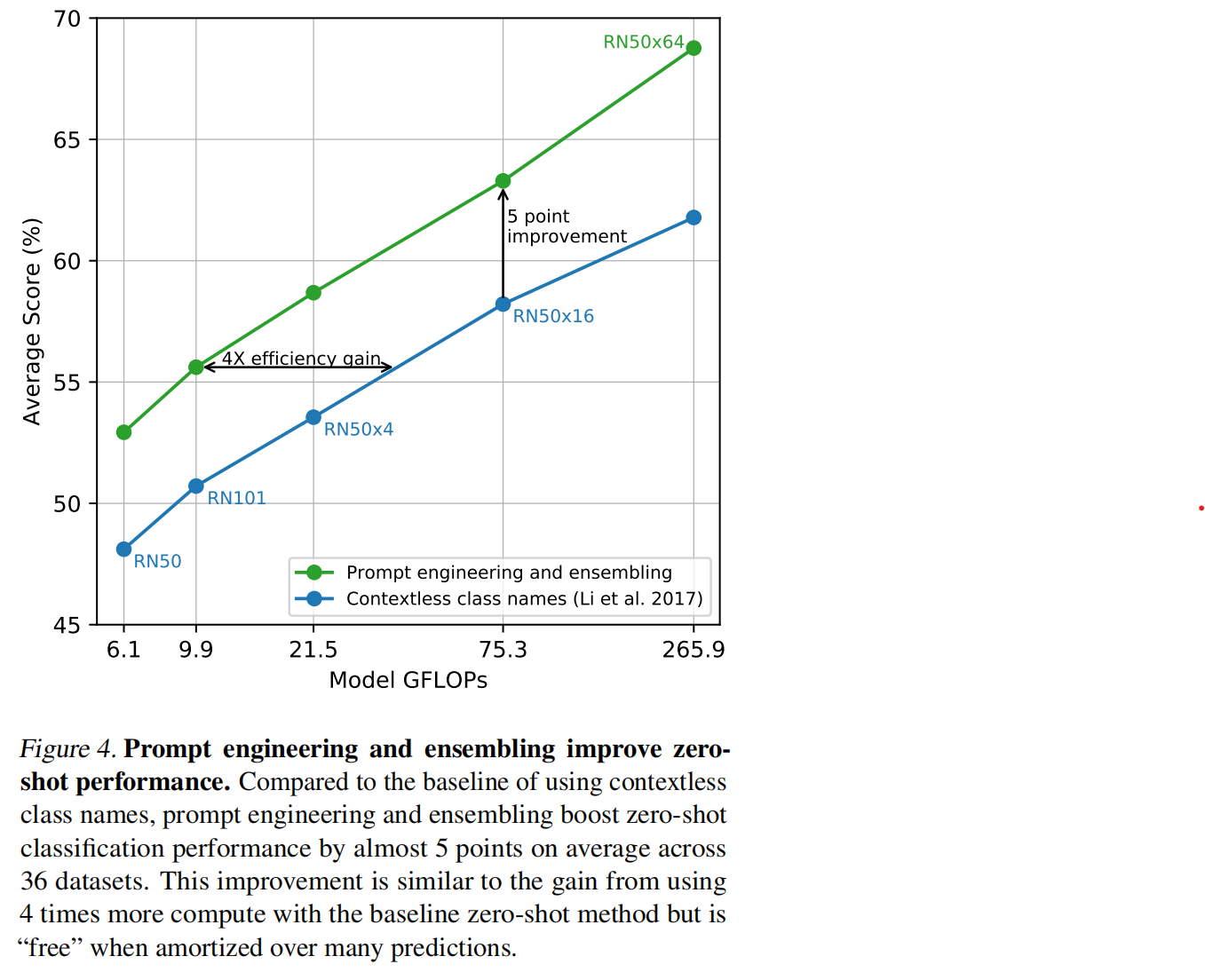
精心设计的提示词(Prompt)能够更有效地提升CLIP算法零样本迁移到下游任务的性能。比如在分类任务中,比起单纯使用无上下文的类别名称(Contextless Class Names),使用提示词模板A photo of a {label}.普遍能够得到更好的评估精度。这种技术通过为模型提供更具语义信息的输入,显著增强了泛化能力。
小结
我感觉CLIP的发布可以比对AlexNet在ImageNet 2012斩获图像分类竞赛第一名的时刻,它真正证明了大数据+多模态算法+无监督学习(自然语言监督)的有效性,为计算机视觉领域开辟了全新的赛道。虽然不完美,但是孕育了无限的可能性,无论是无监督学习的训练方法,上亿条的训练数据量和超大规模的GPU训练,还是CLIP模型的参数量、推理速度和推理精度,都提供了非常大的优化和突破空间。