Reproducible scaling laws for contrastive language-image learning
摘要
Scaling up neural networks has led to remarkable performance across a wide range of tasks. Moreover, performance often follows reliable scaling laws as a function of training set size, model size, and compute, which offers valuable guidance as large-scale experiments are becoming increasingly expensive. However, previous work on scaling laws has primarily used private data & models or focused on uni-modal language or vision learning. To address these limitations, we investigate scaling laws for contrastive language-image pre-training (CLIP) with the public LAION dataset and the open-source OpenCLIP repository. Our large-scale experiments involve models trained on up to two billion image-text pairs and identify power law scaling for multiple downstream tasks including zero-shot classification, retrieval, linear probing, and end-to-end fine-tuning. We find that the training distribution plays a key role in scaling laws as the OpenAI and OpenCLIP models exhibit different scaling behavior despite identical model architectures and similar training recipes. We open-source our evaluation workflow and all models, including the largest public CLIP models, to ensure reproducibility and make scaling laws research more accessible. Source code and instructions to reproduce this study will be available at https://github.com/mlfoundations/open_clip.
放大神经网络被证明是有效的提升算法性能的方式,已经在许多任务中取得显著的成果。此外,缩放定律(scaling laws)可以总结为训练集大小、模型参数量和训练计算量(GMAC per sample x samples seen)的函数,随着大规模实验变得越来越昂贵,这提供了有价值的指导。然而,之前关于缩放定律的研究大多使用私有数据,而且局限于单纯语言模型或者视觉模型。对此,我们使用公开的LAION数据集和对比语言-图像预训练(CLIP)算法进行缩放定律的研究,同时开源了工程实现OpenCLIP。我们的大规模实验使用了多达20亿条图像-文本对训练数据,在多个下游任务中验证了基于幂律格式的缩放定律(power law scaling)对于预训练的有效性,这些下游任务包括零样本分类、图像检索、线性分类器微调(linear probing)以及端到端微调。我们发现训练数据分布(the training distribution)在缩放定律中扮演了重要的角色,即使OpenAI和OpenCLIP的模型拥有相同的模型架构和类似的训练配置,不一样的训练数据集会得到不一样的效果。我们开源了评估工作流程和所有模型以确保可重复性,这样缩放定律的研究可以更容易被其他人继续。源代码和训练指令位于https://github.com/mlfoundations/open_clip。
OpenCLIP
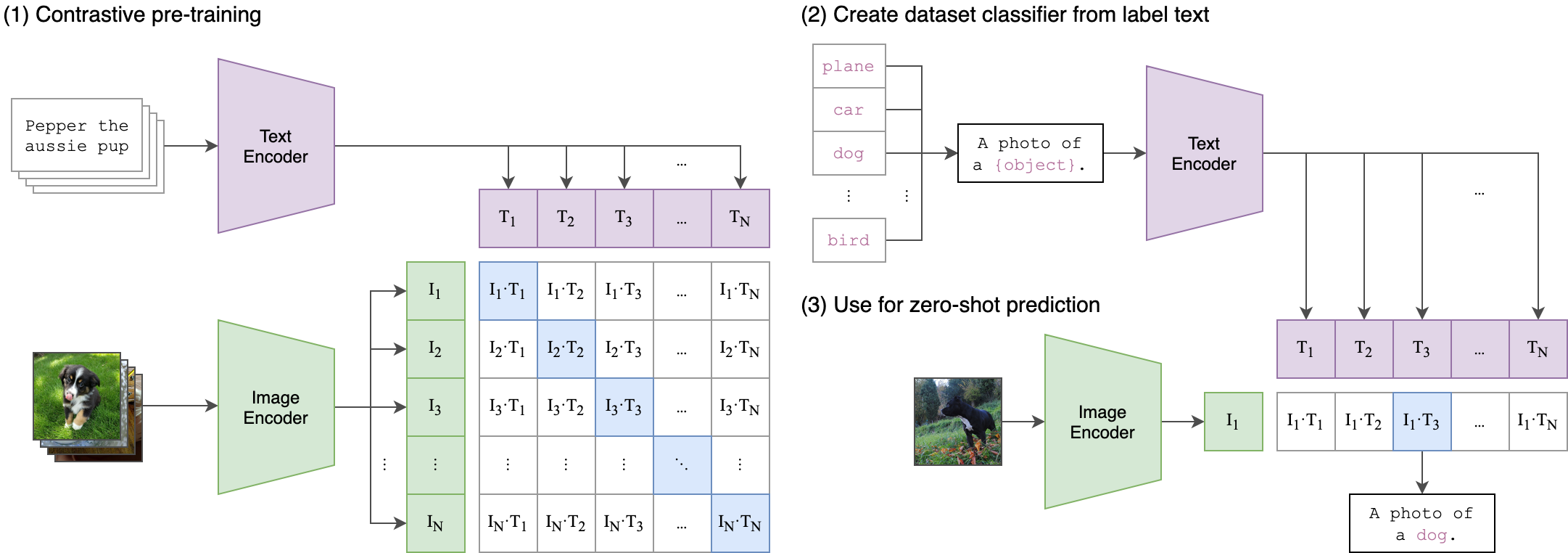
论文针对CLIP算法进行复现,首先它参考CLIP算法设计了相同的模型架构和相似的训练配置(最大区别在于批量训练大小以及对应的参数调整,并且通过实验证明了Batch Size的变化影响不大),其次对于数据集,因为原始CLIP算法使用的是私有数据集WIT(WebImageText),本论文使用公开数据集LAION进行训练。通过对下游任务的评估,可以确认OpenCLIP算法成功复现了CLIP算法。
通过构建一系列实验,论文发现:
- 复合放大模型参数量(
model size)、训练集大小(dataset size)和训练数据量(samples seen,这里指的应该是训练过程中遍历的数据量大小)可以有效的提高语言-视觉多模态算法的性能,并且这个复合缩放定律符合幂律放大的规律(scaling laws in the form of power law); - 在下游任务(零样本分类/图像检索/线性分类器微调/端到端微调(
zero-shot classification, image retrieval, and fine-tuning via linear probing and end-to-end optimization.))的评估中,论文发现OpenCLIP算法和CLIP算法在不同任务中的放大表现不一致,比如在保持相同模型架构和相似训练配置(主要差别仅在于批量大小和对应的训练配置调整)的情况下,对于零样本图像分类任务,CLIP算法比较OpenCLIP算法拥有更大的放大系数,也就是说,复合放大模型大小、数据集大小和数据计算大小,CLIP算法能够得到更好的性能;又比如零样本图像检索任务,OpenCLIP算法表现出比CLIP算法更加优秀的放大趋势。论文分析是因为不同数据集的数据来源和数据分布导致的差异性。
最后,论文还开源了OpenCLIP的工程实现和训练指令,以帮助后续其他人的工作。
LAION数据集
- LAION-400-MILLION OPEN DATASET
- LAION-5B: A NEW ERA OF OPEN LARGE-SCALE MULTI-MODAL DATASETS
- LARGE SCALE OPENCLIP: L/14, H/14 AND G/14 TRAINED ON LAION-2B
LIAON(https://laion.ai/projects/)提供了多个超大规模的图像文本对(image-text pair)数据集,包括LAION-5B、LAION-2B和LAION-400M等等。
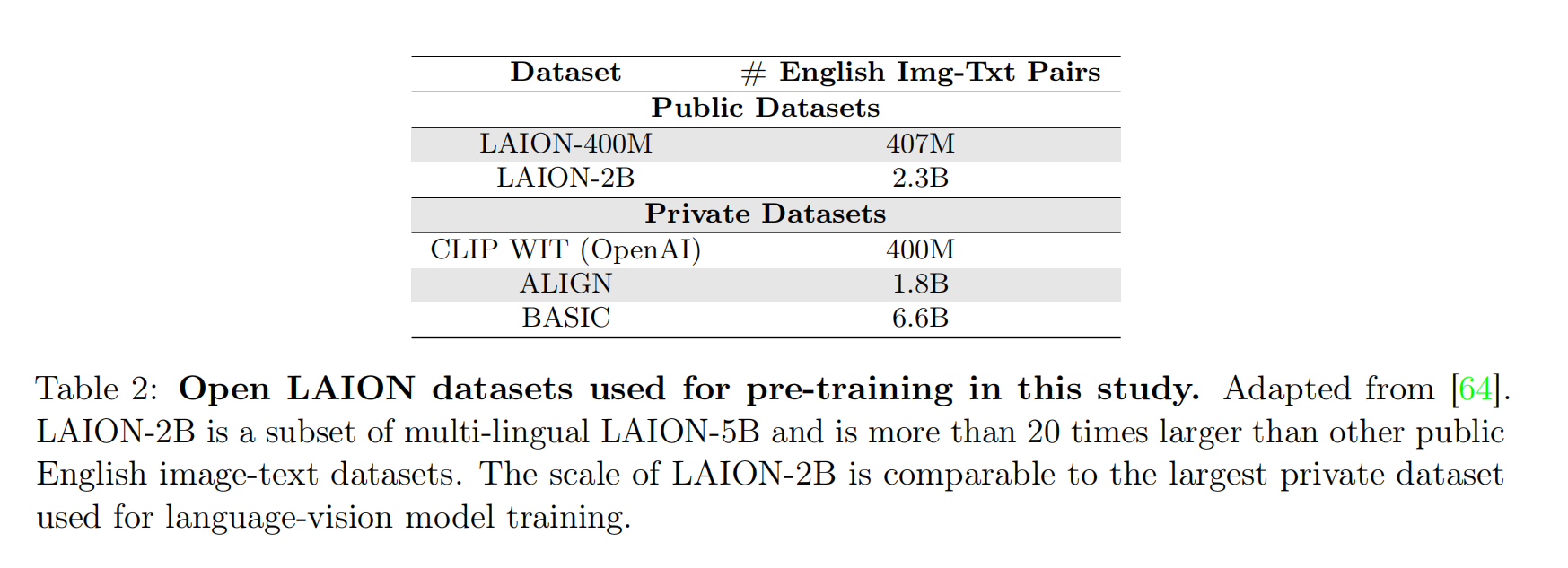
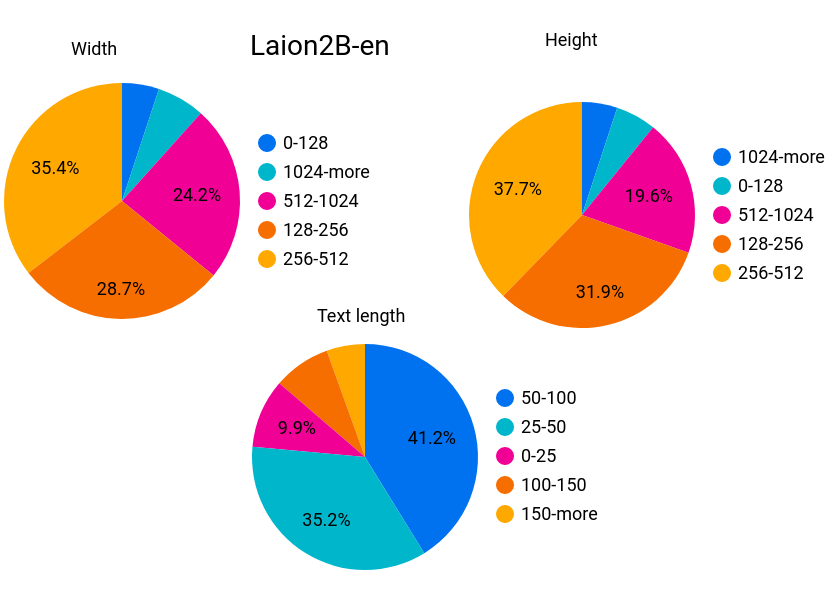
- LAION-400M:拥有
400M条英语图像-文本对(English (image, text) pairs)。LAION使用OpenAI CLIP算法来过滤LAION-400M数据集中所有的图像和文本,计算文本特征和图像特征之间的余弦相似度,并删除相似度低于0.3的图像-文本对。按照图像宽/高统计的数据情况如下:
1 | Number of unique samples 413M |
- LAION-5B:LAION发布的超大规模多模态图像-文本对数据集,拥有
5.85 Billion条图像-文本对,参考LAION-400M的方式进行CLIP算法过滤。 - LAION-2B:LAION-5B中包含了2.32B条图像-文本对,采集这批数据得到LAION-2B;
实验配置
论文在3个维度(model scale, data scale and the number of samples seen during pre-training)尝试不同配置的组合,
- 对于模型架构,
- OpenCLIP模型架构适配CLIP模型架构;
- 对于视觉编码器,论文实验了ViT-B/32, ViT-B/16, ViT-L/14, ViT-H/14 and ViT-g/14;
- 对于文本编码器,根据视觉编码器的变化进行对应调整;
- 对于数据集,
- 论文使用LAION-80M(是LAION-400M的子集)、LAION-400M和LAION-2B进行实验
- 对于训练数据量,
- 论文设计了3B、13B和34B的实验。
零样本图像分类
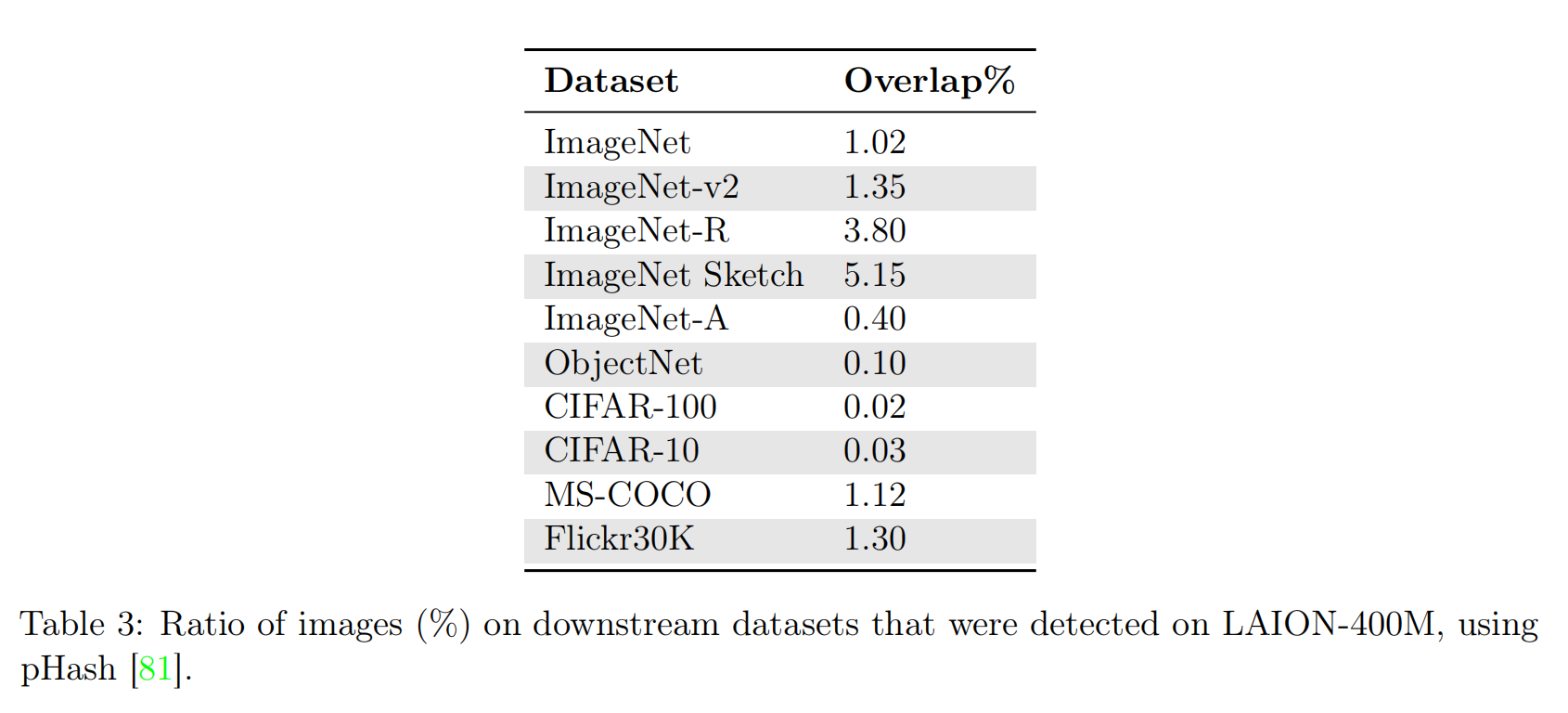
针对图像分类任务,论文选择ImageNet、ImageNet distribution shift datasets and the visual task adaptation benchmark (VTAB)进行评估。首先使用pHash库进行简单校验,确保训练数据集和图像分类测试数据集之间几乎没有重叠。

参考其他论文的研究,论文对每个类别使用一组预定义的提示词(a set of pre-defined prompts for each class),使用文本编码器计算每个提示词的文本特征,平均这组预定义提示词的文本特征后进行L2归一化最终得到该类别的文本特征,最后逐个类别计算图像特征和文本特征之间的余弦相似度,相似度最高的图像-文本对判定为分类类别。
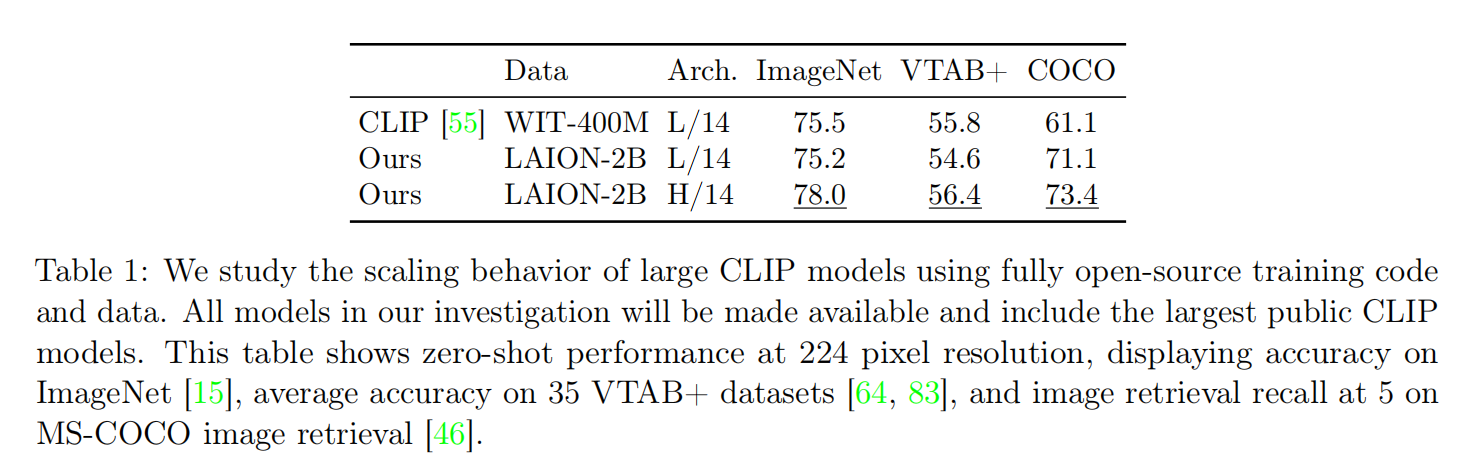
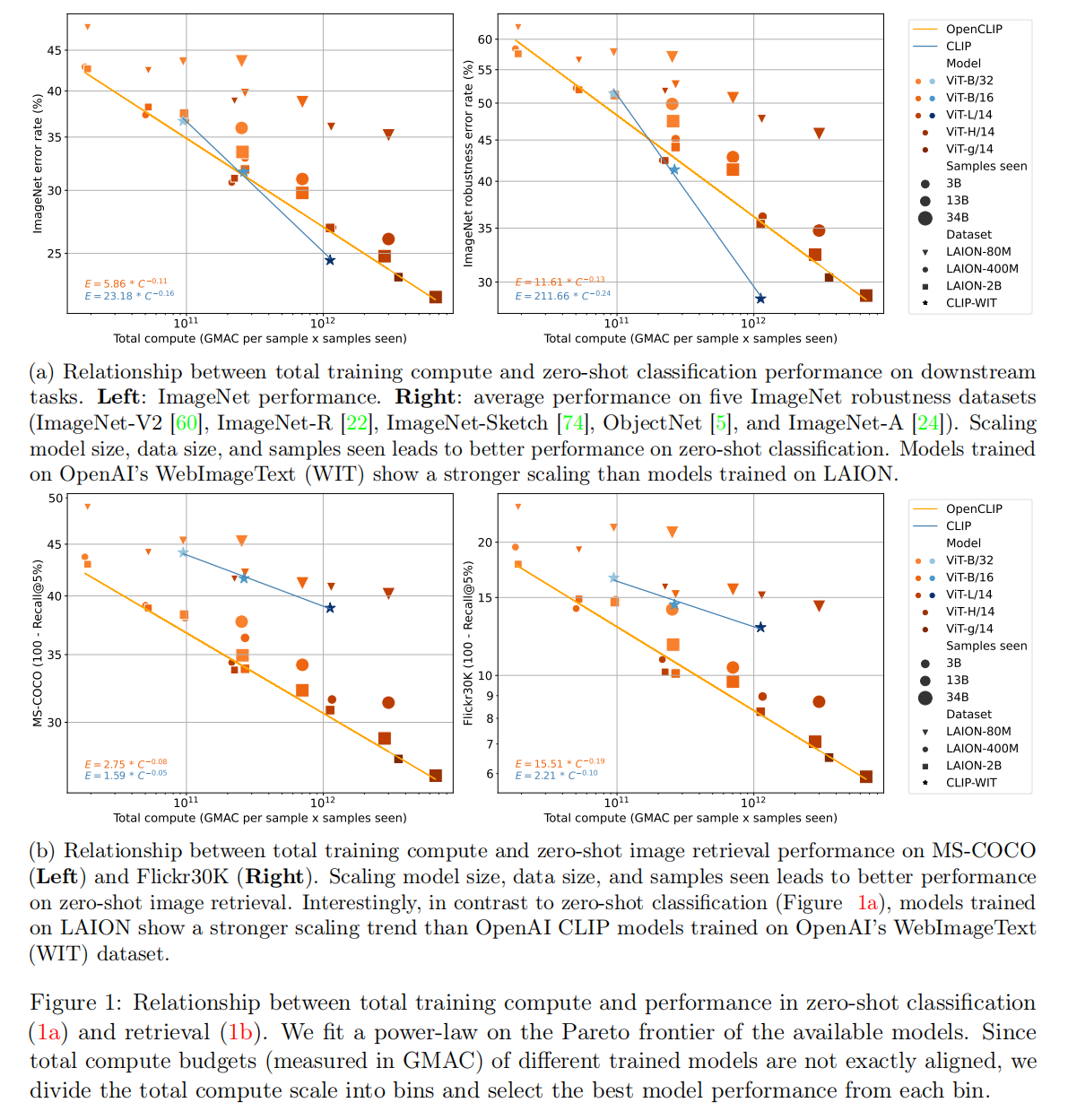
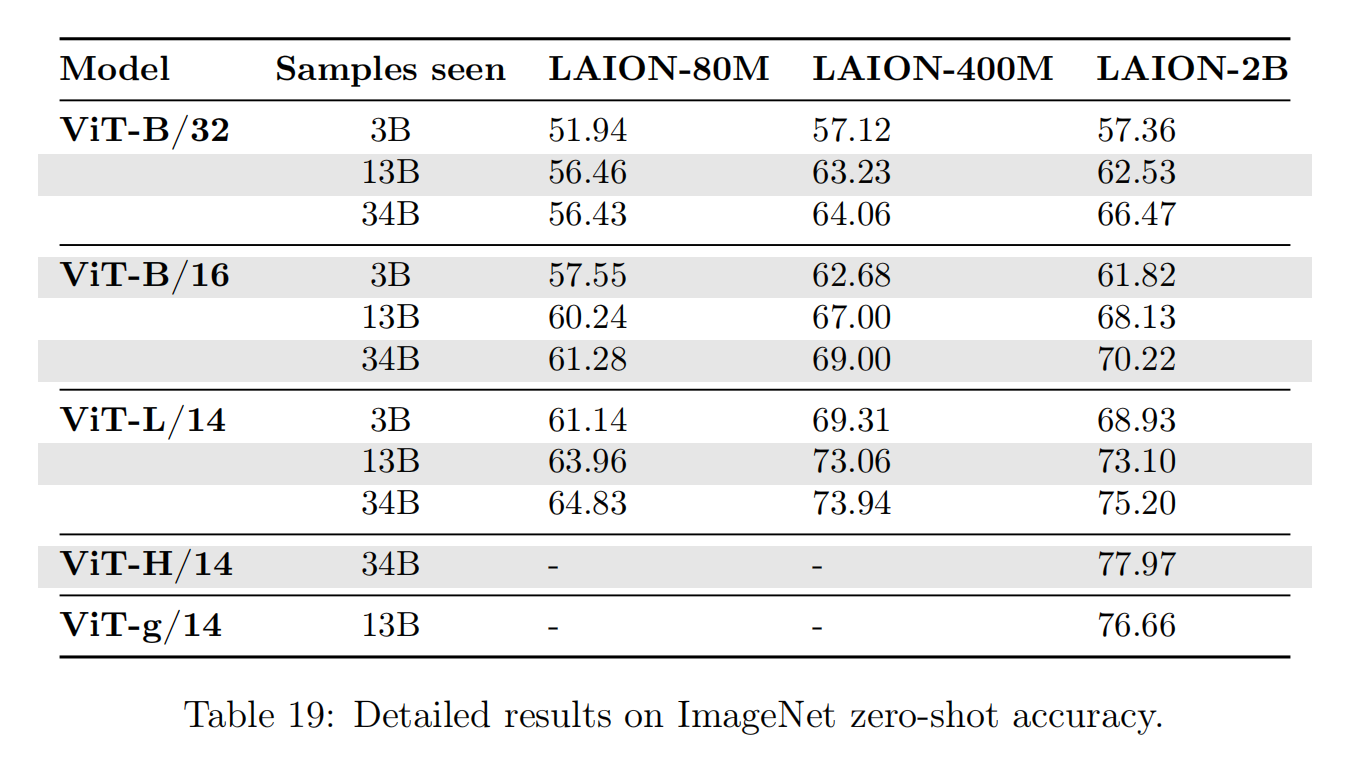
论文发现复合放大模型、数据集和训练数据量可以有效的提高算法性能,最好的ImageNet分类精度(78%)来自于ViT-H/14、LAION-2B和34B samples seen的组合。另外,论文也发现规模(scale)因素有很大影响,比如有限度的放大数据集(从400M -> 2B)和训练数据量(3B或者13B),OpenCLIP模型ViT-B/32和ViT-B/16的性能变化有限,而当数据集和训练数据量分别提高到2B和34B时,能够得到清晰的模型性能增益。如下图表19所示(小尺度规模的放大看起来也是有效果的,就是性能增益没有更大规模的训练明显),
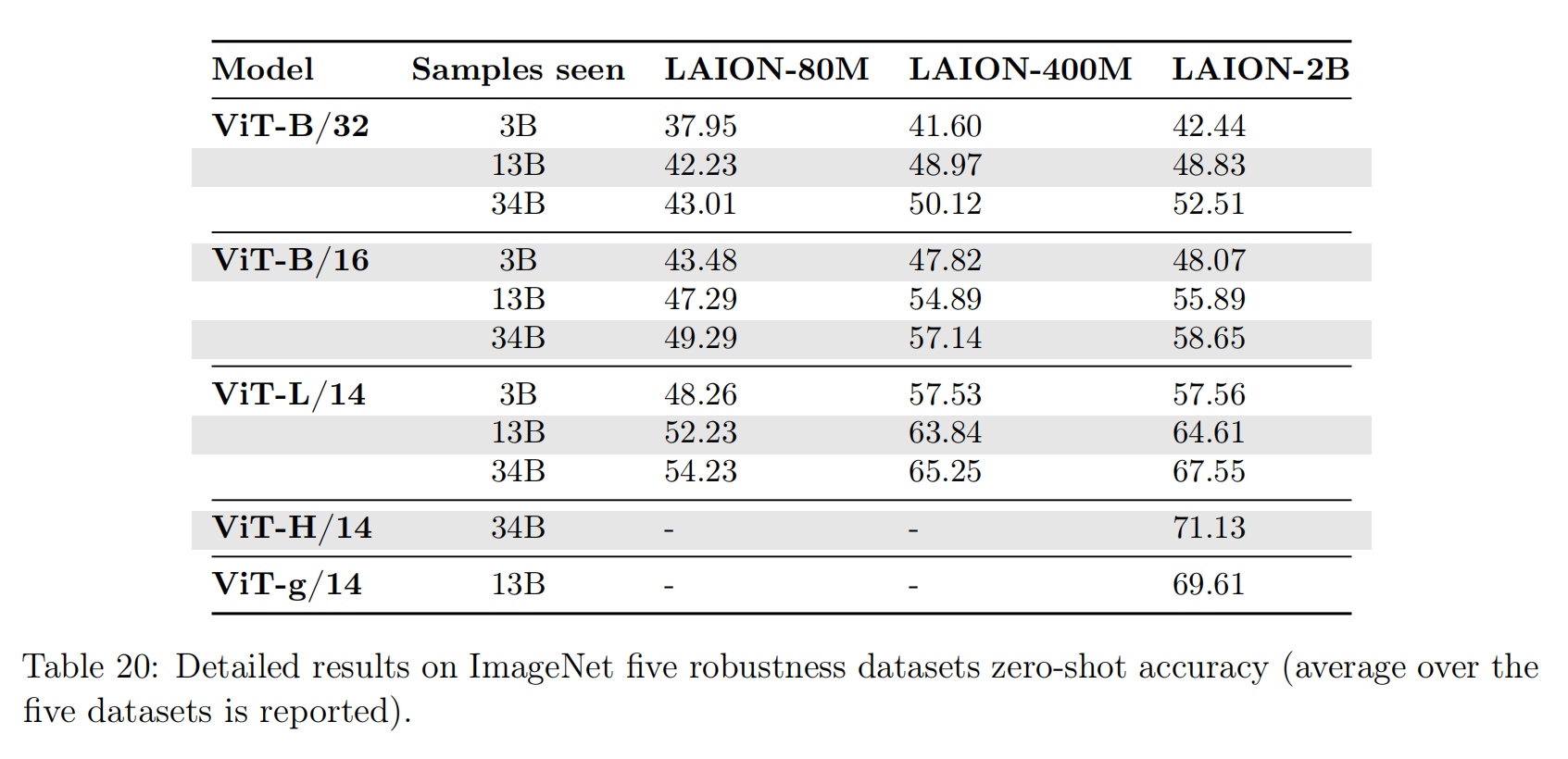
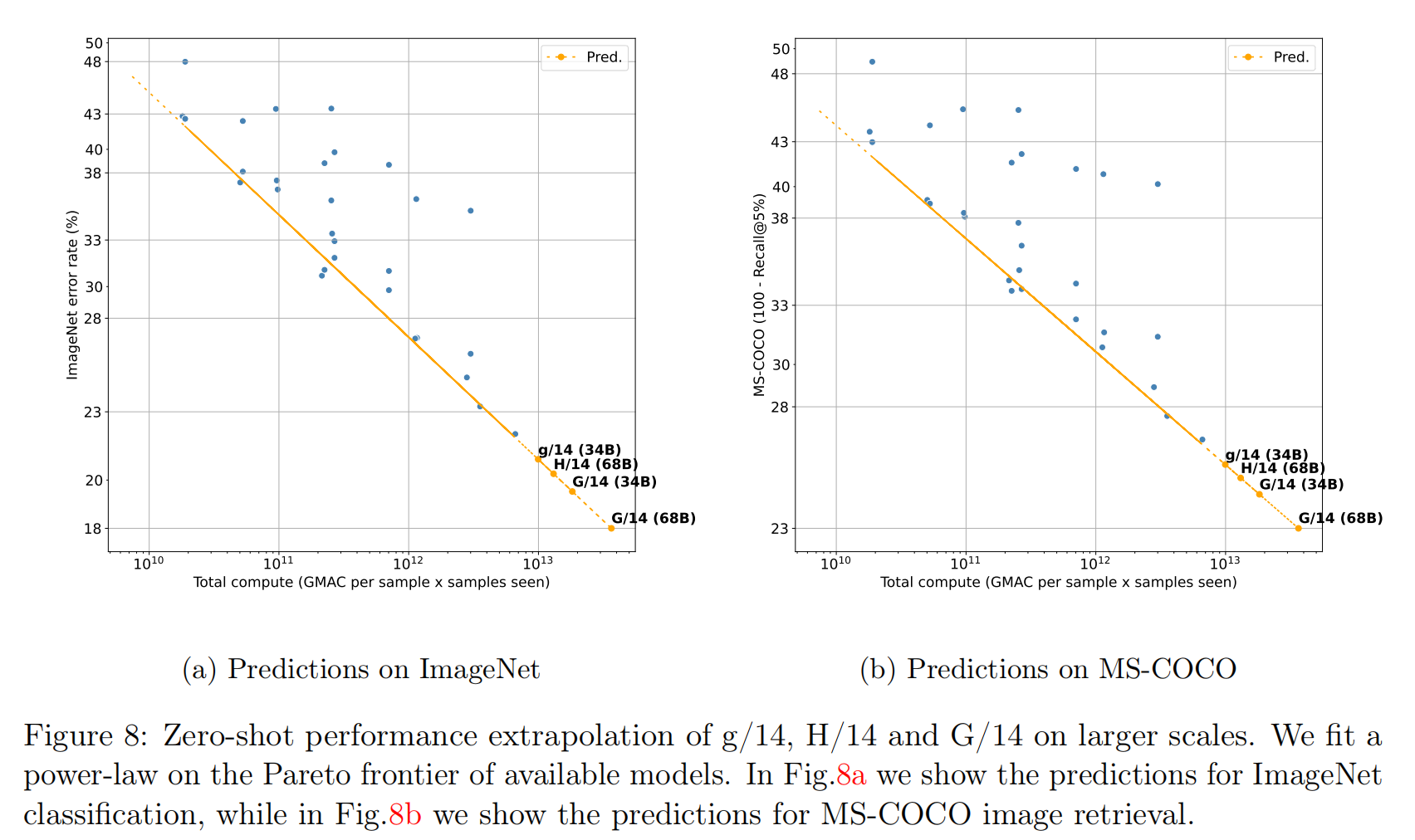
论文根据做过的实验拟合了幂律公式(\(E=\beta C^{\alpha}\)),可以对更大规模的OpenCLIP算法进行预测,比如对于ViT-g/14、2B和34B配置,在ImageNet验证集的零样本图像分类精度可以达到79.1% Top1;在2B数据集和68B训练数据量的情况下,ViT-H/14、ViT-g/14和ViT-G/14分别可以实现79.7%、80.7%和81.9%的分类精度。
零样本图像检索
针对图像检索任务,论文评估了MS-COCO和Flickr30K数据集,计算图像-文本对的余弦相似度,然后按照成绩进行排序计算TOP5 召回率(Recall@K(K=5))。测试结果可以观察到和零样本图像分类任务相似的结论,
- 复合放大模型、数据集和训练数据量可以有效的提高算法性能;
- 需要更大规模的数据集和训练数据量才能够得到更加明显的性能增益(也就是说小规模放大的配置存在规模瓶颈效应(
scale bottleneck effect))。
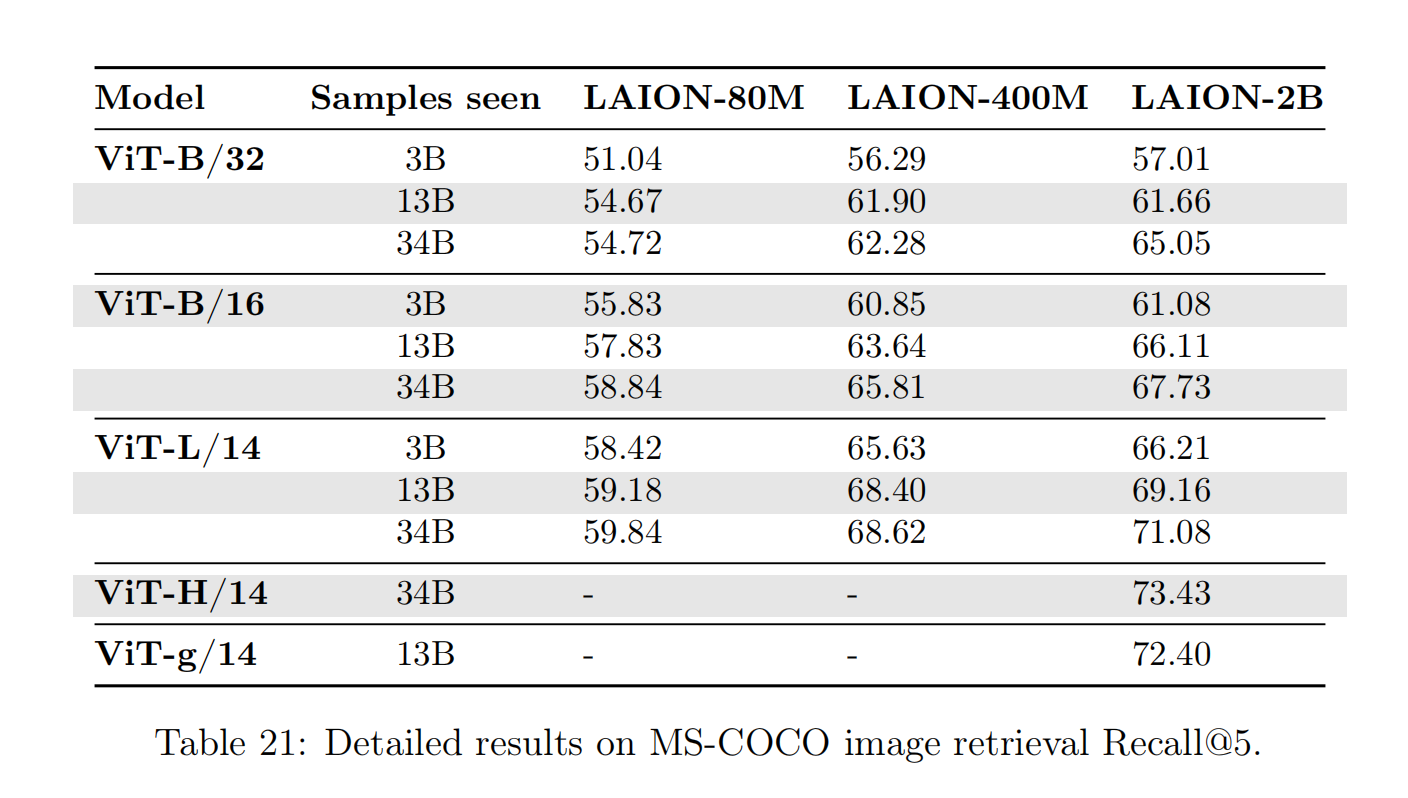
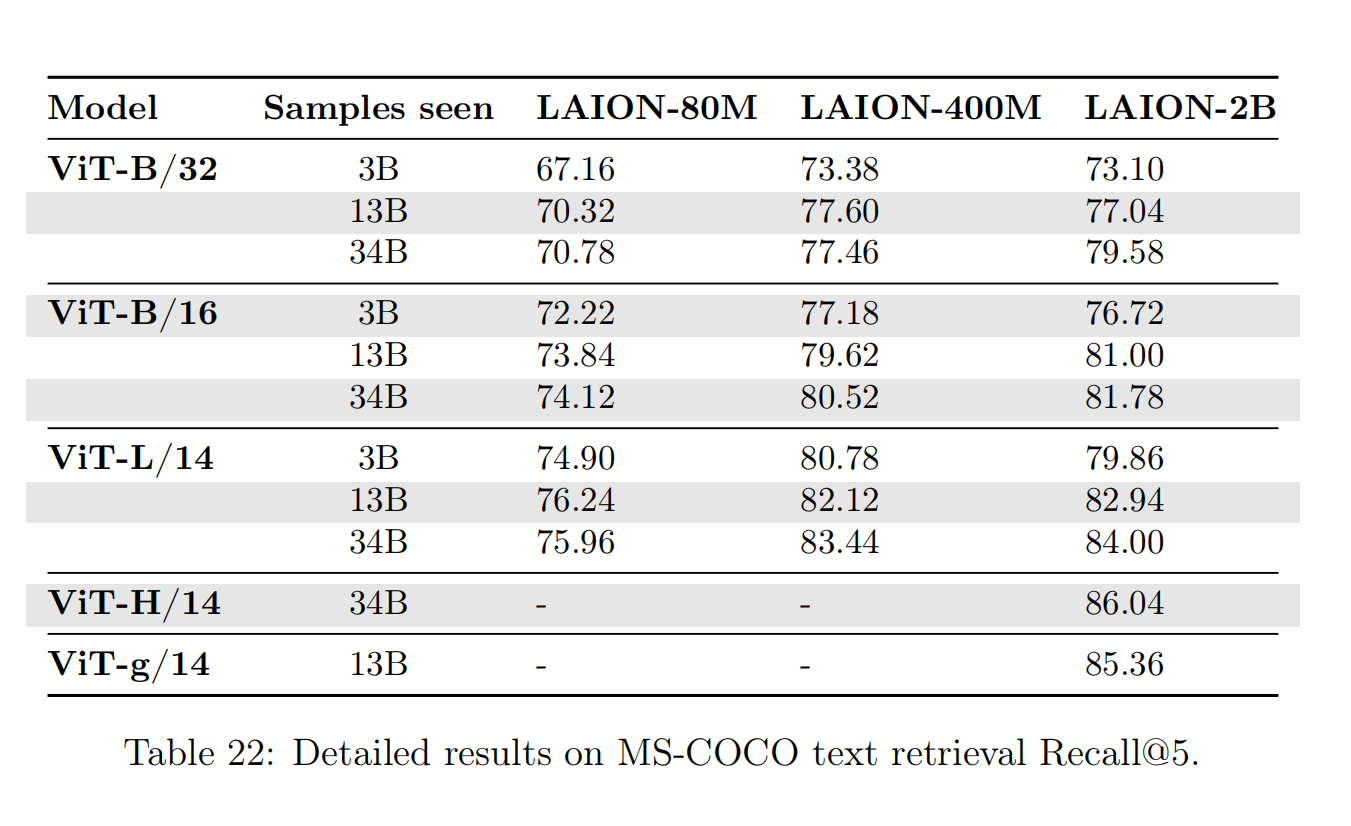
最后,根据实验结果拟合缩放规律的幂律公式,论文发现在零样本图像检索任务中,OpenCLIP算法比较CLIP算法具有更好的放大优势(差别在于训练数据集的数据分布),这个观察与零样本图像分类任务相反。
线性分类器微调
线性分类器微调(linear probing)指的是冻结预训练模型的Backbone权重,使用下游任务的训练数据集从头开始训练最后一层分类器。对于训练线性分类器的数据集,有两种采集方式,一是每个类别采集固定数据量数据进行微调训练;而是使用全部训练数据集。
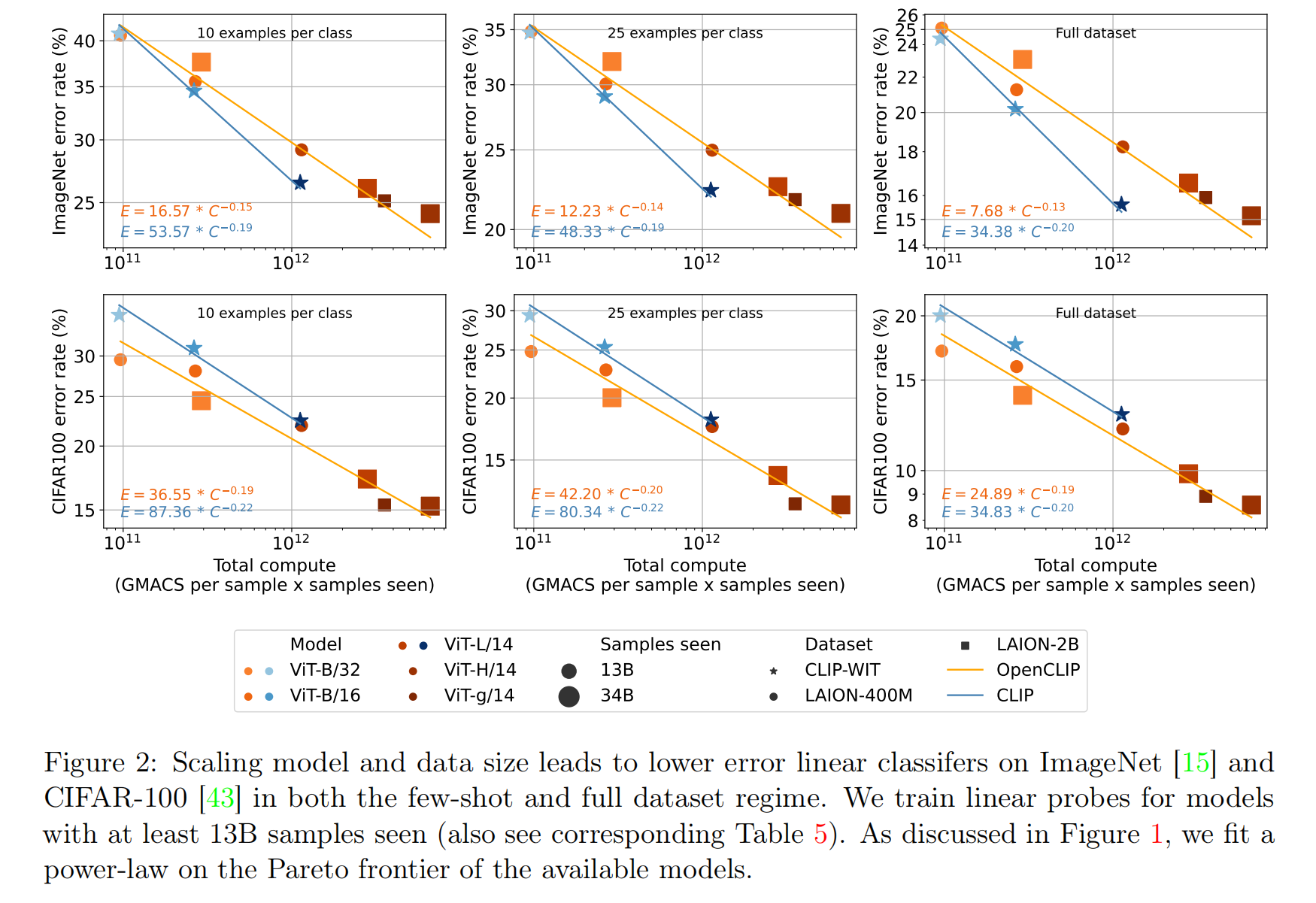
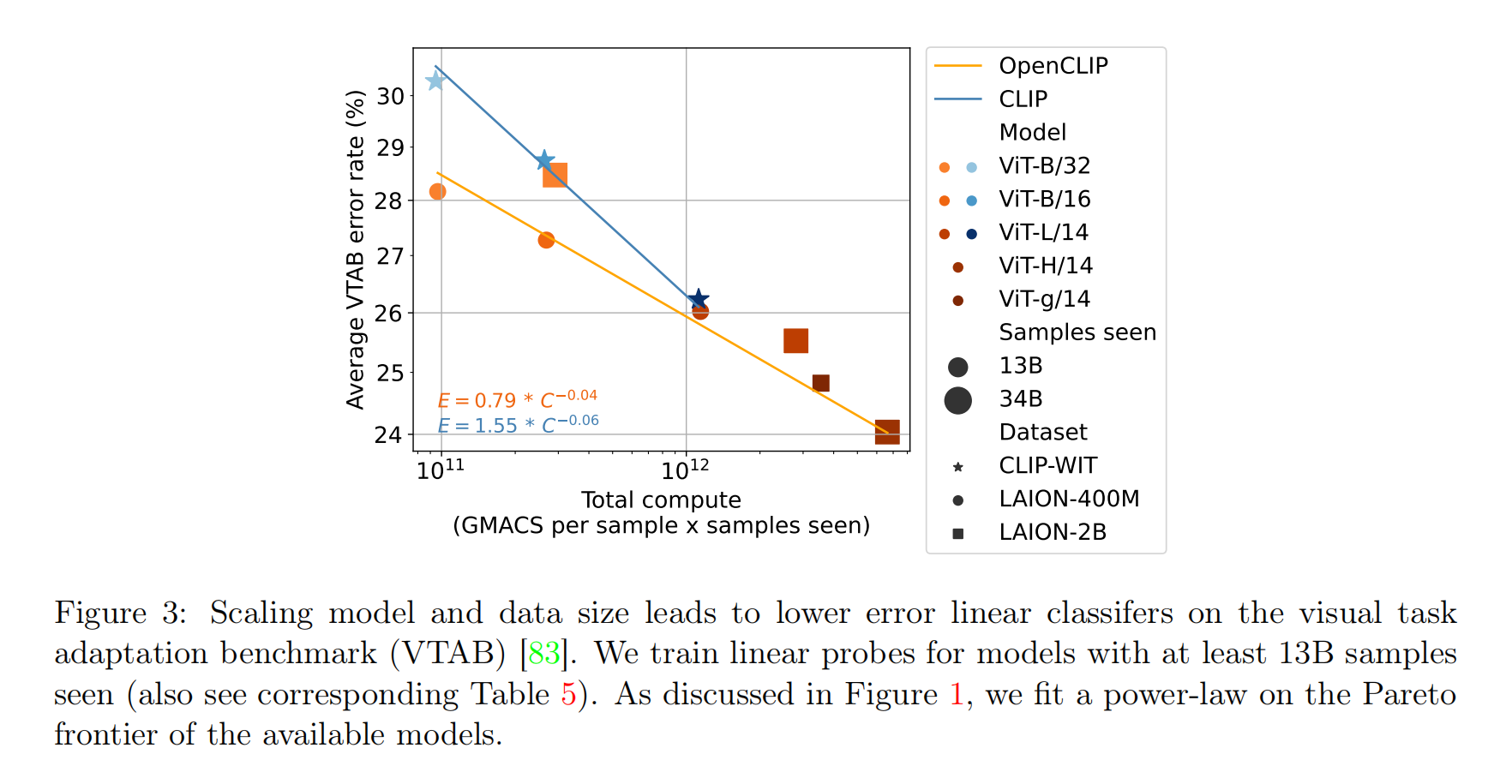
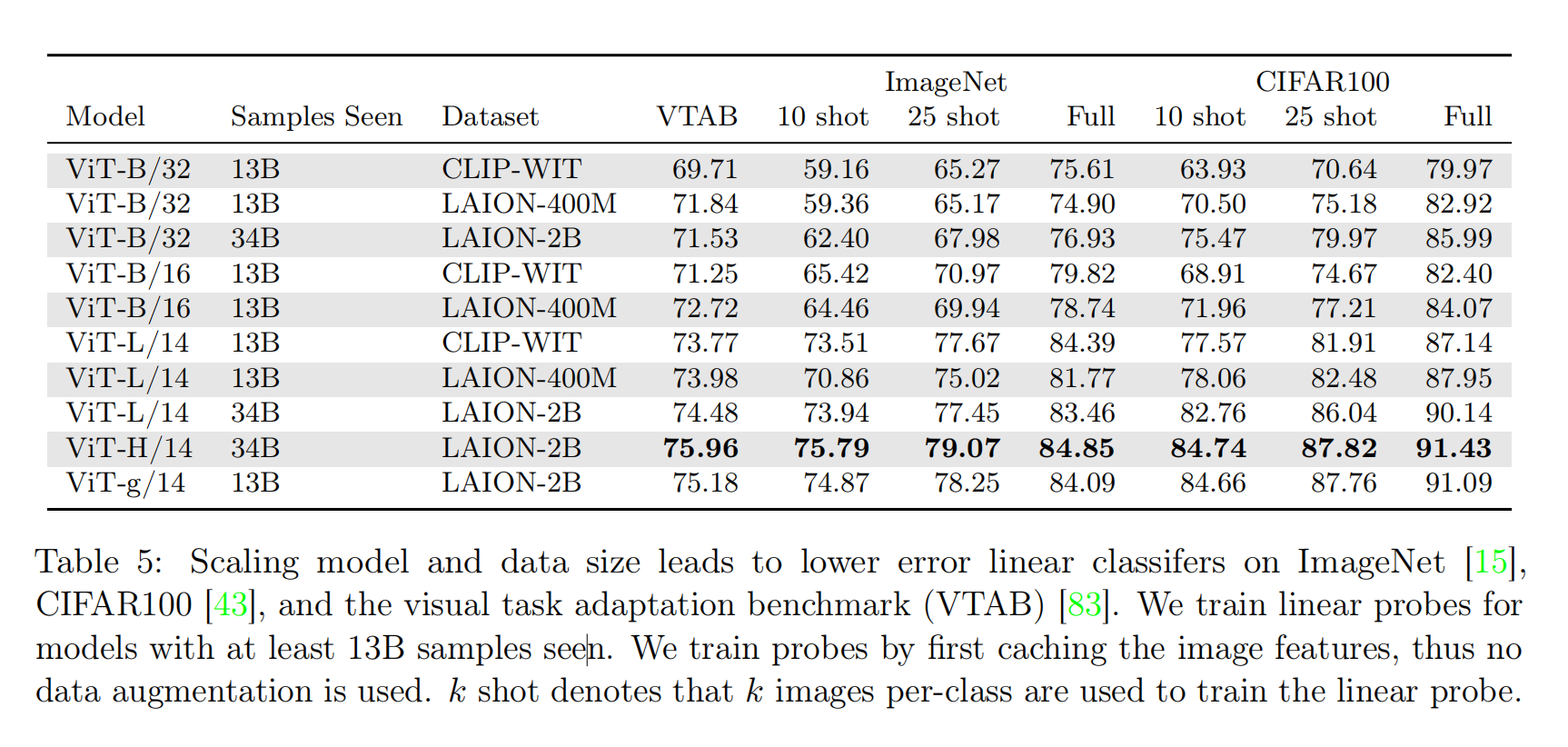
针对线性分类器微调任务,论文评估了ImageNet、CIFAR100和VTAB数据集,不论是单个类别固定数据量的训练方式,还是使用全部数据集参与训练的方式,都能够发现复合放大能够有效提升性能。
端到端微调
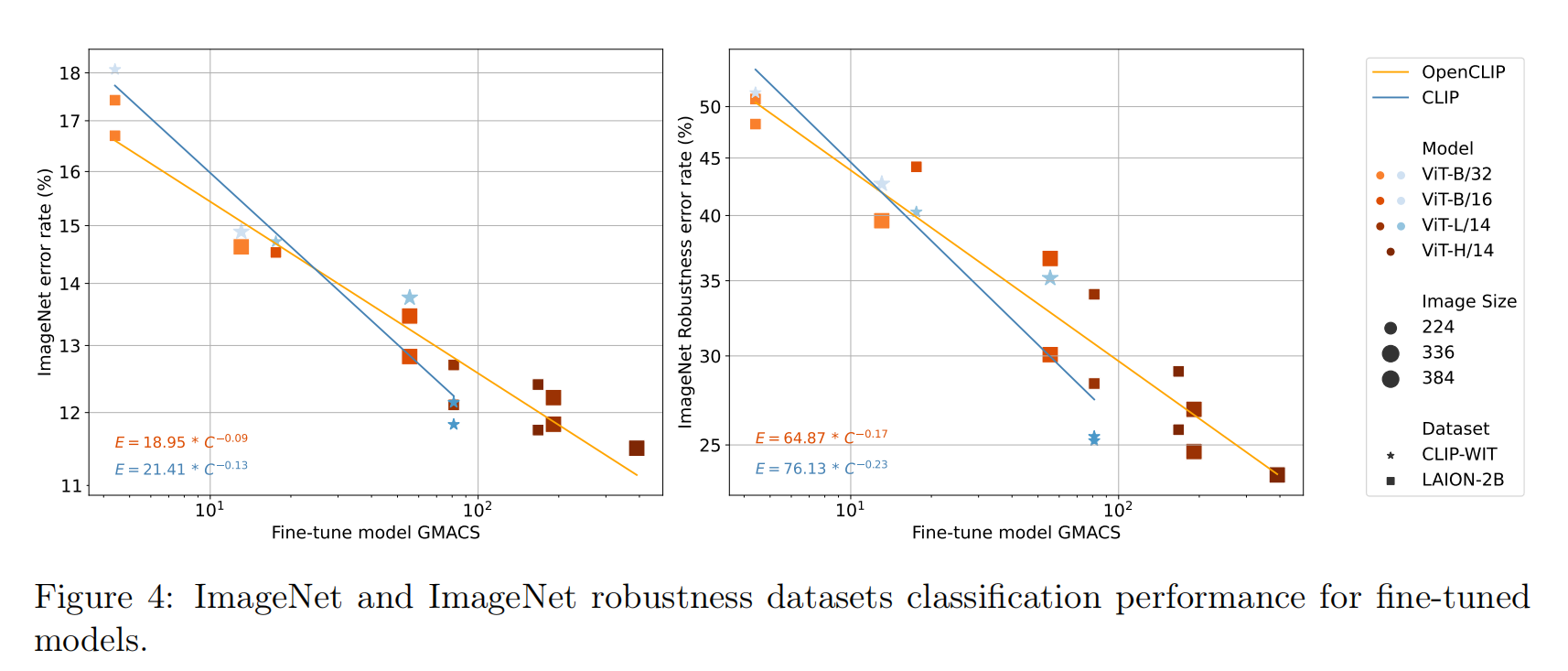
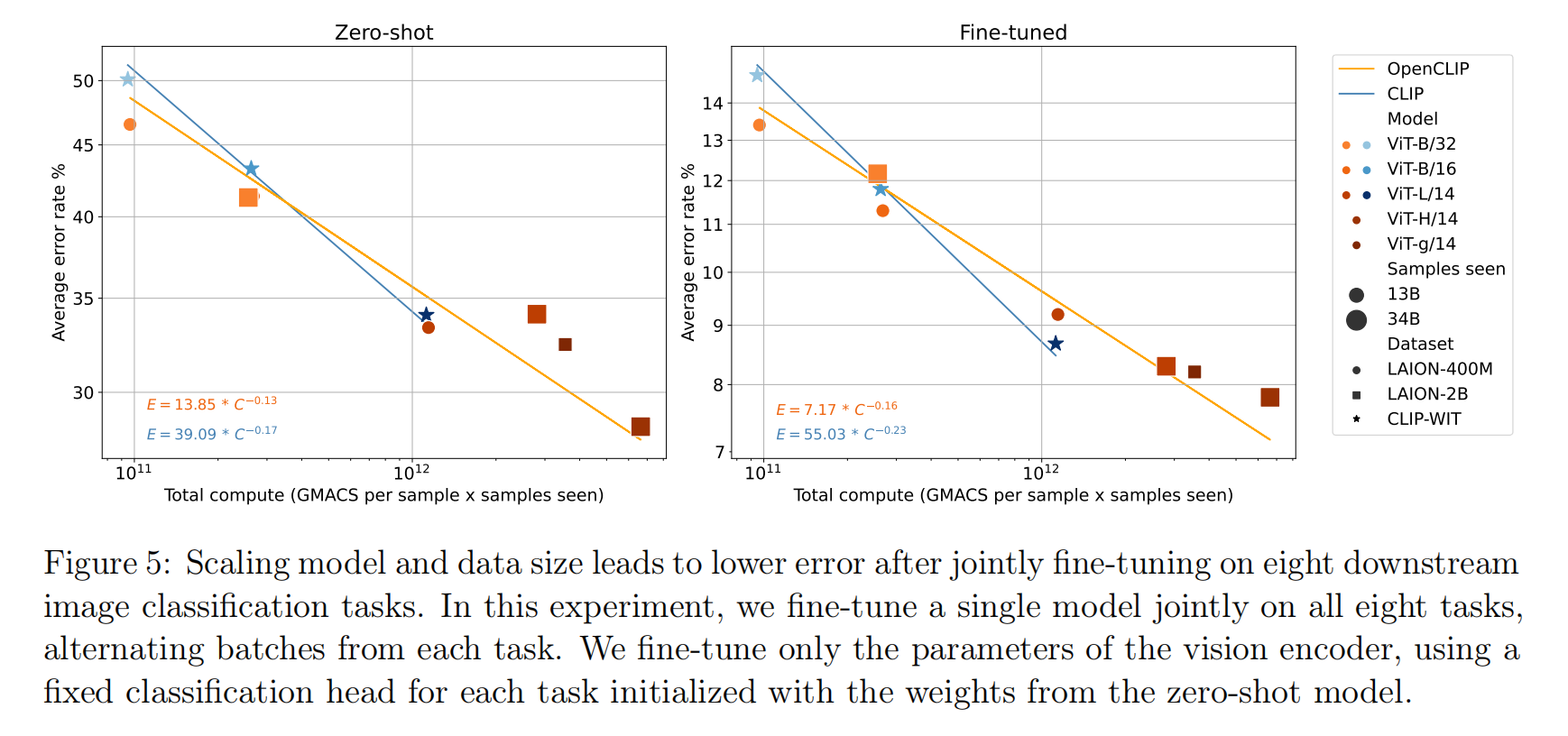
小结
开源是人类进步的加速器。OpenAI发布CLIP不久,就有组织构建了超大规模数据集LAION-5B,并且成功复现OpenCLIP算法。阅读这篇论文可以帮助我更好的理解多模态算法,RESPECT!!!
从OpenCLIP构建的实验中,可以发现多模态算法(目前指的是图像-文本领域)
- 存在缩放定律(
scaling laws in the form of power law),需要复合放大模型、数据集和训练数据量才能够更有效地提升算法性能; - 存在规模瓶颈效应(
scale bottleneck effect),必须提供足够的训练数据量,仅仅构建好模型和数据集并不能够得到最好的放大效果。这一点图像领域(比如目标分类/目标检测/目标分割)也发现了这个现象,最新的算法往往需要更多轮的训练; - 对于不同的下游任务,预训练数据集的来源和分布有很大的影响。我相信使用相同类型的数据集进行预训练,在下游任务肯定能够得到更好的效果,比如ChineseCLIP(使用中文图像-文本对数据集预训练,然后在下游的中文任务中进行测试)。