Chinese CLIP: Contrastive Vision-Language Pretraining in Chinese

摘要
The tremendous success of CLIP (Radford et al., 2021) has promoted the research and application of contrastive learning for vision-language pretraining. In this work, we construct a large-scale dataset of image-text pairs in Chinese, where most data are retrieved from publicly available datasets, and we pretrain Chinese CLIP models on the new dataset. We develop 5 Chinese CLIP models of multiple sizes, spanning from 77 to 958 million parameters. Furthermore, we propose a two-stage pretraining method, where the model is first trained with the image encoder frozen and then trained with all parameters being optimized, to achieve enhanced model performance. Our comprehensive experiments demonstrate that Chinese CLIP can achieve the state-of-the-art performance on MUGE, Flickr30K-CN, and COCO-CN in the setups of zero-shot learning and finetuning, and it is able to achieve competitive performance in zero-shot image classification based on the evaluation on the ELEVATER benchmark (Li et al., 2022). We have released our codes, models, and demos in https://github.com/OFA-Sys/Chinese-CLIP.
CLIP(Radford等人,2021)的巨大成功促进了对比学习在视觉-语言预训练领域的研究和应用。在本文中,我们构建了一个大规模中文图像-文本对数据集,其中大部分数据是从公开数据集检索得到,我们在这个新数据集上预训练了中文CLIP模型。我们开发了5个不同尺寸的中文CLIP模型,参数量从7700万到9.58亿不等。另外,我们提出一种两阶段预训练方法,首先是冻结图像编码器进行训练,然后进一步优化模型所有参数,这种方式能够有效提高模型性能。实验表明,中文CLIP预训练模型以零样本或者微调方式迁移到下游任务,在MUGE、Flickr30K-CN和COCO-CN上达到SOTA,在ELEVATER(Li et al.,2022)零样本图像分类测试也得到有竞争力的性能。代码、模型和DEMO已开源:https://github.com/OFA-Sys/Chinese-CLIP。
ChineseCLIP
ChineseCLIP是阿里达摩院出品的多模态大模型,通过构建大规模图像-文本对中文数据集,并且创新性的构造两阶段预训练方式来优化中文CLIP模型,在中文基准测试上比较CLIP算法有很大提升。
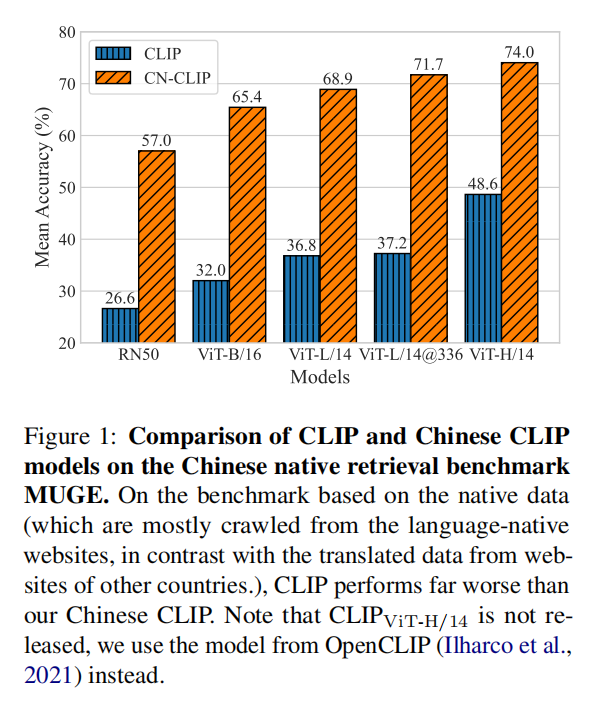
最后,论文开源了ChineseCLIP的训练代码和评估脚本,还提供多种部署方式,包括NVIDIA TensorRT和ONNX模型。

中文数据集
论文构造了大约2亿条图像-文本对中文数据集,从多个数据源采集得到,
- 从LAION-5B数据集中采集中文文本的图像-文本对,由于图片链接缺失,仅采集到1.08亿条;
- 从Wukong中文数据集采集,同样由于图片链接缺失,仅采集到7200万条(本身数据集有1亿条数据);
- 将英语多模态数据集翻译成中文,包括Visual Genome和MSCOCO(都移除了测试数据);
- 最后增加了2千万条阿里的内部数据。
论文还对采集到的数据进行了过滤,
- 针对LAION-5B,使用mCLIP过滤余弦相似度低于0.26的图像-文本对数据;
- 对于所有数据,移除出现阿里黑名单文本的数据,包括广告名、文件名等等;
- 移除文本长度太小(字符低于5个)或者太长(字符高于50个)的数据。
最后,论文将所有数据缩放至224x224大小,对于ViT-L/14@336px则缩放至336x336大小。
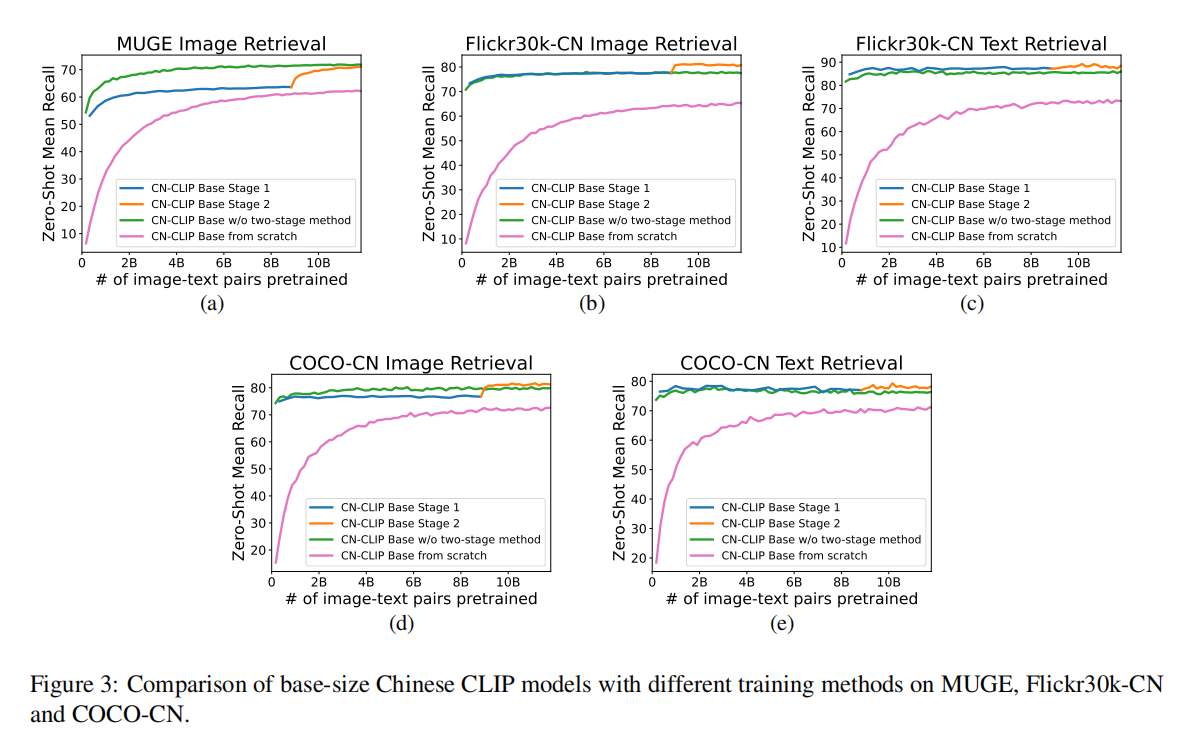
两阶段预训练
首先,使用CLIP预训练模型来初始化ChineseCLIP的图像编码器(image encoder),使用RoBERTa-wwm-Chinese来初始化文本编码器(text encoder)。然后
- 第一步训练(
LiT, Locked-image Tuning):冻结图像编码器,仅微调训练文本编码器; - 第二步训练:放开模型所有权重,微调训练图像编码器和文本编码器。
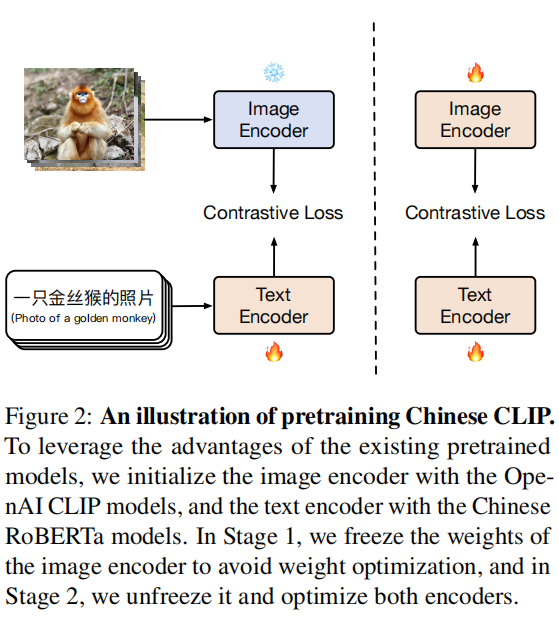
模型架构
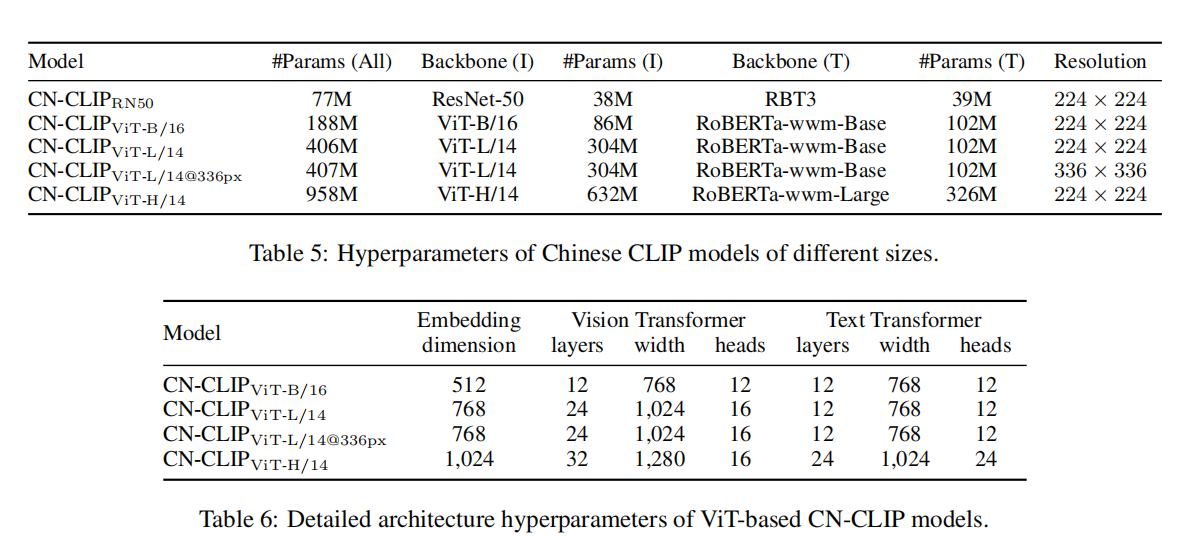
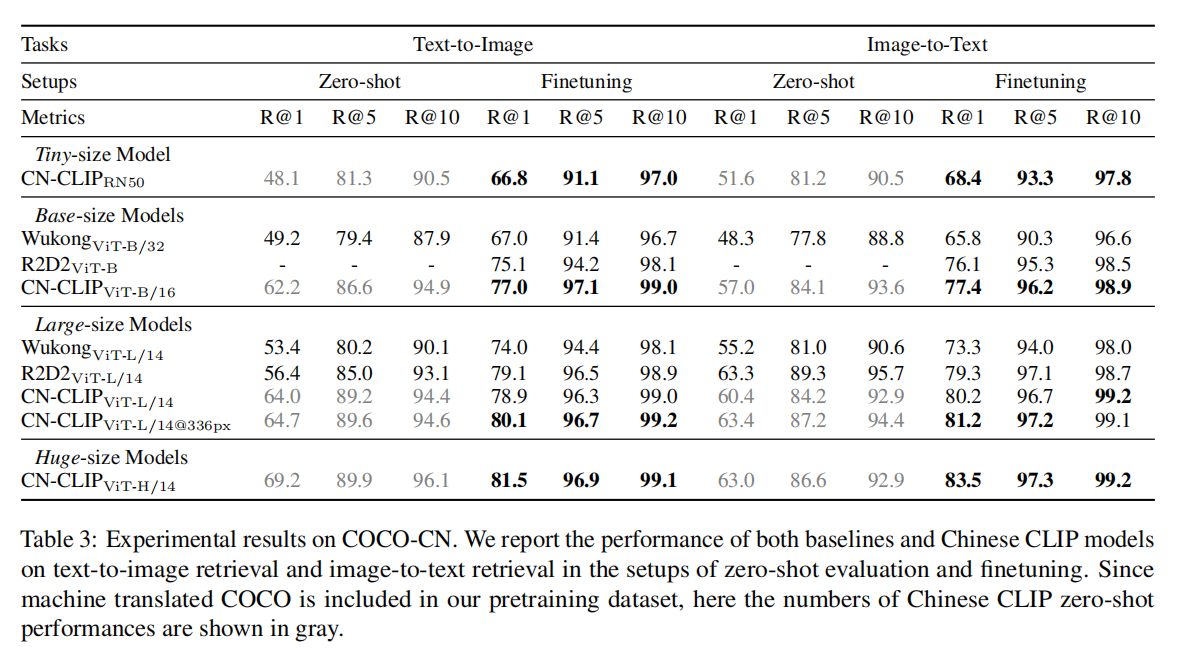
实验
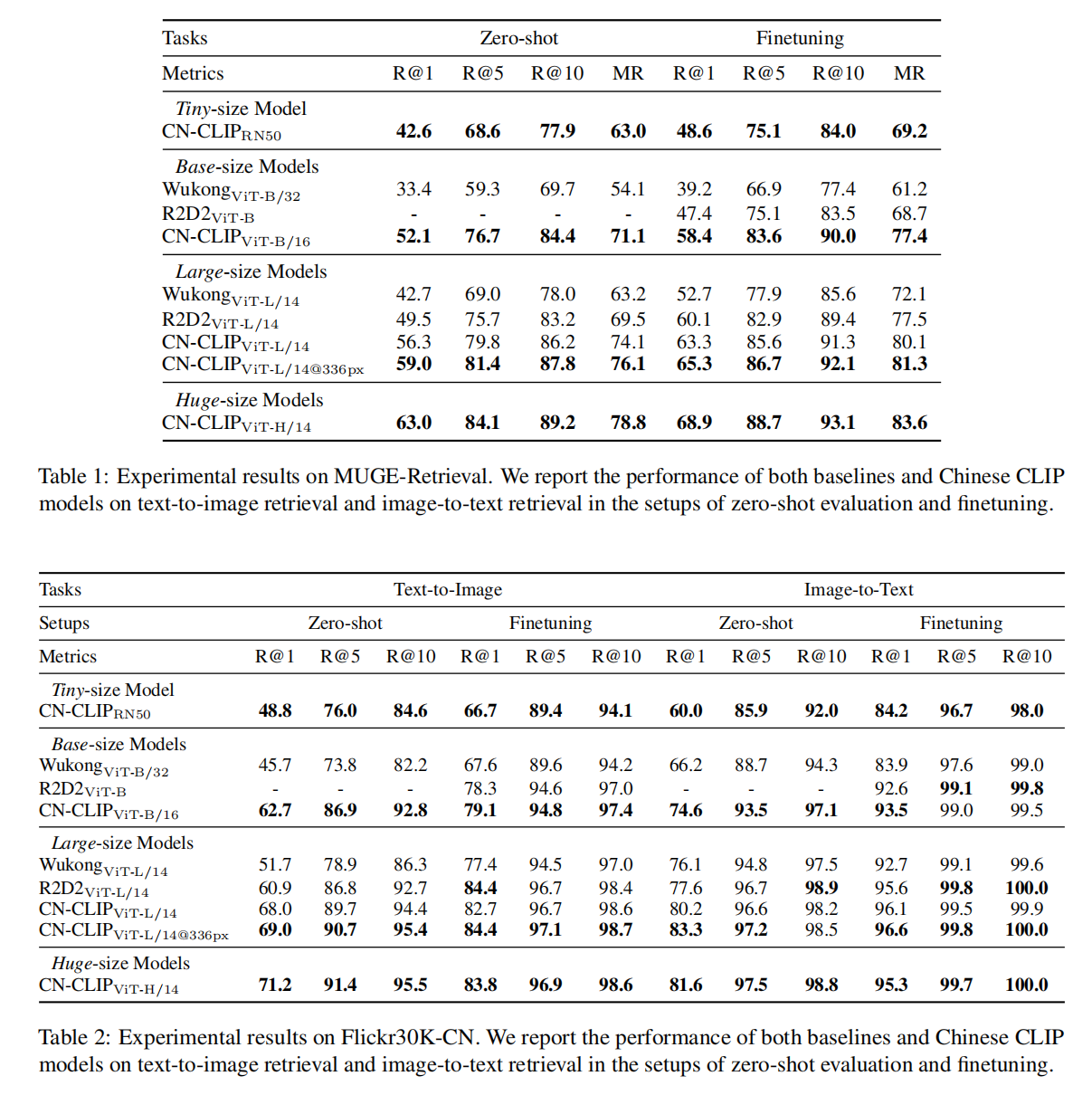
小结
指向性非常明显的一篇论文,就是中文版复刻CLIP算法,简单、粗暴、实用,在中文基准测试集上效果杠杠滴!
ChineseCLIP的出现证明了数据来源(不仅仅是数据规模)一定是CLIP算法能够零 样本或者微调方式迁移到下游任务的关键因素,这也说明CLIP算法才刚刚打开图像-文本多模态领域的大门,需要有更加强大的多模态算法来解决数据跨域导致的性能衰减问题。